5.6 The Gestalt Principles of Perception
Learning objectives.
By the end of this section, you will be able to:
- Explain the figure-ground relationship
- Define Gestalt principles of grouping
- Describe how perceptual set is influenced by an individual’s characteristics and mental state
In the early part of the 20th century, Max Wertheimer published a paper demonstrating that individuals perceived motion in rapidly flickering static images—an insight that came to him as he used a child’s toy tachistoscope. Wertheimer, and his assistants Wolfgang Köhler and Kurt Koffka, who later became his partners, believed that perception involved more than simply combining sensory stimuli. This belief led to a new movement within the field of psychology known as Gestalt psychology. The word gestalt literally means form or pattern, but its use reflects the idea that the whole is different from the sum of its parts. In other words, the brain creates a perception that is more than simply the sum of available sensory inputs, and it does so in predictable ways. Gestalt psychologists translated these predictable ways into principles by which we organize sensory information. As a result, Gestalt psychology has been extremely influential in the area of sensation and perception (Rock & Palmer, 1990).
Gestalt perspectives in psychology represent investigations into ambiguous stimuli to determine where and how these ambiguities are being resolved by the brain. They are also aimed at understanding sensory and perception as processing information as groups or wholes instead of constructed wholes from many small parts. This perspective has been supported by modern cognitive science through fMRI research demonstrating that some parts of the brain, specifically the lateral occipital lobe, and the fusiform gyrus, are involved in the processing of whole objects, as opposed to the primary occipital areas that process individual elements of stimuli (Kubilius, Wagemans & Op de Beeck, 2011).
One Gestalt principle is the figure-ground relationship. According to this principle, we tend to segment our visual world into figure and ground. Figure is the object or person that is the focus of the visual field, while the ground is the background. As the figure below shows, our perception can vary tremendously, depending on what is perceived as figure and what is perceived as ground. Presumably, our ability to interpret sensory information depends on what we label as figure and what we label as ground in any particular case, although this assumption has been called into question (Peterson & Gibson, 1994; Vecera & O’Reilly, 1998).


The concept of figure-ground relationship explains why this image can be perceived either as a vase or as a pair of faces.
Another Gestalt principle for organizing sensory stimuli into meaningful perception is proximity . This principle asserts that things that are close to one another tend to be grouped together, as the figure below illustrates.
The Gestalt principle of proximity suggests that you see (a) one block of dots on the left side and (b) three columns on the right side.
How we read something provides another illustration of the proximity concept. For example, we read this sentence like this, notl iket hiso rt hat. We group the letters of a given word together because there are no spaces between the letters, and we perceive words because there are spaces between each word. Here are some more examples: Cany oum akes enseo ft hiss entence? What doth es e wor dsmea n?
We might also use the principle of similarity to group things in our visual fields. According to this principle, things that are alike tend to be grouped together (figure below). For example, when watching a football game, we tend to group individuals based on the colors of their uniforms. When watching an offensive drive, we can get a sense of the two teams simply by grouping along this dimension.
When looking at this array of dots, we likely perceive alternating rows of colors. We are grouping these dots according to the principle of similarity.
Two additional Gestalt principles are the law of continuity (or good continuation) and closure. The law of continuity suggests that we are more likely to perceive continuous, smooth flowing lines rather than jagged, broken lines (figure below). The principle of closure states that we organize our perceptions into complete objects rather than as a series of parts (figure below).
Good continuation would suggest that we are more likely to perceive this as two overlapping lines, rather than four lines meeting in the center.
Closure suggests that we will perceive a complete circle and rectangle rather than a series of segments..
According to Gestalt theorists, pattern perception, or our ability to discriminate among different figures and shapes, occurs by following the principles described above. You probably feel fairly certain that your perception accurately matches the real world, but this is not always the case. Our perceptions are based on perceptual hypotheses: educated guesses that we make while interpreting sensory information. These hypotheses are informed by a number of factors, including our personalities, experiences, and expectations. We use these hypotheses to generate our perceptual set. For instance, research has demonstrated that those who are given verbal priming produce a biased interpretation of complex ambiguous figures (Goolkasian & Woodbury, 2010).
Template Approach
Ulrich Neisser (1967), author of one of the first cognitive psychology textbook suggested pattern recognition would be simplified, although abilities would still exist, if all the patterns we experienced were identical. According to this theory, it would be easier for us to recognize something if it matched exactly with what we had perceived before. Obviously the real environment is infinitely dynamic producing countless combinations of orientation, size. So how is it that we can still read a letter g whether it is capitalized, non-capitalized or in someone else hand writing? Neisser suggested that categorization of information is performed by way of the brain creating mental templates , stored models of all possible categorizable patterns (Radvansky & Ashcraft, 2014). When a computer reads your debt card information it is comparing the information you enter to a template of what the number should look like (has a specific amount of numbers, no letters or symbols…). The template view perception is able to easily explain how we recognize pieces of our environment, but it is not able to explain why we are still able to recognize things when it is not viewed from the same angle, distance, or in the same context.
In order to address the shortfalls of the template model of perception, the feature detection approach to visual perception suggests we recognize specific features of what we are looking at, for example the straight lines in an H versus the curved line of a letter C. Rather than matching an entire template-like pattern for the capital letter H, we identify the elemental features that are present in the H. Several people have suggested theories of feature-based pattern recognition, one of which was described by Selfridge (1959) and is known as the pandemonium model suggesting that information being perceived is processed through various stages by what Selfridge described as mental demons, who shout out loud as they attempt to identify patterns in the stimuli. These pattern demons are at the lowest level of perception so after they are able to identify patterns, computational demons further analyze features to match to templates such as straight or curved lines. Finally at the highest level of discrimination, cognitive demons which allow stimuli to be categorized in terms of context and other higher order classifications, and the decisions demon decides among all the demons shouting about what the stimuli is which while be selected for interpretation.
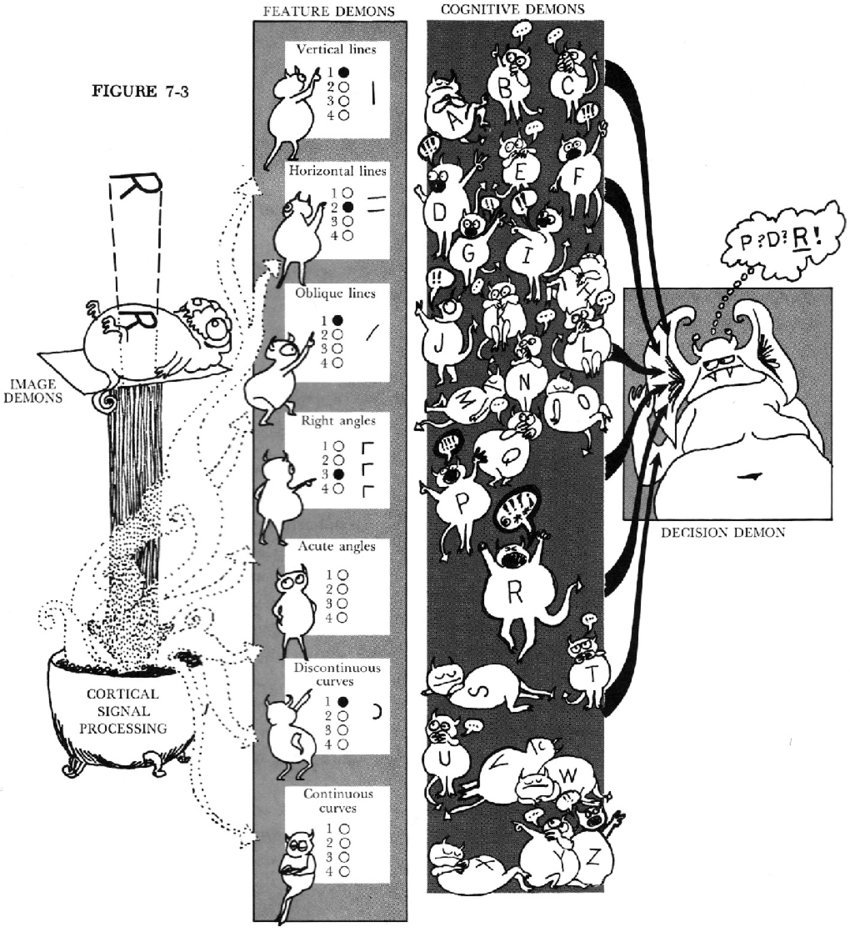
Selfridge’s pandemonium model showing the various levels of demons which make estimations and pass the information on to the next level before the decision demon makes the best estimation to what the stimuli is. Adapted from Lindsay and Norman (1972).
Although Selfridges ideas regarding layers of shouting demons that make up our ability to discriminate features of our environment, the model actually incorporates several ideas that are important for pattern recognition. First, at its foundation, this model is a feature detection model that incorporates higher levels of processing as the information is processed in time. Second, the Selfridge model of many different shouting demons incorporates ideas of parallel processing suggesting many different forms of stimuli can be analyzed and processed to some extent at the same time. Third and finally, the model suggests that perception in a very real sense is a series of problem solving procedures where we are able to take bits of information and piece it all together to create something we are able to recognize and classify as something meaningful.
In addition to sounding initially improbable by being based on a series of shouting fictional demons, one of the main critiques of Selfridge’s demon model of feature detection is that it is primarily a bottom-up , or data-driven processing system. This means the feature detection and processing for discrimination all comes from what we get out of the environment. Modern progress in cognitive science has argued against strictly bottom-up processing models suggesting that context plays an extremely important role in determining what you are perceiving and discriminating between stimuli. To build off previous models, cognitive scientist suggested an additional top-down , or conceptually-driven account in which context and higher level knowledge such as context something tends to occur in or a persons expectations influence lower-level processes.
Finally the most modern theories that attempt to describe how information is processed for our perception and discrimination are known as connectionist models. Connectionist models incorporate an enormous amount of mathematical computations which work in parallel and across series of interrelated web like structures using top-down and bottom-up processes to narrow down what the most probably solution for the discrimination would be. Each unit in a connectionist layer is massively connected in a giant web with many or al the units in the next layer of discrimination. Within these models, even if there is not many features present in the stimulus, the number of computations in a single run for discrimination become incredibly large because of all the connections that exist between each unit and layer.
The Depths of Perception: Bias, Prejudice, and Cultural Factors
In this chapter, you have learned that perception is a complex process. Built from sensations, but influenced by our own experiences, biases, prejudices, and cultures , perceptions can be very different from person to person. Research suggests that implicit racial prejudice and stereotypes affect perception. For instance, several studies have demonstrated that non-Black participants identify weapons faster and are more likely to identify non-weapons as weapons when the image of the weapon is paired with the image of a Black person (Payne, 2001; Payne, Shimizu, & Jacoby, 2005). Furthermore, White individuals’ decisions to shoot an armed target in a video game is made more quickly when the target is Black (Correll, Park, Judd, & Wittenbrink, 2002; Correll, Urland, & Ito, 2006). This research is important, considering the number of very high-profile cases in the last few decades in which young Blacks were killed by people who claimed to believe that the unarmed individuals were armed and/or represented some threat to their personal safety.
Gestalt theorists have been incredibly influential in the areas of sensation and perception. Gestalt principles such as figure-ground relationship, grouping by proximity or similarity, the law of good continuation, and closure are all used to help explain how we organize sensory information. Our perceptions are not infallible, and they can be influenced by bias, prejudice, and other factors.
References:
Openstax Psychology text by Kathryn Dumper, William Jenkins, Arlene Lacombe, Marilyn Lovett and Marion Perlmutter licensed under CC BY v4.0. https://openstax.org/details/books/psychology
Review Questions:
1. According to the principle of ________, objects that occur close to one another tend to be grouped together.
a. similarity
b. good continuation
c. proximity
2. Our tendency to perceive things as complete objects rather than as a series of parts is known as the principle of ________.
d. similarity
3. According to the law of ________, we are more likely to perceive smoothly flowing lines rather than choppy or jagged lines.
4. The main point of focus in a visual display is known as the ________.
b. perceptual set
Critical Thinking Question:
1. The central tenet of Gestalt psychology is that the whole is different from the sum of its parts. What does this mean in the context of perception?
2. Take a look at the following figure. How might you influence whether people see a duck or a rabbit?

Personal Application Question:
1. Have you ever listened to a song on the radio and sung along only to find out later that you have been singing the wrong lyrics? Once you found the correct lyrics, did your perception of the song change?
figure-ground relationship
Gestalt psychology
- good continuation
pattern perception
perceptual hypothesis
principle of closure
Key Takeaways
1. This means that perception cannot be understood completely simply by combining the parts. Rather, the relationship that exists among those parts (which would be established according to the principles described in this chapter) is important in organizing and interpreting sensory information into a perceptual set.
2. Playing on their expectations could be used to influence what they were most likely to see. For instance, telling a story about Peter Rabbit and then presenting this image would bias perception along rabbit lines.
closure: organizing our perceptions into complete objects rather than as a series of parts
figure-ground relationship: segmenting our visual world into figure and ground
Gestalt psychology: field of psychology based on the idea that the whole is different from the sum of its parts
good continuation: (also, continuity) we are more likely to perceive continuous, smooth flowing lines rather than jagged, broken lines
pattern perception: ability to discriminate among different figures and shapes
perceptual hypothesis: educated guess used to interpret sensory information
principle of closure: organize perceptions into complete objects rather than as a series of parts
proximity: things that are close to one another tend to be grouped together
similarity: things that are alike tend to be grouped together
Review Questions
According to the principle of ________, objects that occur close to one another tend to be grouped together.
Our tendency to perceive things as complete objects rather than as a series of parts is known as the principle of ________.
According to the law of ________, we are more likely to perceive smoothly flowing lines rather than choppy or jagged lines.
The main point of focus in a visual display is known as the ________.
- perceptual set
Critical Thinking Question
The central tenet of Gestalt psychology is that the whole is different from the sum of its parts. What does this mean in the context of perception?
Take a look at the following figure. How might you influence whether people see a duck or a rabbit?
Answer: Playing on their expectations could be used to influence what they were most likely to see. For instance, telling a story about Peter Rabbit and then presenting this image would bias perception along rabbit lines.
Personal Application Question
Have you ever listened to a song on the radio and sung along only to find out later that you have been singing the wrong lyrics? Once you found the correct lyrics, did your perception of the song change?

Share This Book
- Increase Font Size
Perception Psychology: Exploring Key Perception Theories
Perception is defined as “ the process or result of becoming aware of objects, relationships, and events by means of the senses, which includes such activities as recognizing, observing, and discriminating.” This process allows us to notice and then interpret stimuli and sensory input around us so we can understand and respond accordingly. While perception may seem simple, it’s actually a complex and highly individualized process with many psychological components and implications. Below, we’ll cover the basics of perception psychology along with a few of the leading theories on this topic.
How we sense the world around us, from auditory to visual perception
Let’s start with a brief overview of the basic mechanisms of direct perception, or the ways in which we’re able to perceive the world around us (i.e., through sensory receptors). Scientists now recognize seven senses that humans can use to gather information about our surroundings. These sense organs and systems allow us to recognize faces, notice smells, and respond to other stimuli:
Visual perception
Visual perception involves sight and the visual information perceived through the eyes. It enables us to understand and navigate our environment through visual cues.
Auditory perception
Auditory perception pertains to sounds or auditory signals perceived through the ears. It allows us to communicate and react to auditory stimuli in our surroundings.
Gustatory perception
Gustatory perception refers to the awareness of flavor and taste on the tongue. This sense helps us enjoy and discern different foods and beverages.
Olfactory perception
Olfactory perception involves smelling via the nose. It plays a crucial role in detecting odors and contributing to the sense of taste.
Tactile perception
Tactile perception is the awareness of sensation on the skin. It helps us feel touch, pressure, temperature, and pain, providing essential feedback about our environment.
Vestibular sense
The vestibular sense is the perception of balance and motion or physical energy. It helps us maintain equilibrium and coordinate movements.
Proprioception
Proprioception provides the perceptual context of the body’s position in space. It allows us to perform tasks with precision by understanding the relative position of our body parts.
The psychology of what the perception process involves in our brain
Perception psychology is a division of cognitive psychology that studies how humans receive and understand the information delivered through the senses—also known as the perceptual experience. As mentioned above, perception processes include a network of bodily systems and sense organs that receive information and then process it. As we interact with the physical world, our brains interpret this information to make sense of what we experience.
Our brains also automatically attempt to group perceptions to help us understand and interpret our world. There are six main principles of the sensory systems the human mind uses to organize what it perceives:
- Similarity, or grouping things that look like each other. Items with the same shape, size, and/or color make up parts of perceived patterns that appear to belong together.
- Proximity, or grouping things according to how physically close they are to each other. The closer together they are, the more likely the brain will identify them as a group—even if they don’t have any connection to each other.
- Continuity, or the tendency to perceive individual elements and other objects as a whole rather than a series of parts
- Inclusiveness, or perceiving all elements of an image before recognizing the parts of it. For example, you may sense one object—a car—before recognizing the color, make, or who is inside.
- Closure, or seeing a partial image or ambiguous picture and filling in the gaps of what you believe should be there. This ability allows one to overlook a partial understanding and perceive the situation in its entirety, despite missing information.
- Prägnanz, or the tendency to simplify complex stimuli into a simple pattern. An example is using visual systems to look at a complex building and being aware of where the front door is while not registering the structure’s many other features.
Main theories on the psychology of the perception experience
Psychologists and researchers continue to explore the nuances of this complex field. As of today, here’s a brief overview of some of the key perception psychology theories out there. Note that none of these completely explains the process in every instance; this field of study is ongoing.
Perception psychology according to Bruner
Jerome S. Bruner was an American psychologist who theorized that people go through various processes before they form opinions about what they have observed. According to Bruner, people use different informational cues to ultimately define their perceptions. This information-seeking continues until the individual comes across a familiar part and the mind categorizes it. If signals are distorted or do not fit a person’s initial perceptions, the images are forgotten or ignored while a picture forms on the most familiar perceptions.
Perception psychology according to Gibson
James J. Gibson is another American psychologist who studied perception psychology. Gibson is known for his philosophy of the direct theory of visual perception in particular, also called the “bottom-up” processing theory. He believed we can explain visual perception solely in terms of the environment, beginning with a sensory stimulus. In each stage of the perceptual processes, the eyes send signals to the brain to continue analyzing—from the bottom up—until it can conclude what the person is seeing.
Gibson theorized that the starting point of the bottom-up process of visual perception begins with the pattern of light that reaches our eyes. These signals then form the basis of our understanding of perceptions because they convey unambiguous information about the spatial layout we perceive. He further defined perception according to what he called affordances. He identified six affordances of perception, including:
Optical array: the patterns of light that travel from the environment to the eyes
Relative brightness: the perception that brighter, more evident objects are closer than darker, out-of-focus objects
Texture gradient: The grain of texture becomes less defined as an object recedes, indicating that the object may be further in the distance.
Relative size: Objects that are farther away will appear smaller.
Superimposition: When one image partially blocks another, the viewer sees the first image as being closer to them. Superimposition is similar to inattentional blindness , in which the eyes cannot see an object because another object fully engages them.
Height in the visual field: Objects that are further away from the viewer typically appear higher in the visual field.
Perception psychology, according to Gregory
Richard Langton Gregory was a British psychologist and Emeritus Professor of Neuropsychology at the University of Bristol. Gregory was also the author of the constructivist theory of perception, or the "top-down" processing theory—which takes the opposite approach of Gibson’s “bottom-up” theory. It assumes that our cognitive processes—including memory and perception—result from our continuously generating hypotheses about the world from the top down. In other words, we recognize patterns by understanding the context in which we perceive them.
Consider handwriting as an example. The handwriting of many individuals can be difficult for others to read; however, if we can pick out a few words here or there, it helps us understand the text’s context, and that helps us figure out the words we could not read. In other words, Gregory's theory assumes we have previous knowledge of what we are perceiving in addition to the stimulus itself. Because stimuli can often be ambiguous, correctly perceiving them requires a higher level of cognition because we must draw from stored knowledge or past experiences to help us understand our perceptions. He believed perception is based on our accumulated knowledge and that we actively construct perceptions whether they’re correct or not—though an incorrect hypothesis can lead to errors in perception.
Exploring how thoughts affect perception with a therapist
The way we perceive objects, individuals, events, and our environment can have a significant impact on our mood, emotions, and behaviors. In some cases, our perceptions can be distorted, which can lead to distressing feelings or even symptoms of a mental health condition like depression or anxiety. Talk therapy— cognitive behavioral therapy (CBT) in particular—is one way to learn how to recognize any cognitive distortions you may be experiencing and shift your thoughts in a more realistic, balanced, and healthy direction.
Regularly attending in-person therapy sessions is not possible for everyone. Some may not have adequate provider options in their area, while others may have trouble commuting to and from in-office sessions. In cases like these, online therapy can represent a viable alternative. A platform like BetterHelp can match you with a licensed therapist who you can meet with via video, phone, and/or in-app messaging, all from the comfort of home. Research suggests that virtual therapy is “no less efficacious” than the in-person variety in many cases, so you can generally feel confident in selecting whichever format may work best for you.
What are examples of perception psychology?
Some examples of types of perception include taste perception, such as being able to identify various flavors in what you’re eating, or visual perception, such as being able to identify and distinguish between a rock, a tree, and a flower.
What is the simple definition of perception?
The simple, specific meaning of perception is how we use our five senses—plus our senses of balance and our perception of our own body position—to experience the world around us. Perception involves actions like seeing, touching, tasting, and smelling in order to take in our surroundings and then using automatic neural processing to make sense of them.
What are the 4 stages of perception?
The perception process involves four basic stages. First, the individual is exposed to a stimulus through their environment and becomes aware of it through one or more of their perception skills, or senses. Second, their brain registers the stimulus based on the information gathered through the sense(s). Next, the information is organized based on a person’s existing knowledge and beliefs. Finally, the person interprets the stimulus based on their own knowledge and beliefs, such as a good or bad smell, a dangerous or non-dangerous animal, a pleasant or grating sound, etc.
What is perceptual psychology simple?
Perceptual psychology is made up of various theories from studies over the years about why and how we take in information from the environments around us and perceive things in a certain way. There are many elements that go into why a person may perceive something the way they do, such as existing knowledge, beliefs, culture, and even mental health. Perceptual psychologists study these unconscious processes that contribute to a person’s perception.
What are 4 examples of perception?
Perception refers to how we see and make sense of the world around us. Four examples include seeing a sunset, smelling a fragrant flower, hearing music playing, and touching a soft blanket.
What is an example of perception in human behavior?
Perception is how our sensory organs detect or perceive stimuli in our surroundings. An example of perception as it relates to human behavior is two people seeing a dog and reacting differently based on their past experiences, knowledge, and beliefs. One might react in fear because they were chased by a dog as a child or in disgust because they think all dogs smell bad. The other might react in excitement and go to interact with the dog because they have a beloved dog of their own at home.
What is an example of the psychological perception effect?
There are several different perception effects the human mind uses to categorize, organize, and make sense of the world, and of which we are typically not consciously aware. For example, we’re likely to unconsciously group things that resemble each other—such as objects of the same shape, size, or color—because our brain tells us that they belong together.
What are the 3 factors that influence perception?
There are many different factors that can affect perception, so much so that the field of perception psychology, a type of social psychology, is devoted to examining and understanding them. A few examples of factors that could influence the way an individual perceives something include past experiences, prior knowledge, and cultural values.
What is an example of perception and personality?
The way we perceive words and sounds, sights, smells, tastes, and other forms of stimuli is influenced by our personality. For example, the words one person perceives through auditory signals and then interprets to find offensive may be welcomed by another due to a natural tendency toward humor, optimism/pessimism, etc.
Why is it important to perceive sensory stimuli?
Overall, perception is our ability to identify stimuli in the world around us and interpret it according to our own values, personality, culture, and other factors. It’s important because it’s the means through which we sense and then interpret the world around us.
- Extinction Psychology Medically reviewed by Arianna Williams , LPC, CCTP
- Transpersonal Psychology: A Path To Holistic Transformation Medically reviewed by April Justice , LICSW
- Psychologists
- Relationships and Relations
Perceptual Set In Psychology: Definition & Examples
Saul McLeod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul McLeod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Perceptual set in psychology refers to a mental predisposition or readiness to perceive stimuli in a particular way based on previous experiences, expectations, beliefs, and context. It influences how we interpret and make sense of sensory information, shaping our perception and understanding of the world.
Perceptual set theory stresses the idea of perception as an active process involving selection, inference, and interpretation (known as top-down processing ).
The concept of perceptual set is important to the active process of perception. Allport (1955) defined perceptual set as:
“A perceptual bias or predisposition or readiness to perceive particular features of a stimulus.”
Perceptual set is a tendency to perceive or notice some aspects of the available sensory data and ignore others. According to Vernon, 1955 perceptual set works in two ways:
- The perceiver has certain expectations and focuses attention on particular aspects of the sensory data: This he calls a Selector”.
- The perceiver knows how to classify, understand and name selected data and what inferences to draw from it. This she calls an “Interpreter”.
It has been found that a number of variables, or factors, influence perceptual set, and set in turn influences perception. The factors include:
• Expectations • Emotion • Motivation • Culture
Expectation and Perceptual Set
(a) Bruner & Minturn (1955) illustrated how expectation could influence set by showing participants an ambiguous figure “13” set in the context of letters or numbers e.g.

The physical stimulus “13” is the same in each case but is perceived differently because of the influence of the context in which it appears. We EXPECT to see a letter in the context of other letters of the alphabet, whereas we EXPECT to see numbers in the context of other numbers.
(b) We may fail to notice printing/writing errors for the same reason. For example:
1. “The Cat Sat on the Map and Licked its Whiskers”.

(a) and (b) are examples of interaction between expectation and past experience.
(c) A study by Bugelski and Alampay (1961) using the “rat-man” ambiguous figure also demonstrated the importance of expectation in inducing set. Participants were shown either a series of animal pictures or neutral pictures prior to exposure to the ambiguous picture. They found participants were significantly more likely to perceive the ambiguous picture as a rat if they had had prior exposure to animal pictures.

Motivation / Emotion and Perceptual Set
Allport (1955) has distinguished 6 types of motivational-emotional influence on perception:
(i) bodily needs (e.g. physiological needs) (ii) reward and punishment (iii) emotional connotation (iv) individual values (v) personality (vi) the value of objects.
(a) Sandford (1936) deprived participants of food for varying lengths of time, up to 4 hours, and then showed them ambiguous pictures. Participants were more likely to interpret the pictures as something to do with food if they had been deprived of food for a longer period of time.
Similarly Gilchrist & Nesberg (1952), found participants who had gone without food for the longest periods were more likely to rate pictures of food as brighter. This effect did not occur with non-food pictures.
(b) A more recent study into the effect of emotion on perception was carried out by Kunst- Wilson & Zajonc (1980). Participants were repeatedly presented with geometric figures, but at levels of exposure too brief to permit recognition.
Then, on each of a series of test trials, participants were presented a pair of geometric forms, one of which had previously been presented and one of which was brand new. For each pair, participants had to answer two questions: (a) Which of the 2 had previously been presented? ( A recognition test); and (b) Which of the two was most attractive? (A feeling test).
The hypothesis for this study was based on a well-known finding that the more we are exposed to a stimulus, the more familiar we become with it and the more we like it. Results showed no discrimination on the recognition test – they were completely unable to tell old forms from new ones, but participants could discriminate on the feeling test, as they consistently favored old forms over new ones. Thus information that is unavailable for conscious recognition seems to be available to an unconscious system that is linked to affect and emotion.
Culture and Perceptual Set

Elephant drawing split-view and top-view perspective. The split elephant drawing was generally preferred by African children and adults .
(a) Deregowski (1972) investigated whether pictures are seen and understood in the same way in different cultures. His findings suggest that perceiving perspective in drawings is in fact a specific cultural skill, which is learned rather than automatic. He found people from several cultures prefer drawings which don”t show perspective, but instead are split so as to show both sides of an object at the same time.
In one study he found a fairly consistent preference among African children and adults for split-type drawings over perspective-drawings. Split type drawings show all the important features of an object which could not normally be seen at once from that perspective. Perspective drawings give just one view of an object. Deregowski argued that this split-style representation is universal and is found in European children before they are taught differently.
(b) Hudson (1960) noted difficulties among South African Bantu workers in interpreting depth cues in pictures. Such cues are important because they convey information about the spatial relationships among the objects in pictures. A person using depth cues will extract a different meaning from a picture than a person not using such cues.
Hudson tested pictorial depth perception by showing participants a picture like the one below. A correct interpretation is that the hunter is trying to spear the antelope, which is nearer to him than the elephant. An incorrect interpretation is that the elephant is nearer and about to be speared. The picture contains two depth cues: overlapping objects and known size of objects. Questions were asked in the participants native language such as:
What do you see? Which is nearer, the antelope or the elephant? What is the man doing?
The results indicted that both children and adults found it difficult to perceive depth in the pictures.

The cross-cultural studies seem to indicate that history and culture play an important part in how we perceive our environment. Perceptual set is concerned with the active nature of perceptual processes and clearly there may be a difference cross-culturally in the kinds of factors that affect perceptual set and the nature of the effect.
Allport, F. H. (1955). Theories of perception and the concept of structure . New York: Wiley.
Bruner, J. S. and Minturn, A.L. (1955). Perceptual identification and perceptual organisation, Journal of General Psychology 53: 21-8.
Bugelski, B. R., & Alampay, D. A., (1961). The role of frequency in developing perceptual sets. Canadian Journal of Psychology , 15, 205-211.
Deregowski, J. B., Muldrow, E. S. & Muldrow, W. F. (1972). Pictorial recognition in a remote Ethiopian population. Perception , 1, 417-425.
Gilchrist, J. C.; Nesberg, Lloyd S. (1952). Need and perceptual change in need-related objects. Journal of Experimental Psychology , Vol 44(6).
Hudson, W. (1960). Pictorial depth perception in sub-cultural groups in Africa. Journal of Social Psychology , 52, 183-208.
Kunst- Wilson, W. R., & Zajonc, R. B. (1980). Affective discrimination of stimuli that cannot be recognised. Science , Vol 207, 557-558.
Necker, L. (1832). LXI. Observations on some remarkable optical phenomena seen in Switzerland; and on an optical phenomenon which occurs on viewing a figure of a crystal or geometrical solid . The London and Edinburgh Philosophical Magazine and Journal of Science, 1 (5), 329-337.
Sanford, R. N. (1936). The effect of abstinence from food upon imaginal processes: a preliminary experiment. Journal of Psychology: Interdisciplinary and Applied , 2, 129-136.
Vernon, M. D. (1955). The functions of schemata in perceiving. Psychological Review , Vol 62(3).
Why people should be skeptical when evaluating the accuracy of their perceptual set?
People should be skeptical when evaluating the accuracy of their perceptual set because it can lead to biased and subjective interpretations of reality. It can limit our ability to consider alternative perspectives or recognize new information that challenges our beliefs. Awareness of our perceptual sets and actively questioning them allows for more open-mindedness, critical thinking, and a more accurate understanding of the world.
The Common Kind Theory and The Concept of Perceptual Experience
- Original Research
- Published: 25 October 2021
- Volume 88 , pages 2847–2865, ( 2023 )
Cite this article

- Neil Mehta ORCID: orcid.org/0000-0002-6207-6778 1
251 Accesses
Explore all metrics
In this paper, I advance a new hypothesis about what the ordinary concept of perceptual experience might be. To a first approximation, my hypothesis is that it is the concept of something that seems to present mind-independent objects. Along the way, I reveal two important errors in Michael Martin’s argument for the very different view that the ordinary concept of perceptual experience is the concept of something that is impersonally introspectively indiscriminable from a veridical perception. This conceptual work is significant because it provides three pieces of good news for the common kind theorist.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

Property-Awareness and Representation
Phenomenal character and the epistemic role of perception, perceptual objectivity and the limits of perception.
Martin ( 2004 , p. 37).
I will be focusing on Martin’s most detailed presentation of the argument, which is in his (2004, pp. 47–52). But see also Martin ( 2006 ), which briefly revisits parts of this argument.
The common kind theory has so many advocates that it would be tedious to cite them all. Still, for some paradigms, see Tye ( 1995 ), Schellenberg ( 2018 ).
The notion of a fundamental kind has been developed in several subtly different ways. See for example Martin ( 2006 , pp. 360–361), Brewer ( 2011 , p. 3), Logue ( 2012 b, p. 174) and ( 2013 , p. 109).
Metaphysical disjunctivists (or those who accept some nearby view) include Hinton ( 1967 ), Campbell ( 2002 ), Martin ( 2004 ) and ( 2006 ), Snowdon ( 2005 ), Fish ( 2009 ), Nudds ( 2009 ), Brewer ( 2011 ), Logue ( 2012 ), Allen ( 2015 ), Genone ( 2016 ), Miracchi ( 2017 ), Moran ( 2018 ), French and Gomes ( 2019 ). For a bracingly clear overview of different forms of metaphysical disjunctivism, see Soteriou ( 2016 ).
I use the expressions reasonably natural property and natural kind in the sense of Lewis ( 1983 ).
I use the term “entity” as an especially broad sortal that includes properties, objects, events, states, etc.
Martin dubs this the “immodest view” (2004, pp. 47–48). However, since this is precisely the view that I wish to defend, I prefer the less prejudicial label given above. In addition, Martin does not speak of just one property E ; he speaks of a whole host of properties E 1 … E n . But you can think of E as the conjunction of E 1 … E n .
For a few advocates of the common kind theory, see fn. 3.
For advocates of metaphysical disjunctivism, see fn. 5.
Again, see Martin ( 2004 , pp. 75–76) and ( 2006 , §5). Martin takes inspiration from Hinton ( 1967 ). I have departed from Martin’s presentation in a few minor ways, however. First, Martin dubs this the “modest view,” but I will argue that there is nothing particularly modest about it; thus I prefer the more informative label given in the text. Second, Martin inquires into the ordinary concept of a perceptual experience of a street scene , but for our purposes I find it more helpful to inquire more generally into the ordinary concept of perceptual experience .
See Martin ( 2004 , pp. 74–81) and ( 2006 , pp. 379–96).
Martin ( 2004 , p. 49).
Ibid, p. 50.
Ibid, p. 49.
Ibid, pp. 49–50.
Ibid, p. 51.
I thank my undergraduate student Xianda Wen for the astute observation that seemings are sometimes inconsistent.
I owe this concern to an anonymous referee.
Martin ( 2004 , pp. 50–51).
Ibid, pp. 50–51.
At least, assuming that some perceptual experiences exist. (Otherwise there are no events that instantiate E , so telling whether or not an event instantiates these properties might turn out to be very easy).
Martin ( 2004 , pp. 51–52).
See their (2008, p. 75).
Ibid, p. 78.
I thank an anonymous referee for this suggestion.
My objection presupposes that sensations are not perceptual experiences. Can Martin reinstate his argument by denying this? Perhaps—but at this point in the dialectic, the onus is on him to defend this claim. He does not do so.
See Martin ( 2004 , pp. 37–38).
See Siegel ( 2004 , p. 94). For a response, see Martin ( 2004 , pp. 80–81). For what it is worth, I believe that Martin’s response does not handle all of the problematic cases.
See Siegel ( 2008 , pp. 218–223). For responses, see Nudds ( 2009 , pp. 342–343); Soteriou ( 2016 , ch. 6).
See Sturgeon ( 2008 , p. 134). For a response, see Nudds ( 2009 , p. 342).
See Siegel ( 2008 , pp. 211–214). For a response, see Nudds ( 2009 , pp. 342–343). For the record, I believe that Siegel’s objection is correct.
This phenomenon is well-known, though it has been called many different things—Millar ( 2014 , p. 240) gives an especially perspicuous description of it under the heading of object-immediacy . For other influential descriptions of this phenomenon, see Broad ( 1952 , p. 6); Alston ( 1999 , p. 182); Sturgeon ( 2000 , p. 9); Martin ( 2002 , p. 413); Levine ( 2006 , p. 179); and Brewer ( 2011 , p. 2).
For more discussion of these matters, see Mackie ( 2019 ).
As an anonymous referee observes, this view is by no means irresistible. Another option is to say that perceptual experiences and sensations both simply seem to present objects (while remaining silent on their mind-independence); perhaps perceptual experiences and sensations even belong to the same fundamental kind. If this is right, then we might instead consider:
The variant presentational semantic view : It is a conceptual truth that what it is to be a perceptual experience or sensation is to seem to present objects. (The property of seeming to present objects is thus experience-grounding.) In addition, this property is introspectible, and it is not perception-dependent. For the sake of simplicity, however, I will continue to work with the view in the text.
See Bayern et al. ( 2018 ).
Notice that, on this view, seeming (or purporting ) to present mind-independent objects does not require concept-possession, but introspectively seeming to present such objects does require concept-possession.
For the record, I am not just being coy here: I am not a representationalist. I prefer a pluralist theory of perception, one that blends certain elements of naïve realism and representationalism. See Mehta ( ms ).
Some would reject this last claim. For instance, some will think that veridical perceptions do not seem to present mind-independent objects, but just objects, simpliciter . I discuss this idea in more detail in fn. 40.
This is not quite right, since it is possible to hallucinate an impossible object such as an Escher staircase. But, borrowing an idea from Martin ( 2004 , pp. 80–81), the objection could be reformulated into something like this: surely what it is to seem to present mind-independent objects is just to be exhaustively decomposable into parts that each seem to be perceptions. I will ignore this nuance in what follows.
This seeming is not introspective, so we can still allow that a perception might introspectively seem to present mind- dependent objects. Again, this is one way to understand the case in which the subject mistakes a perception of a faint ringing sound for a ringing sensation.
It is worth mentioning an alternative approach. We might say that what it is to be a perceptual experience is to seem to present external (rather than mind-dependent) objects (see fn. 40); that what it is to be a perception is in fact to present external objects; and that what it is to be a sensation is in fact to present internal objects. Perhaps hallucinations are a subclass of sensations—the ones that in fact present internal objects but seem to present external objects. This approach can allow that some perceptions present, and correctly seem to present, objects that are external but mind-dependent. So this approach lets us reject the biconditional claim that something seems to present mind-independent objects just in case it seems to be a perception. The approach can also allow us to say that perceptions and sensations can be introspectively mistaken for one another, since the seemings invoked in the account are not introspective.
Some experiences might seem to present mind-independent objects and mind-dependent ones. How would I account for these? I would say that they are mixtures of perceptual experiences and sensations. (It is not surprising to posit mixed experiences. It is for instance entirely possible to mix perceptual experiences and imaginative ones, by imagining coffee in a cup that I see to be empty.) However, another option is to say that it is possible to perceive , in an unmixed way, mind-independent objects and mind-dependent ones, as long as all of these objects are external. See fns. 40 and 47 for a way to develop this idea.
See Martin ( 2004 , p. 71).
Ibid, pp. 68–70.
For other metaphysical disjunctivist attempts to fill this lacuna, see Alston ( 1999 , p. 191); Fish ( 2009 , p. 94); Allen ( 2015 ).
I use the terms reasonably natural property and natural kind in the sense of Lewis ( 1983 ).
For further discussion of fundamental kinds, see Mehta ( 2021 ).
Allen, K. (2015). Hallucination and imagination. Australasian Journal of Philosophy, 93 (2), 287–302.
Article Google Scholar
Alston, W. (1999). Back to the theory of appearing. Philosophical Perspectives, 13 , 181–203.
Google Scholar
Bayern, A. M. P., Danel, S., Auersperg, A. M. I., et al. (2018). Compound tool construction by New Caledonian crows. Scientific Reports, 8 (15676), 1–8.
Braddon-Mitchell, D. (2003). Qualia and analytical conditionals. Journal of Philosophy, 100 (3), 111–135.
Brewer, B. (2011). Perception and its objects . Oxford University Press.
Broad, C. (1952). Some elementary reflexions on sense-perception. Philosophy, 27 , 3–17.
Byrne, A., & Logue, H. (2008). Either/or. In A. Haddock & F. Macpherson (Eds.), Disjunctivism perception, action, knowledge (pp. 57–94). Oxford University Press.
Campbell, J. (2002). Reference and consciousness . Oxford University Press.
Chalmers, D. (2012). Constructing the world . Oxford University Press.
Fish, W. (2009). Perception, hallucination, and illusion . Oxford University Press.
French, C., & Gomes, A. (2019). How naïve realism can explain both the particularity and the generality of experience. Philosophical Quarterly, 69 (274), 41–63.
Genone, J. (2016). Recent work on naïve realism. American Philosophical Quarterly, 53 (1), 1–24.
Hinton, J. (1967). Visual experiences. Mind, 76 , 217–227.
Jackson, F. (1998). From metaphysics to ethics: A defence of conceptual analysis . Clarendon Press.
Kripke, S. (1972). Naming and necessity . Harvard University Press.
Levine, J. (2006). Conscious awareness and self-representation. In U. Kriegel & K. Williford (Eds.), Self-representational approaches to consciousness (pp. 173–198). MIT Press.
Lewis, D. (1983). New work for a theory of universals. Australasian Journal of Philosophy, 61 (4), 343–377.
Lewis, D. (1984). Putnam’s paradox. Australasian Journal of Philosophy, 62 (3), 221–236.
Logue, H. (2012). What should the naïve realist say about total hallucinations? Philosophical Perspectives, 26 , 173–199.
Logue, H. (2013). Good news for the disjunctivist about (one of) the bad cases. Philosophy and Phenomenological Research, 86 (1), 105–133.
Mackie, P. (2019). Perception, mind-independence, and Berkeley. Australasian Journal of Philosophy, 98 (3), 449–464.
Martin, M. (2002). The transparency of experience. Mind and Language, 17 (4), 376–425.
Martin, M. (2004). The limits of self-awareness. Philosophical Studies, 120 , 37–89.
Martin, M. (2006). On being alienated. In T. Gendler & J. Hawthorne (Eds.), Perceptual experience (pp. 354–410). Oxford University Press.
Mehta, N. (2021). “Naïve realism with many fundamental kinds.” Acta Analytica (online).
Mehta (ms). The many problems of perception.
Millar, B. (2014). The phenomenological directness of perceptual experience. Philosophical Studies, 170 , 235–253.
Miracchi, L. (2017). Perception first. Journal of Philosophy, 114 (12), 629–677.
Moran, A. (2018). Naïve realism, hallucination, and causation: A new response to the screening off problem. Australasian Journal of Philosophy, 97 (2), 368–382.
Nudds, M. (2009). Recent work in perception: Naïve realism and its opponents. Analysis Reviews, 69 (2), 334–346.
Schellenberg, S. (2018). The unity of perception: content, consciousness, evidence . Oxford University Press.
Siegel, S. (2004). Indiscriminability and the phenomenal. Philosophical Studies, 120 (1–3), 91–112.
Siegel, S. (2008). The epistemic conception of hallucination. In A. Haddock & F. Macpherson (Eds.), Disjunctivism (pp. 205–224). Oxford University Press.
Snowdon, P. (2005). The formulation of disjunctivism: A response to fish. Proceedings of the Aristotelian Society, 105 (1), 129–141.
Soteriou, M. (2016). Disjunctivism . Routledge.
Sturgeon, S. (2000). Matters of mind . Routledge.
Sturgeon, S. (2008). Disjunctivism about visual experience. In A. Haddock & F. Macpherson (Eds.), Disjunctivism: Perception, action, knowledge (pp. 112–143). Oxford University Pres.
Tye, M. (1995). Ten problems of consciousness: A representational theory of the phenomenal mind . MIT Press.
Download references
Author information
Authors and affiliations.
Yale-NUS College, Singapore, Singapore
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Neil Mehta .
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Reprints and permissions
About this article
Mehta, N. The Common Kind Theory and The Concept of Perceptual Experience. Erkenn 88 , 2847–2865 (2023). https://doi.org/10.1007/s10670-021-00480-z
Download citation
Received : 13 January 2021
Accepted : 10 October 2021
Published : 25 October 2021
Issue Date : October 2023
DOI : https://doi.org/10.1007/s10670-021-00480-z
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Find a journal
- Publish with us
- Track your research
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Sweepstakes
- Guided Meditations
- Verywell Mind Insights
- 2024 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
What Is Perception?
Recognizing Environmental Stimuli Through the Five Senses
Types of Perception
- How It Works
Perception Process
- Influential Factors
- Improvement Tips
- Potential Pitfalls
History of Perception
Perception refers to our sensory experience of the world. It is the process of using our senses to become aware of objects, relationships, and events. It is through this experience that we gain information about the environment around us.
Perception relies on the cognitive functions we use to process information, such as utilizing memory to recognize the face of a friend or detect a familiar scent. Through the perception process, we are able to both identify and respond to environmental stimuli.
Perception includes the five senses: touch, sight, sound, smell , and taste . It also includes what is known as proprioception , which is a set of senses that enable us to detect changes in body position and movement.
Many stimuli surround us at any given moment. Perception acts as a filter that allows us to exist within and interpret the world without becoming overwhelmed by this abundance of stimuli.
The different senses often separate the types of perception. These include visual, scent, touch, sound, and taste perception. We perceive our environment using each of these, often simultaneously.
There are also different types of perception in psychology, including:
- Person perception refers to the ability to identify and use social cues about people and relationships.
- Social perception is how we perceive certain societies and can be affected by things such as stereotypes and generalizations.
Another type of perception is selective perception. This involves paying attention to some parts of our environment while ignoring others.
The different types of perception allow us to experience our environment and interact with it in ways that are both appropriate and meaningful.
How Perception Works
Through perception, we become more aware of (and can respond to) our environment. We use perception in communication to identify how our loved ones may feel. We use perception in behavior to decide what we think about individuals and groups.
We perceive things continuously, even though we don't typically spend a great deal of time thinking about them. For example, the light that falls on our eye's retinas transforms into a visual image unconsciously and automatically. Subtle changes in pressure against our skin, allowing us to feel objects, also occur without a single thought.
Mindful Moment
Need a breather? Take this free 9-minute meditation focused on awakening your senses —or choose from our guided meditation library to find another one that will help you feel your best.
To better understand how we become aware of and respond to stimuli in the world around us, it can be helpful to look at the perception process. This varies somewhat for every sense.
In regard to our sense of sight, the perception process looks like this:
- Environmental stimulus: The world is full of stimuli that can attract attention. Environmental stimulus is everything in our surroundings that has the potential to be perceived.
- Attended stimulus: The attended stimulus is the specific object in the environment on which our attention is focused.
- Image on the retina: This part of the perception process involves light passing through the cornea and pupil onto the lens of the eye. The cornea helps focus the light as it enters, and the iris controls the size of the pupils to determine how much light to let in. The cornea and lens act together to project an inverted image onto the retina.
- Transduction: The image on the retina is then transformed into electrical signals through a process known as transduction. This allows the visual messages to be transmitted to the brain to be interpreted.
- Neural processing: After transduction, the electrical signals undergo neural processing. The path followed by a particular signal depends on what type of signal it is (for example, an auditory signal or a visual signal).
- Perception: In this step of the perception process, you perceive the stimulus object in the environment. It is at this point that you become consciously aware of the stimulus.
- Recognition: Perception doesn't just involve becoming consciously aware of the stimuli. It is also necessary for the brain to categorize and interpret what you are sensing. This next step, known as recognition, is the ability to interpret and give meaning to the object.
- Action: The action phase of the perception process involves some type of motor activity that occurs in response to the perceived stimulus. This might involve a significant action, like running toward a person in distress. It can also include doing something as subtle as blinking your eyes in response to a puff of dust blowing through the air.
Think of all the things you perceive on a daily basis. At any given moment, you might see familiar objects, feel a person's touch against your skin, smell the aroma of a home-cooked meal, or hear the sound of music playing in your neighbor's apartment. All of these help make up your conscious experience and allow you to interact with the people and objects around you.
Recap of the Perception Process
- Environmental stimulus
- Attended stimulus
- Image on the retina
- Transduction
- Neural processing
- Recognition
Factors Influencing Perception
What makes perception somewhat complex is that we don't all perceive things the same way. One person may perceive a dog jumping on them as a threat, while another person may perceive this action as the pup just being excited to see them.
Our perceptions of people and things are shaped by our prior experiences, our interests, and how carefully we process information. This can cause one person to perceive the exact same person or situation differently than someone else.
Perception can also be affected by our personality. For instance, research has found that four of the Big 5 personality traits —openness, conscientiousness, extraversion, and neuroticism—can impact our perception of organizational justice.
Conversely, our perceptions can also affect our personality. If you perceive that your boss is treating you unfairly, for example, you may show traits related to anger or frustration. If you perceive your spouse to be loving and caring, you may show similar traits in return.
Are Perception and Attitude the Same?
While they are similar, perception and attitude are two different things. Perception is how we interpret the world around us, while our attitudes (our emotions, beliefs, and behaviors) can impact these perceptions.
Tips to Improve Perception
If you want to improve your perception skills, there are some things that you can do. Actions you can take that may help you perceive more in the world around you—or at least focus on the things that are important—include:
- Pay attention. Actively notice the world around you, using all your senses. What do you see, hear, taste, smell, or touch? Using your sense of proprioception, notice the movements of your arms and legs or your changes in body position.
- Make meaning of what you perceive. The recognition stage of the perception process is essential since it allows you to make sense of the world around you. You place objects in meaningful categories so you can understand and react appropriately.
- Take action. The final step of the perception process involves taking some sort of action in response to your environmental stimulus. This could involve a variety of actions, such as stopping to smell the flower you see on the side of the road and incorporating more of your senses into your experiences.
Potential Pitfalls of Perception
The perception process does not always go smoothly, and there are a number of things that may interfere with our ability to interpret and respond to our environment. One is having a disorder that impacts perception.
Perceptual disorders are cognitive conditions marked by an impaired ability to perceive objects or concepts. Some disorders that may affect perception include:
- Spatial neglect syndromes , which involve not attending to stimuli on one side of the body
- Prosopagnosia , also called face blindness, is a disorder that makes it difficult to recognize faces
- Aphantasia , a condition characterized by an inability to visualize things in your mind
- Schizophrenia , a mental health condition that is marked by abnormal perceptions of reality
Some of these conditions may be influenced by genetics, while others result from stroke or brain injury.
Certain factors can also negatively affect perception. For instance, one study found that when people viewed images of others, they perceived individuals with nasal deformities as having less satisfactory personality traits. So, factors such as this can potentially affect personality perception in others.
Interest in perception dates back to ancient Greek philosophers who were interested in how people know the world and gain understanding. As psychology emerged as a science separate from philosophy, researchers became interested in understanding how different aspects of perception worked—particularly the perception of color.
In addition to understanding basic physiological processes, psychologists were also interested in understanding how the mind interprets and organizes these perceptions.
Gestalt psychologists proposed a holistic approach, suggesting that the whole is greater than the sum of its parts. Cognitive psychologists have also worked to understand how motivations and expectations can play a role in the process of perception.
As time progresses, researchers continue to investigate perception on the neural level. They also look at how injury, conditions, and substances might affect perception.
American Psychological Association. Perception .
University of Minnesota. 3.4 Perception . Organizational Behavior .
Jhangiani R, Tarry H. 5.4 Individual differences in person perception . Principles of Social Psychology - 1st International H5P Edition . Published online January 26, 2022.
Aggarwal A, Nobi K, Mittal A, Rastogi S. Does personality affect the individual's perceptions of organizational justice? The mediating role of organizational politics . Benchmark Int J . 2022;29(3):997-1026. doi:10.1108/BIJ-08-2020-0414
Saylor Academy. Human relations: Perception's effect . Human Relations .
ICFAI Business School. Perception and attitude (ethics) . Personal Effectiveness Management Course .
King DJ, Hodgekins J, Chouinard PA, Chouinard VA, Sperandio I. A review of abnormalities in the perception of visual illusions in schizophrenia . Psychon Bull Rev . 2017;24(3):734‐751. doi:10.3758/s13423-016-1168-5
van Schijndel O, Tasman AJ, Listschel R. The nose influences visual and personality perception . Facial Plast Surg . 2015;31(05):439-445. doi:10.1055/s-0035-1565009
Goldstein E. Sensation and Perception . Thomson Wadsworth; 2010.
Yantis S. Sensation and Perception . Worth Publishers; 2014.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."

- Table of Contents
- Random Entry
- Chronological
- Editorial Information
- About the SEP
- Editorial Board
- How to Cite the SEP
- Special Characters
- Advanced Tools
- Support the SEP
- PDFs for SEP Friends
- Make a Donation
- SEPIA for Libraries
- Entry Contents
Bibliography
Academic tools.
- Friends PDF Preview
- Author and Citation Info
- Back to Top
Perceptual Learning
“Perceptual Learning” refers, roughly, to long-lasting changes in perception that result from practice or experience (see E.J. Gibson 1963). William James, for instance, writes about how a person can become able to differentiate by taste between the upper and lower half of a bottle for a particular kind of wine (1890: 509). Assuming that the change in the person’s perception lasts, is genuinely perceptual (rather than, say, a learned inference), and is based on prior experience, James’ case is a case of perceptual learning.
This entry has three parts. The first part lays out the definition of perceptual learning as long-term changes in perception that result from practice or experience, and then distinguishes perceptual learning from several contrast classes. The second part specifies different varieties of perceptual learning. The third part details cases of perceptual learning in the philosophical literature and says why they are philosophically significant.
1.1 Perceptual Learning as Long-Term Perceptual Changes
1.2 perceptual learning as perceptual changes, 1.3 perceptual learning as resulting from practice or experience, 1.4 potential further criteria for defining perceptual learning, 1.5.1 perceptual development, 1.5.2 perception-based skills, 1.5.3 cognitive penetration, 1.5.4 machine learning, 2.1 differentiation, 2.2 unitization, 2.3 attentional weighting, 2.4 stimulus imprinting, 3.1 the contents of perception, 3.2 cognitive penetration, 3.3 the theory-ladenness of observation, 3.4 modularity, other internet resources, related entries, 1. defining perceptual learning.
In 1963, the psychologist Eleanor Gibson wrote a landmark survey article on perceptual learning in which she purported to define the term. According to Gibson, perceptual learning is “[a]ny relatively permanent and consistent change in the perception of a stimulus array, following practice or experience with this array…” (1963: 29). [ 1 ] Gibson’s definition has three basic parts. First, perceptual learning is long-lasting. Second, it is perceptual. Third, it is the result of practice or experience. This entry expands on each of these features of the definition.
Perceptual learning involves long-term changes in perception. This criterion rules out short term perceptual changes due to sensory adaptation (for more on sensory adaptation see Webster 2012). In the waterfall illusion, for instance, a person who looks at a waterfall for a minute, and then looks away at some rocks, sees the rocks as moving even though they are not. This is a short-term change in perception, lasting perhaps for fifteen to thirty seconds. Since it is not a long-term change in perception, however, it does not count as perceptual learning. In another short term adaptive change, a person who goes indoors after walking through a blizzard may have trouble as her eyes adjust to the new lighting. There is a change in her perception as a result of her experience in the blizzard. But it is not a long-term change, and so it does not count as perceptual learning.
While there are clear cases of long-term experience-induced perceptual changes and clear cases of short-term experience-induced perceptual changes, there may be intermediary cases where it is difficult to tell whether they count as long-term or not. In such cases, in order to determine whether the case is a genuine case of perceptual learning, it may be necessary to look at the mechanisms involved (see section 2 below on the mechanisms of perceptual learning). If the mechanisms involved are characteristic of other cases of perceptual learning, then that is a reason to count the case as an instance of perceptual learning. If the mechanisms involved are uncharacteristic of perceptual learning, then that is a reason not to count the case as an instance of perceptual learning.
Perceptual learning involves changes in perception . [ 2 ] This rules out mere changes in aesthetic taste, among other things. For instance, imagine a contrarian who likes things only insofar as other people do not like those things. Suppose he finds out that everyone else has come to like his favorite microbrew. This might cause him to change how he judges that beer aesthetically. However, the beer may well taste the same to him. So, it is not a case of perceptual learning, but a mere change in the person’s aesthetic judgment. The fact that perceptual learning involves changes in perception also rules out mere changes in belief. Suppose someone acquires the belief that the symphony movement they are hearing is a scherzo. If nothing changes in that person’s perception, this is not a case of perceptual learning. It is a change in the person’s belief, not a change in the person’s perception.
It is important here to distinguish perceptual learning from learning that is simply based on perception (see Dretske 2015: fn. 6). [ 3 ] Perceptual learning involves changes in perception, while learning that is based on perception need not. Looking at my table, I might learn that the cup is on the table. However, this does not involve any long-term changes in perception. It is learning that is based on perception, but it is not perceptual learning. Furthermore, I might learn to put the cup on the table into the dishwasher every time it is empty. Again, this is learning that is based on perception (I need to perceive the cup in order to move it). However, it is not perceptual learning.
One of the main reasons for holding that improvements in perceptual discrimination can be genuinely perceptual is due to somewhat recent evidence from neuroscience. As Manfred Fahle puts it, during the 1970s and 1980s, it tended to be the case that improvements in perceptual discrimination were thought to be cognitive rather than perceptual (2002: xii). However, during the 1990s, pressure was put on the cognitive interpretation due to new neuroscientific evidence in perceptual learning studies. In particular, studies found that learning-induced plasticity occurs in the adult primary sensory cortices much more than researchers had previously thought (Fahle 2002: xii). Neurological evidence of plasticity in adult primary sensory cortices due to learning provides some evidence that changes in perceptual discrimination can be due to perceptual learning. (See also Garraghty & Kass 1992: 522; Gilbert 1996: 269; Goldstone 2003: 238; Gilbert & Li 2012: 250; and Sagi 2011: 1552–53).
Perceptual learning involves perceptual changes of a particular kind, namely, those that result from practice or experience. For this reason, laser eye surgery or cataracts removal do not count as instances of perceptual learning. They are not really cases of learning because they do not result from practice or experience. So, while such cases involve long-term changes in perception, they do not count as cases of perceptual learning.
To be authentic cases of learning, perceptual changes have to be the result of a learning process. As a contrast case, suppose someone undergoes a long-term change in their perception due to a brain lesion. Such a change in perception does not result from a learning process, since the change in perception comes from the lesion, rather from practice or experience. Because of this, the case does not count as an instance of perceptual learning, even though it involves a long-term change in perception.
The conversation above roughly follows Eleanor Gibson’s definition of perceptual learning. However, there are also other accounts in the psychology literature. Robert Goldstone’s account of perceptual learning, for instance, agrees with Gibson’s account in many respects, but it additionally offers a story of why perceptual changes occur. On his account,
Perceptual learning involves relatively long-lasting changes to an organism’s perceptual system that improve its ability to respond to its environment and are caused by this environment . (1998: 587, italics added for emphasis)
This definition offers an answer to the question as to why perceptual learning occurs at all. On Goldstone’s account, perceptual learning occurs to improve an organism’s ability to respond to the environment.
Goldstone’s account admits of two different interpretations. On one interpretation, the account places a condition on perceptual learning: that to count as an instance of perceptual learning, a long-term perceptual change has to improve an organism’s ability to respond to the environment. Such an account gains plausibility if one thinks of “learning” as a success-term. The idea then is that each genuine instance of perceptual learning leads to success for the organism, namely, it improves the organism’s ability to respond to the environment. On a second interpretation of Goldstone’s account, however, it is not that each instance of perceptual learning has to improve an organism’s ability to respond to the environment. Rather, it is that perceptual learning is a general capacity for improving an organism’s ability to respond to the environment, even if perceptual learning fails to do so in some instances. Why might organisms have such a capacity? One possibility is that the capacity is a trait that improves fitness and is the product of natural selection. However, the biological origin of perceptual learning is an area of research that still needs to be carefully explored.
1.5 Contrast Classes
How much of the perceptual development we undergo as infants and young children is the result of learning? There are many difficulties distinguishing development from learning, conceptually (for some discussion, see Carey 2009, especially pp. 11–14). The issue of how to distinguish development from learning bears on the traditional philosophical debate between nativists and empiricists (see Markie 2015, for a summary of that debate). In the perceptual learning literature, for instance, Kellman and Garrigan reject the view that all perceptual development is the result of learning, a view that they consider to be empiricist (2009: 57). Specifically, they think that data on infant perception collected in and around the 1980s provide evidence that at least some perceptual development is innate:
What this research has shown is that the traditional empiricist picture of perceptual development is incorrect. Although perception becomes more precise with age and experience, basic capacities of all sorts – such as the abilities to perceive objects, faces, motion, three-dimensional space, the directions of sounds, coordinate the senses in perceiving events, and other abilities – arise primarily from innate or early-maturing mechanisms (Bushnell, Sai, & Mullin 1989; Gibson et al., 1979; Held 1985; Kellman & Spelke 1983; Meltzoff & Moore 1977; and Slater, Mattock, & Brown 1990). (Kellman & Garrigan 2009: 57)
In short, according to Kellman and Garrigan, evidence on infant perception—including evidence about object perception, the perception of faces, and the perception of three-dimensional space—tells against the view that all perceptual development is learned.
If not all perceptual development is learned, while all perceptual learning is learned, then there is a distinction between perceptual development and perceptual learning. One way to draw the distinction more fully is the following. Perceptual development involves perceptual learning. However, it does not just involve perceptual learning. It also involves what is called maturation . For instance, the abilities that Kellman and Garrigan describe above (object perception, the perception of faces, the perception of three-dimensional space, etc.) fall under the category of maturation.
There are many ways to try to draw the further distinction between perceptual maturation and perceptual learning. Some such ways are found in the debate between nativism and empiricism (see Samet 2008 and Markie 2015) and specifically in the difference between innate and acquired characteristics (see Griffiths 2009 and Cowie 2016). One potential criterion here is that cases of perceptual maturation involve perceptual abilities that are typical of the species, while cases of perceptual learning involve perceptual abilities that are not typical of the species. This criterion seems to get it right for some instances of perceptual learning, say, for those involved in birdwatching. After all, the perceptual abilities acquired in birdwatching are unique to birdwatchers, not typical of the entire human species. However, the criterion seems to get it wrong for other, more universal, instances of perceptual learning. For instance, since human faces are both ubiquitous and important to humans, the perceptual learning involved in face perception is in fact typical of the species.
In the literature on perceptual learning, by contrast, the distinction between perceptual learning and perceptual maturation is often drawn in terms of the role of the environment. On Goldstone’s account of perceptual learning, to count as perceptual learning, perceptual changes must be caused by the environment. It is important to understand why exactly Goldstone thinks that caused by the environment is a crucial feature of the definition. He thinks it is crucial since this criterion distinguishes between perceptual changes that are simply the result of maturation, and perceptual changes that are the result of learning. As Goldstone puts it, “If the changes are not due to environmental inputs, then maturation rather than learning is implicated” (1998: 586). Manfred Fahle puts it similarly by saying that the term maturation “ascribe[s] the main thrust of the changes in a behavior to genetics, not the environment” (2002: xi). For Fahle, this is what distinguishes it from perceptual learning.
A further point of contrast with perceptual learning is perception-based skills, such as dart-throwing or racecar driving. To understand the relationship between perceptual learning and perception-based skills, start by considering the following case. Williams and Davids (1998) reported that when expert soccer players defend opponents, they focus longer on their opponent’s hips than non-experts do. This tuned attention is a long-term change in perception that results from practice or experience. That is, it is an instance of perceptual learning (see section 2.3 below). Such changes certainly serve to enable perception-based skills. For instance, attending to the hips is part of what enables the soccer players to defend well. Since the hips provide a cue for what the offensive player will do next, when the defender attends there, it helps them to do all sorts of things: to keep the offensive player from dribbling by them; to keep the offensive player from completing a pass; and to keep them from shooting and scoring. Without the attentional tuning, the expert soccer players would not be able to perform as high above baseline as they do.
Perceptual learning can enable perception-based skills, yet it is important to distinguish these skills from perceptual learning. In fact, arguably, as Stanley and Krakauer (2013) claim, perceptual learning does not in itself give you a skill, properly speaking. One reason why, drawing on Stanley and Krakauer, is that skills quite plausibly require instruction (at least initially), or observation of someone else (2013: 3). Perceptual learning, by contrast, can at times be unsupervised learning (see Goldstone 2003: 241 and Goldstone & Byrge 2015: section 3). Long-term, learning-induced changes in perception sometimes happen through mere exposure to stimuli, and without any instruction whatsoever. Furthermore, arguably, as Stanley and Krakauer put it, “our skilled actions are always under our rational control…” (2013: 3; see also Stanley & Williamson forthcoming: 6). Yet, there is an important sense in which one cannot control a tuned attentional pattern like that of the expert soccer players mentioned above. Goldstone, for instance, cites a study on attentional tuning by Shiffrin and Schneider (1977). In that study, letters were used first as targets in the experiment, but later letters were used as distractors to be ignored (Goldstone 1998: 589). Due to their prior training with the letters, the subjects’ attention became automatic with respect to the letters in the scene, even though they were trying to deliberately ignore them. More generally, after training, it is difficult to rationally control a tuned attentional pattern because the attention is automatic toward particular properties.
Perceptual learning involves changes in perception that are long-term . This long-term criterion rules out some cases of cognitive penetration, that is, cases where one’s beliefs, thoughts, or desires influence one’s perception (see Macpherson 2012: 24). For instance, to borrow a case from Susanna Siegel (2012), if Jill sees Jack as angry because she just now believes Jack is angry, this need not be a case of perceptual learning, since it need not be a long-term change. After all, if Jill changes her belief that Jack is angry shortly after, she will no longer see his neutral face as angry. It would be a short-term change in her perception, not a long-term one. And so it would not be a case of perceptual learning.
Simply because some cases of cognitive penetration are not cases of perceptual learning, however, it does not follow that no cases of cognitive penetration are cases of perceptual learning. Jerry Fodor distinguishes between synchronic penetration and diachronic penetration, where only the latter involves “experience and training” (1984: 39). The case of Jack and Jill is a case of synchronic penetration, one where the penetration does not involve experience and training. However, at least some cases of perceptual learning might more plausibly fit into the category of diachronic penetration. (For more on the relationship between perceptual learning and cognitive penetration, see section 3.2 )
Machine perception seeks “to enable man-made machines to perceive their environments by sensory means as human and animals do” (Nevatia 1982: 1). Standard cases of machine perception involve computers that are able to recognize speech, faces, or types of objects. Some types of machine perception are simply programmed into the device. For instance, some speech recognition devices (especially older ones) are simply programmed to recognize speech, and do not learn beyond what they have been programmed to do. Other types of machine perception involve “machine learning” where the device learns based on the inputs that it receives, often involving some kind of feedback.
Like cases of perceptual learning, machine learning can be either supervised or unsupervised, although these distinctions mean something very specific in the machine case. In supervised learning, builders test the machine’s initial performance on, say, the recognition of whether a given image contains a face. They then measure the performance error and adjust the parameters of the machine to improve performance (LeCun, Bengio, & Hinton 2015: 436). Importantly, in cases of supervised learning, engineers program into the machine which features it should look for when, say, identifying a face. In cases of unsupervised learning, by contrast, the machine does not have information about its target features. The machine merely aims to find similarities in the given images, and if it is successful, the machine comes to group all the faces together according to their similarities (Dy & Brodley 2004: 845).
In machine learning, one major difficulty is that machines can develop racist and sexist patterns (for several examples, see Crawford 2016). The problem is often that engineers input a biased set of images (such as a set of images that include too many white people) into the machine, from which the machine builds its model (Crawford 2016). This suggests a potential corresponding source of bias in human perceptual learning, based on the inputs that humans receive through media.
2. Varieties of Perceptual Learning
The psychology literature provides ample evidence of perceptual learning. Goldstone (1998) helpfully distinguishes between four different types of perceptual learning in the literature: differentiation, unitization, attentional weighting, and stimulus imprinting. This section surveys these four types of perceptual learning (for further review, see Goldstone 2003; Goldstone, Braithwaite, & Byrge 2012; and Goldstone & Byrge 2015).
When most people reflect on perceptual learning, the cases that tend to come to mind are cases of differentiation . In differentiation, a person comes to perceive the difference between two properties, where they could not perceive this difference before. It is helpful to think of William James’ case of a person learning to distinguish between the upper and lower half of a particular kind of wine. Prior to learning, one cannot perceive the difference between the upper and lower half. However, through practice one becomes able to distinguish between the upper and lower half. This is a paradigm case of differentiation.
Psychologists have studied differentiation in lab environments. In one such study, experimenters took six native Japanese speakers who had lived in the United States from between six months and three years (Logan, Lively, & Pisoni 1991). The subjects were not native English speakers. The experimenters found that they were able to train these subjects to better distinguish between the phonemes /r/ and /l/. This is a case of improved differentiation, where the subjects became better at perceiving the difference between two properties, which they had more trouble telling apart before.
Unitization is the counterpart to differentiation. In unitization, a person comes to perceive as a single property, what they previously perceived as two or more distinct properties. One example of unitization is the perception of written words. When we perceive a written word in English, we do not simply perceive two or more distinct letters. Rather, we perceive those letters as a single word. Put another way, we perceive written words as a single unit (see Smith & Haviland 1972). This is not the case with non-words. When we perceive short strings of letters that are not words, we do not perceive them as a single unit. Goldstone and Byrge provide a list of items for which there is empirical evidence of such unitization:
birds, words, grids of lines, random wire structures, fingerprints, artificial blobs, and three-dimensional creatures made from simple geometric components. (2015: 823)
While unitization and differentiation are converses, the one unifying and the other distinguishing, Goldstone and Byrge also conceive of them as “flip sides of the same coin” (2015: 823). This is because, as they put it, both unitization and differentiation “involve creating perceptual units…” (2015: 823). Regardless of whether the unit arises from the fusion or the differentiation of two other units, both instances of perceptual learning involve the creation of new perceptual units.
In attentional weighting, through practice or experience people come to systematically attend toward certain objects and properties and away from other objects and properties. Paradigm cases of attentional weighting have been shown in sports studies, where it has been found, for instance, that expert fencers attend more to their opponents’ upper trunk area, while non-experts attend more to their opponents’ upper leg area (Hagemann et al., 2010). Practice or experience modulates attention as fencers learn, shifting it towards certain areas and away from other areas.
In the case of the expert fencer, a shift in the weight of attention to the opponents’ upper trunk area facilitates the expert’s fencing skills. However, shifts in attentional weighting can also fail to facilitate skills or even stifle them. For example, a new golfer with inadequate coaching might develop the bad habit of attending to their putter while putting, rather than learning to keep their “eye on the ball.” This unhelpful shift in attentional weighting may well stifle the new golfer’s ability to become a skillful putter.
One way to understand weighted attention is as attention that has become automatic with respect to particular properties. In other words, when the expert fencer attends to the upper trunk area, this attention is no longer governed by her intention (see Wu 2014: 33, for more on this account of automaticity). Rather, as the result of practice, the expert fencer’s attention is now automatic with respect to the trunk area . This italicized part is important. On Wayne Wu’s account of attention, for instance, one might ask whether attention is automatic with respect to different features of the process of attention: “where attention is directed and in what sequence, how long it is sustained, to what specific features in the scene, and so on” (p. 34). In the case of the expert fencer, plausibly her attention is automatic with respect to the trunk area, even if it is not automatic in other respects. This automaticity is the product of her learning process.
Recall that in unitization, what previously looked like two or more objects, properties, or events later looks like a single object, property, or event. Cases of “stimulus imprinting” are like cases of unitization in the end state (you detect a whole pattern), but there is no need for the prior state—no need for that pattern to have previously looked like two or more objects, properties, or events. This is because in stimulus imprinting, the perceptual system builds specialized detectors for whole stimuli or parts of stimuli to which a subject has been repeatedly exposed (Goldstone 1998: 591). Cells in the inferior temporal cortex, for instance, can have a heightened response to particular familiar faces (Perrett et al., 1984, cited in Goldstone 1998: 594). One area where these specialized detectors are helpful is with unclear or quickly presented stimuli (Goldstone 1998: 592). Stimulus imprinting happens entirely without guidance or supervision (Goldstone 2003: 241).
3. The Philosophical Significance of Perceptual Learning
Perceptual learning is philosophically significant both in itself, and for the role that it has played in prior philosophical discussions. Sections 3.1–3.4 will focus on the latter. However, there are good reasons to see perceptual learning as philosophically significant in itself, independently from the role that it has played in prior philosophical discussions.
Why is perceptual learning philosophically significant? One reason is that it says something about the very nature of perception—that perception is more complex than it might seem from the first-person point of view. Specifically, the fact that perceptual learning occurs means that the causes of perceptual states are not just the objects in our immediate environment, as it seems at first glance. Rather, given the reality of perceptual learning, there is a long causal history to our perceptions that involves prior perception. When the expert wine-taster tastes the Cabernet Sauvignon, for example, that glass of wine alone is not the sole cause of her perceptual state. Rather, the cause of her perceptual state includes prior wines and prior perceptions of those wines. One way to put this is to say that perception is more than the immediate inputs into our senses. It is tied to our prior experiences.
Another way in which perceptual learning is philosophically significant is because it shows how perception is a product of both the brain and the world. In this respect, there are some similarities between the role of constancy mechanisms and the role of perceptual learning, in that both involve the brain playing a role in structuring perception in a way that goes beyond the perceptual input. Constancy mechanisms, such as those involved in shape, size, and color constancy, are brain mechanisms that allow us to perceive shapes, sizes, and colors more stably across variations in distance or illumination. In cases of constancy, the brain manipulates the input from the world, and this allows the perceiver to track the shape, size, or color more easily. Similarly, in cases of perceptual learning, the brain manipulates the input from the world. In many cases, this may actually make the perception more helpful, as when through learning the perceptual system weights attention in a particular way, say, towards the features relevant for identifying a Cabernet Sauvignon. Perceptual learning might upgrade the epistemic status of perception, putting the perceiver in a better position with respect to knowledge (see Siegel 2017). At the same time, people can learn incorrectly, leading to perceptions that are unhelpful, as when a new golfer with inadequate coaching develops the bad habit of attending to their putter while putting, rather than attending to the golf ball.
Perceptual learning is philosophically significant in itself. In addition, the rest of section 3 goes on to explore the role that perceptual learning has played in prior philosophical discussions.
In the philosophy literature, cases of perceptual learning have often been used to show that through learning we come to represent new properties in perception, which we did not represent prior to learning. Siegel (2006, 2010), for instance, asks us to suppose that we have been tasked to cut down all and only the pine trees in a particular grove of trees. After several months pass, she says, pine trees might begin to look different to us. This is a case of perceptual learning, a long-term change in our perception following practice or experience with pine trees. Siegel uses the case to argue that perception comes to represent kind properties, like the property of being a pine tree . The idea is that the best way to explain the change in perception is that perception represents the property of being a pine tree after, but not before, learning takes place. That property becomes part of the content of perception: it comes to be presented in perceptual experience (for more background on the contents of perception, see Siegel 2016).
Thomas Reid’s notion of acquired perception has recently been interpreted in a way similar to Siegel’s pine tree case. According to Reid, some of our perceptions, namely acquired perceptions, are the result of prior experience. For instance, Reid writes about how through experience we might come to “perceive that this is the taste of cyder,” or “that this is the smell of an apple,” or that “this [is] the sound of a coach passing” ([1764] 1997: 171). Rebecca Copenhaver (2010, 2016) has interpreted Reid as claiming that through experience properties like being a cider , being an apple , and being a coach can come to be part of the content of our perception.
Cases of perceptual learning might also be used to show that through learning we come to represent new properties in perception, even if those properties are simply low-level properties like colors, shapes, textures, and bare sounds, rather than high-level kind properties like being a pine tree or being a cider . For instance, in discussing the perceptual expertise of jewelers, the 14 th -century Hindu philosopher Vedānta Deśika writes,
[T]he difference among colours [of a precious stone], which was first concealed by their similarity, is eventually made apparent as something sensual…. (Freschi [trans.] manuscript, Other Internet Resources, pp. 12–13)
In this case, the jeweler comes to perceive new colors in the gemstone, which others cannot perceive. This is a case where through learning someone comes to perceive a new low-level property.
The cases from both Reid and Vedānta Deśika both speak to the internal complexity of perception mentioned in the previous section. If Vedānta Deśika’s description of the jeweler case is accurate, then perception is more than the inputs into our senses, since both an expert jeweler and a non-expert can have the same visual inputs, but have different perceptions. Similarly, to take a new example from Reid, suppose that a farmer acquires the ability to literally see the rough amount corn in a heap ([1764] 1997: 172). Since both a farmer and a non-farmer can have the same visual inputs, but have different perceptions, the causes of their perceptions are not just restricted to the immediate objects out in their environment. Perception is more complex than that.
One of the most detailed contemporary discussions of cases of perceptual learning is found in Siewert (1998: section 7.9). Siewert discusses in detail the role that learning plays in altering perceptual phenomenology, although he stops short of saying that this affects the high-level contents of perception. He writes, for instance, that there is a difference in perceptual phenomenology between just seeing “something shaped, situated, and colored in a certain way,” and recognizing that thing as a sunflower (or another type) (1998: 255). Siewert also writes that a person might look different to you after you know them for a long time than they did the first time you met them, and that your neighborhood might look different to you after you have lived there for a long time than the first time you moved in (pp. 256, 258). Furthermore, he writes about how a chessboard in midgame might look differently to a chess player than to a novice, and how a car engine might look differently to a mechanic than to someone unfamiliar with cars (1998: 258). These are all examples where learning affects one’s sensory phenomenology.
Several cases of perceptual learning in the philosophical literature involve language learning, both in the case of written and spoken language. As an example of the former, Christopher Peacocke writes that there is a difference
between the experience of a perceiver completely unfamiliar with Cyrillic script seeing a sentence in that script and the experience of one who understands a language written in that script. (1992: 89)
With regard to spoken language, as Casey O’Callaghan (2011) points out, several philosophers have made the claim that after a person learns a spoken language, sounds in that language comes to sound different to them (O’Callaghan cites Block 1995: 234; Strawson 2010: 5–6; Tye 2000: 61; Siegel 2006: 490; Prinz 2006: 452; and Bayne 2009: 390). Ned Block, for instance, writes, “[T]here is a difference in what it is like to hear sounds in French before and after you have learned the language” (1995: 234). It is tempting to think that this difference is explicable in terms of the fact that, after learning a language, a person hears the meanings of the words, where they do not before learning the language. On such a view, meanings would be part of the contents of auditory perception. However, O’Callaghan (2011) denies this (see also O’Callaghan 2015 and Reiland 2015). He argues that the difference is in fact due to a kind of perceptual learning. Specifically, through learning we come to hear phonological features specific to the new language. As O’Callaghan argues, these phonological features, not the meanings, explain what it’s like to hear a new language.
By contrast, Brogaard (forthcoming) argues that meanings are in fact part of the content of perception (see also Pettit 2010). After offering arguments against the opposing view, she relies on evidence about perceptual learning to help make the positive case for her view. In particular, she uses evidence about perceptual learning to rebut the view that we use background information about context and combine it with what we hear, in order to get meanings. Instead, she argues, language learning is perceptual in nature. She points to changes in how we perceive utterances, more in chunks rather than in parts, as a result of learning. Background information directly influences what we hear, she argues, altering how language sounds to us.
Both Siegel’s pine tree case and the case of hearing a new language fundamentally involve phenomenal contrasts. That is, the motivating intuition in both cases is that there is a contrast in sensory phenomenology between two perceptual experiences. Interestingly, in both cases the phenomenal contrast is due to learning. The question in both the pine tree case and the new language case is what explains the difference in sensory phenomenology. Siegel argues that the best explanation in the pine tree case is that the property of being a pine (and, more generally, natural kind properties) can come to be represented in perception. O’Callaghan (2011) argues that the best explanation for the difference in sensory phenomenology in the new language case is that we come to hear phonological features specific to the new language. Brogaard (forthcoming) argues that the best explanation in that case is that we come to hear meanings in the new language.
Recall that cases of cognitive penetration are cases where one’s beliefs, thoughts, or desires influence one’s perception (see Macpherson 2012: 24). One role of perceptual learning in the philosophical literature has been to explain away putative cases of cognitive penetration. For instance, it might seem at first glance that Siegel’s pine tree case is a case of cognitive penetration, a case where one’s newly acquired concept of a pine tree influences one’s perception. Connolly (2014b) and Arstila (2016), however, have both argued that the best way to understand Siegel’s pine tree case is not as a case of cognitive penetration, but rather through the particular mechanisms of perceptual learning. Connolly counts it as a case of attentional weighting, while Arstila understands it as involving both unitization and differentiation.
One reason why perceptual learning is a good instrument for explaining away putative cases of cognitive penetration is the following. In cases of perceptual learning, it is the external environment that drives the perceptual changes. As Raftopoulos puts it, “perceptual learning does not necessarily involve cognitive top-down penetrability but only data-driven processes” (2001: 493). For putative cases of cognitive penetration, the strategy for the perceptual learning theorist is to show how the perceptual changes involved may have been data-driven instead of top-down. Several philosophers have used this strategy at times, including Pylyshyn (1999: section 6.3), Brogaard and Gatzia (2015: 2), as well as Stokes (2015: 94), and Deroy (2013) might be interpreted in that way as well.
One exception to the trend of explaining away putative cases of cognitive penetration in terms of perceptual learning is Cecchi (2014). Cecchi argues that a particular case of perceptual learning—that found in Schwartz, Maquet, and Frith (2002)—should count as a case of cognitive penetration. The study in question found changes in the primary visual cortex due to learning, and also that these changes were brought about by higher areas in the brain influencing the primary visual cortex. Because the perceptual changes were the result of top-down influence, Cecchi argues that this case of perceptual learning should count as a case of cognitive penetration.
One traditional debate in the philosophy of science is whether scientific observation is permeated with the theory of the scientist, or theory-laden (see the entry on theory and observation in science ). As Raftopoulos and Zeimbekis point out, when asking whether observation is theory-laden, the answer will depend in part on what it means for a subject to possess a theory (2015: 18). On their view, theories can be tacit, rather than just “having a set of beliefs and concepts” (p. 18).
Assuming that theories can be held tacitly, perceptual learning might plausibly play a role in making observation theory laden. Raftopoulos and Zeimbekis, for instance, ask us to imagine a scientist who has undergone perceptual learning in her expert domain (2015: 19). Specifically, through repeated exposure to items in her expert domain, she has developed perceptual sensitivity to certain features, in accordance with her professional needs. This includes learned attention to particular dimensions, and involves physical changes early in her visual system (p. 19). As a result, the scientist might quite literally see the world differently within her expert domain than someone from outside her expertise would see it.
Such a case suggests that perceptual learning can make observation theory-laden. The scientist’s perceptual system comes to shape the kind of visual information that makes it into the scientist’s conscious perception, and does so based on her professional needs. As Raftopoulos and Zeimbekis put it, the case suggests
that non-cognitive, clearly perceptual influences on incoming visual information can be indirect bearers of the kinds of theoretical commitments that we usually think of as the content of conceptually couched theories. (2015: 19)
Although the case does not involve explicit beliefs directly influencing perception, arguably it involves a theory being held tacitly and appropriated into one’s perceptual system.
According to the modular view of the mind (Fodor 1983), the basic systems involved in perception are encapsulated from information outside of it, excluding its inputs (see Robbins 2015, for a summary of modularity). It might then seem at first glance that cases of perceptual learning challenge the view that the mind is modular, at least insofar as they involve the modulation of perception through any background theory that the subject has. However, it is important to note that Fodor himself seems to allow for such cases of perceptual learning. While he thinks that perception is synchronically impenetrable, he allows for the possibility of diachronic penetration, that is, cases where “experience and training can affect the accessibility of background theory to perceptual mechanisms” (1984: 39).
Why think that a modular view of the mind should allow for diachronic penetration? When Fodor allows for diachronic penetration, he does so because the alternative is to say that all modular systems are specified endogenously (1984: 39). Fodor admits that this alternative would be too extreme, and he points out, for instance, that children learn something from hearing a language. In other words, the modules for language are not just specified endogenously. However, Fodor is conservative about the scope of diachronic penetration, suggesting that it may only happen within strict limits, perhaps limits that are themselves endogenously defined (1984: 39–40).
Other philosophers have argued that diachronic penetration of perception undermines modularity. Churchland (1988), for instance, sees Fodor’s allowance of diachronic penetration as “grudgingly conceded,” and he argues that diachronic penetration is in fact widespread, rather than something that happens within strict limits (p. 176). One such case, raised by Churchland, is the case of perceiving music. Churchland argues that a person who knows the relevant music theory and vocabulary “perceives, in any composition whether great or mundane, a structure, development, and rationale that is lost on the untrained ear” (1988: 179). Fodor replies that it is unclear whether such cases are genuinely perceptual (1988: 195). He suggests another possibility, which is that the person who knows the relevant music theory does not perceive it differently, but rather forms different beliefs about the music. Furthermore, even if the case is genuinely perceptual, Fodor replies that it could be that a trained ear results simply from repeated exposure to the relevant music, rather than through knowledge of theory (1988: 195).
- Ahissar, Merav & Shaul Hochstein, 2004, “The Reverse Hierarchy Theory of Visual Perceptual Learning”, Trends in cognitive sciences , 8(10): 457–464. doi:10.1016/j.tics.2004.08.011
- Arstila, Valtteri, 2016, “Perceptual Learning Explains Two Candidates for Cognitive Penetration”, Erkenntnis , 81(6): 1151–1172. doi:10.1007/s10670-015-9785-3
- Bao, Min, Lin Yang, Cristina Rios, Bin He, & Stephen A. Engel, 2010, “Perceptual Learning Increases the Strength of the Earliest Signals in Visual Cortex”, The Journal of Neuroscience , 30(45): 15080–15084. doi:10.1523/JNEUROSCI.5703-09.2010
- Bayne, Tim, 2009, “Perception and the Reach of Phenomenal Content”, The Philosophical Quarterly , 59(236): 385–404. doi:10.1111/j.1467-9213.2009.631.x
- Biederman, Irving & Margaret M. Shiffrar, 1987, “Sexing Day-Old Chicks: a Case Study and Expert Systems Analysis of a Difficult Perceptual-Learning Task”, Journal of Experimental Psychology: Learning, Memory, and Cognition , 13(4): 640–645. doi:10.1037/0278-7393.13.4.640
- Block, Ned, 1995, “On a Confusion About a Function of Consciousness”, Behavioral and Brain Sciences , 18(2): 227–247. doi:10.1017/S0140525X00038188
- Brogaard, Berit, forthcoming, “In Defense of Hearing Meanings”, Synthese .
- Brogaard, Berit & Dimitria Electra Gatzia, 2015, “Is the Auditory System Cognitively Penetrable?” Frontiers in Psychology , 6: 1166. doi:10.3389/fpsyg.2015.01166
- Bryan, William Lowe & Noble Harter, 1897, “Studies in the Physiology and Psychology of the Telegraphic Language”, Psychological Review , 4(1): 27–53. doi:10.1037/h0073806
- –––, 1899, “Studies on the Telegraphic Language. The Acquisition of a Hierarchy of Habits”, Psychological Review , 6(4): 345–375. doi:10.1037/h0073117
- Bushnell, I.W.R., F. Sai, & J.T. Mullin, 1989, “Neonatal Recognition of the Mother’s Face”, British Journal of Developmental Psychology , 7(1): 3–15. doi:10.1111/j.2044-835X.1989.tb00784.x
- Carey, Susan, 2009, The Origin of Concepts , New York: Oxford University Press.
- Cecchi, Ariel S., 2014, “Cognitive Penetration, Perceptual Learning and Neural Plasticity”, dialectica , 68(1): 63–95. doi:10.1111/1746-8361.12051
- Chudnoff, Elijah, forthcoming, “The Epistemic Significance of Perceptual Learning”, Inquiry .
- Churchland, Paul M., 1988, “Perceptual Plasticity and Theoretical Neutrality: A Reply to Jerry Fodor”, Philosophy of Science , 55(2): 167–187. doi:10.1086/289425
- Connolly, Kevin, 2014a, “Multisensory Perception as an Associative Learning Process”, Frontiers in Psychology , 5: 1095, 1095. doi:10.3389/fpsyg.2014.01095
- –––, 2014b, “Perceptual Learning and the Contents of Perception”, Erkenntnis , 79(6): 1407–1418. doi:10.1007/s10670-014-9608-y
- –––, forthcoming, “Sensory Substitution and Perceptual Learning”, in Sensory Substitution and Augmentation , Fiona Macpherson (ed.), Oxford: Oxford University Press.
- Copenhaver, Rebecca, 2010, “Thomas Reid on Acquired Perception”, Pacific Philosophical Quarterly , 91(3): 285–312. doi:10.1111/j.1468-0114.2010.01368.x
- –––, 2016, “Additional Perceptive Powers: Comments on Van Cleve's Problems from Reid”, Philosophy and Phenomenological Research , 93(1): 218–224. doi:10.1111/phpr.12317
- Cowie, Fiona, 2016, “Innateness and Language”, The Stanford Encyclopedia of Philosophy (Winter 2016 Edition), Edward N. Zalta (ed.), URL = < https://plato.stanford.edu/archives/win2016/entries/innateness-language/ >.
- Crawford, Kate, 2016, “Artificial Intelligence’s White Guy Problem”, The New York Times , June 25, 2016, p. SR11.
- Deroy, Ophelia, 2013, “Object-Sensitivity Versus Cognitive Penetrability of Perception”, Philosophical Studies , 162(1): 87–107. doi:10.1007/s11098-012-9989-1
- Dretske, Fred, 2015, “Perception versus Conception: The Goldilocks Test”, in Zeimbekis & Raftopoulos 2015: pp. 163-173. doi:10.1093/acprof:oso/9780198738916.003.0007
- Dy, Jennifer G. & Carla E. Brodley, 2004, “Feature Selection for Unsupervised Learning”, Journal of Machine Learning Research , 5(Aug): 845–889. [ Dy & Brodley 2004 available online ]
- Fahle, Manfred, 2002, “Introduction”, in Manfred Fahle & Tomaso A. Poggio (eds.) Perceptual Learning , Cambridge, MA: MIT Press, pp. ix–xx.
- Fodor, Jerry, 1983, The Modularity of Mind , Cambridge, MA: MIT Press.
- Fodor, Jerry, 1984, “Observation Reconsidered”, Philosophy of Science , 51(1): 23–43. doi:10.1086/289162
- Fodor, Jerry, 1988, “A Reply to Churchland's ‘Perceptual Plasticity and Theoretical Neutrality’”, Philosophy of Science , 55(2): 188-198. doi:10.1086/289426
- Garraghty, Preston E. & Jon H. Kaas, 1992, “Dynamic Features of Sensory and Motor Maps”, Current Opinion in Neurobiology , 2(4): 522–527. doi:10.1016/0960-9822(92)90655-T
- Gauthier, Isabel & Michael J. Tarr, 1997, “Becoming a ‘Greeble’ Expert: Exploring Mechanisms for Face Recognition”, Vision Research , 37(12): 1673–1682. doi:10.1016/S0042-6989(96)00286-6
- Gendler, Tamar Szabo & John Hawthorne (eds), 2006, Perceptual Experience , Oxford: Oxford University Press. doi:10.1093/acprof:oso/9780199289769.001.0001
- Gibson, Eleanor J., 1963, “Perceptual Learning”, Annual Review of Psychology , 14: 29–56. doi:10.1146/annurev.ps.14.020163.000333
- –––, 1969, Principles of Perceptual Learning and Development , New York: Appleton-Century-Crofts.
- Gibson, Eleanor J. & Richard D. Walk, 1956, “The Effect of Prolonged Exposure to Visually Presented Patterns on Learning to Discriminate Them”, Journal of Comparative and Physiological Psychology , 49(3): 239–242. doi:10.1037/h0048274
- Gibson, Eleanor J., Cynthia J. Owsley, Arlene Walker, & Jane Megaw-Nyce, 1979, “Development of the Perception of Invariants: Substance and Shape”, Perception , 8(6): 609–19. doi:10.1068/p080609
- Gibson, James J. & Eleanor J. Gibson, 1955, “Perceptual Learning: Differentiation or Enrichment?” Psychological Review , 62: 32–41. doi:10.1037/h0048826
- Gilbert, Charles D., 1996, “Plasticity in Visual Perception and Physiology”, Current Opinion in Neurobiology , 6(2): 269–274.
- Gilbert, Charles D. & Wu Li, 2012, “Adult Visual Cortical Plasticity”, Neuron , 75(2): 250–264. doi:10.1016/j.neuron.2012.06.030
- Goldstone, Robert L., 1998, “Perceptual Learning”, Annual Review of Psychology , 49: 585–612. doi:10.1146/annurev.psych.49.1.585
- –––, 2003, “Learning to Perceive While Perceiving to Learn”, in Perceptual Organization in Vision: Behavioral and Neural Perspectives , Ruth Kimchi, Marlene Behrmann, & Carl R. Olson (eds), Mahwah, NJ: Lawrence Erlbaum Associates, pp. 233–278.
- –––, 2010, “Foreword” to Isabel Gauthier, Michael Tarr, & Daniel Bub, Perceptual Expertise: Bridging Brain and Behavior , Oxford/New York: Oxford University Press, p. v–ix. doi:10.1093/acprof:oso/9780195309607.001.0001
- Goldstone, Robert L., David W. Braithwaite, & Lisa A. Byrge, 2012, “Perceptual Learning”, in Norbert M. Seel (ed.), Encyclopedia of the Sciences of Learning , Heidelberg, Germany: Springer Verlag GmbH, pp. 2580–2583. doi:10.1007/978-1-4419-1428-6_147
- Goldstone, Robert L. & Lisa A. Byrge, 2015, “Perceptual Learning”, in The Oxford Handbook of the Philosophy of Perception , Mohan Matthen (ed.), Oxford: Oxford University Press, pp. 812–832. doi:10.1093/oxfordhb/9780199600472.013.029
- Griffiths, Paul, 2009, “The Distinction Between Innate and Acquired Characteristics”, The Stanford Encyclopedia of Philosophy (Fall 2009 Edition), Edward N. Zalta (ed.), URL = < http://plato.stanford.edu/archives/fall2009/entries/innate-acquired/ >.
- Hagemann, Norbert, Jörg Schorer, Rouwen Cañal-Bruland, Simone Lotz, & Bernd Strauss, 2010, “Visual Perception in Fencing: Do the Eye Movements of Fencers Represent Their Information Pickup?” Attention, Perception, & Psychophysics , 72(8): 2204–2214. doi:10.3758/BF03196695
- Hall, Geoffrey, 1991, Perceptual and Associative Learning , Oxford: Clarendon Press. doi:10.1093/acprof:oso/9780198521822.001.0001
- Hatfield, Gary, 2009, “Perception as Unconscious Inference”, in Gary Hatfield, Perception and Cognition: Essays in the Philosophy of Psychology , Oxford: Oxford University Press, pp. 124–152.
- Held, R., 1985, “Binocular Vision: Behavioral and Neuronal Development”, in Jacques A. Mehler, & Robin Fox (eds.), Neonate Cognition: Beyond the Blooming Buzzing Confusion , Hillsdale, NJ: Erlbaum, pp. 37–44.
- James, William, 1890, The Principles of Psychology , New York: Henry Holt and Company.
- Kellman, Philip J., 2002, “Perceptual Learning”, in Hal Pashler & Randy Gallistel (eds.), Stevens’ Handbook of Experimental Psychology: Learning, Motivation, and Emotion (Vol. 3, 3rd edition), New York, NY: John Wiley & Sons, pp. 259–299.
- Kellman, Philip J. & Patrick Garrigan, 2009, “Perceptual Learning and Human Expertise”, Physics of Life Reviews , 6(2): 53–84. doi:10.1016/j.plrev.2008.12.001
- Kellman, Philip J. & Christine M. Massey, 2013, “Perceptual Learning, Cognition, and Expertise”, in B.H. Ross (ed.), The Psychology of Learning and Motivation , Vol. 58, Academic Press, Elsevier Inc., pp. 117–165. doi:10.1016/B978-0-12-407237-4.00004-9
- Kellman, Philip J. & Elizabeth S. Spelke, 1983, “Perception of Partly Occluded Objects in Infancy”, Cognitive Psychology , 15(4): 483–524. doi:10.1016/0010-0285(83)90017-8
- LeCun, Yann, Yoshua Bengio, & Geoffrey Hinton, 2015, “Deep Learning”, Nature , 521(7553): 436–444. doi:10.1038/nature14539
- Logan, John S., Scott E. Lively, & David B. Pisoni, 1991, “Training Japanese Listeners to Identify English /r/ and /l/: A First Report”, The Journal of the Acoustical Society of America , 89(2): 874–886.
- Lyons, Jack C., 2005, “Perceptual Belief and Nonexperiential Looks”, Philosophical Perspectives , 19(1): 237–256.
- –––, 2009, Perception and Basic Beliefs: Zombies, Modules, and the Problem of the External World , New York: Oxford University Press. doi:10.1093/acprof:oso/9780195373578.001.0001
- Macpherson, Fiona, 2012, “Cognitive Penetration of Colour Experience: Rethinking the Issue in Light of An Indirect Mechanism”, Philosophy and Phenomenological Research , 84(1): 24–62. doi:10.1111/j.1933-1592.2010.00481.x
- Markie, Peter, 2015, “Rationalism vs. Empiricism”, The Stanford Encyclopedia of Philosophy (Summer 2015 Edition), Edward N. Zalta (ed.), URL = < http://plato.stanford.edu/archives/sum2015/entries/rationalism-empiricism/ >.
- Matthen, Mohan, 2014, “How to Be Sure: Sensory Exploration and Empirical Certainty”, Philosophy and Phenomenological Research , 88(1): 38–69. doi:10.1111/j.1933-1592.2011.00548.x
- –––, forthcoming, “Play, Skill, and the Origins of Perceptual Art”, British Journal of Aesthetics .
- Meltzoff, Andrew N. & M. Keith Moore, 1977, “Imitation of Facial and Manual Gestures by Human Neonates”, Science , 198(4312): 75–78. doi:10.1126/science.198.4312.75
- Nanay, Bence, 2017, “Perceptual Learning, the Mere Exposure Effect and Aesthetic Antirealism”, Leonardo , 50(1): 58–63. doi:10.1162/LEON_a_01082
- Nevatia, Ramakant, 1982, Machine Perception , Englewood Cliffs, NJ: Prentice-Hall.
- O’Callaghan, Casey, 2011, “Against Hearing Meanings”, Philosophical Quarterly , 61(245): 783–807. doi:10.1111/j.1467-9213.2011.704.x
- –––, 2015, “Speech Perception”, in The Oxford Handbook of the Philosophy of Perception , Mohan Matthen (ed.), Oxford: Oxford University Press, pp. 475–494. doi:10.1093/oxfordhb/9780199600472.013.032
- Orlandi, Nico, 2014, The Innocent Eye: Why Vision is Not a Cognitive Process , Oxford: Oxford University Press. doi:10.1093/acprof:oso/9780199375035.001.0001
- Peacocke, Christopher, 1992, A Study of Concepts , Cambridge, MA: MIT Press.
- Perrett, David I., P.A.J. Smith, Douglas David Potter, A.J. Mistlin, A.D. Head, & M.A. Jeeves, 1984, “Neurones Responsive to Faces in the Temporal Cortex: Studies of Functional Organization, Sensitivity to Identity and Relation to Perception”, Human Neurobiology , 3(4): 197–208.
- Pettit, Dean, 2010, “On the Epistemology and Psychology of Speech Comprehension”, The Baltic International Yearbook of Cognition, Logic and Communication , 5(Meaning, Understanding and Knowledge): 1–43. doi:10.4148/biyclc.v5i0.286
- Pourtois, Gilles, Karsten S. Rauss, Patrik Vuilleumier, & Sophie Schwartz, 2008, “Effects of Perceptual Learning on Primary Visual Cortex Activity in Humans”, Vision Research , 48(1): 55–62. doi:10.1016/j.visres.2007.10.027
- Prinz, Jesse, 2006, “Beyond Appearances: the Content of Sensation and Perception”, in Gendler & Hawthorne 2006: 434–459. doi:10.1093/acprof:oso/9780199289769.003.0013
- Pylyshyn, Zenon, 1999, “Is Vision Continuous with Cognition? The Case for Cognitive Impenetrability of Visual Perception”, Behavioral and Brain Sciences , 22(3): 341–365.
- Raftopoulos, Athanassios, 2001, “Is Perception Informationally Encapsulated? The Issue of the Theory-Ladenness of Perception”, Cognitive Science , 25(3): 423–451. doi:10.1207/s15516709cog2503_4
- Raftopoulos, Athanassios & John Zeimbekis, 2015, “The Cognitive Penetrability of Perception: An Overview”, in Zeimbekis & Raftopoulos 2015: pp. 1-56. doi:10.1093/acprof:oso/9780198738916.003.0001
- Reiland, Indrek, 2015, “On Experiencing Meanings”, The Southern Journal of Philosophy , 53(4): 481–492. doi:10.1111/sjp.12150
- Reid, Thomas, [1764] 1997, An Inquiry into the Human Mind on the Principles of Common Sense , D.R. Brookes (ed.), Edinburgh: Edinburgh University Press.
- –––, [1785] 2002, Essays on the Intellectual Powers of Man , D.R. Brookes (ed.), Edinburgh: Edinburgh University Press.
- Robbins, Philip, 2015, “Modularity of Mind”, The Stanford Encyclopedia of Philosophy (Summer 2015 Edition), Edward N. Zalta (ed.), URL = < http://plato.stanford.edu/archives/sum2015/entries/modularity-mind/ >.
- Sagi, Dov, 2011, “Perceptual Learning in Vision Research”, Vision Research , 51(13): 1552–1566. doi:10.1016/j.visres.2010.10.019
- Samet, Jerry, 2008, “The Historical Controversies Surrounding Innateness”, The Stanford Encyclopedia of Philosophy (Fall 2008 Edition), Edward N. Zalta (ed.), URL = < https://plato.stanford.edu/archives/fall2008/entries/innateness-history/ >.
- Schwartz, Sophie, Pierre Maquet, & Chris Frith, 2002, “Neural Correlates of Perceptual Learning: A Functional MRI Study of Visual Texture Discrimination”, Proceedings of the National Academy of Sciences , 99(26): 17137–17142. doi:10.1073/pnas.242414599
- Siegel, Susanna, 2006, “Which Properties Are Represented in Perception?” in Gendler & Hawthorne 2006: 481–503. doi:10.1093/acprof:oso/9780199289769.003.0015
- –––, 2010, The Contents of Visual Experience , Oxford: Oxford University Press.
- –––, 2012, “Cognitive Penetrability and Perceptual Justification”, Noûs , 46(2): 201–222. doi:10.1111/j.1468-0068.2010.00786.x
- –––, 2016, “The Contents of Perception”, The Stanford Encyclopedia of Philosophy (Spring 2016 Edition), Edward N. Zalta (ed.), URL = < http://plato.stanford.edu/archives/spr2016/entries/perception-contents/ >.
- –––, 2017, The Rationality of Perception , New York: Oxford University Press.
- Siewert, Charles P., 1998, The Significance of Consciousness , Princeton, NJ: Princeton University Press.
- Shiffrin, Richard M. & Walter Schneider, 1977, “Controlled and Automatic Human Information Processing: II. Perceptual Learning, Automatic Attending and a General Theory”, Psychological Review , 84(2): 127–190. doi:10.1037/0033-295X.84.2.127
- Slater, Alan, Anne Mattock, & Elizabeth Brown, 1990, “Size Constancy at Birth: Newborn Infants’ Responses to Retinal and Real Size”, Journal of Experimental Child Psychology , 49(2): 314–322.
- Smith Edward E. & Susan E. Haviland, 1972, “Why Words Are Perceived More Accurately Than Nonwords: Inference Versus Unitization”, Journal of Experimental Psychology , 92(1): 59–64
- Stanley, Jason & John W. Krakauer, 2013, “Motor Skill Depends on Knowledge of Facts”, Frontiers in Human Neuroscience , 7: 503 doi:10.3389/fnhum.2013.00503
- Stanley, Jason & Timothy Williamson, forthcoming, “Skill”, Noûs , early online 21 May 2016, doi:10.1111/nous.12144
- Stokes, Dustin, 2015, “Towards a Consequentialist Understanding of Cognitive Penetration”, in Zeimbekis & Raftopoulos 2015: pp. 75-100. doi:10.1093/acprof:oso/9780198738916.003.0003
- Strawson, Galen, [1994] 2010, Mental Reality , 2nd edition, Cambridge, MA: MIT Press.
- Tye, Michael, 2000, Consciousness, Color, and Content , Cambridge, MA: MIT Press.
- Vaassen, Bram M.K., 2016, “Basic Beliefs and the Perceptual Learning Problem: A Substantial Challenge for Moderate Foundationalism”, Episteme , 13(1): 133–149. doi:10.1017/epi.2015.58
- Webster, Michael A., 2012, “Evolving Concepts of Sensory Adaptation”, F1000 Biology Reports , 4: 21. doi:10.3410/B4-21 [ Webster 2012 available online ]
- Williams, A.M. & K. Davids, 1998, “Visual Search Strategy, Selective Attention, and Expertise in Soccer”, Research Quarterly for Exercise and Sport , 69(2): 111–128. doi:10.1080/02701367.1998.10607677
- Wu, Wayne, 2014, Attention , New York: Routledge.
- Zeimbekis, John & Athanassios Raftopoulos (eds.), 2015, The Cognitive Penetrability of Perception New Philosophical Perspectives , Oxford: Oxford University Press. doi:10.1093/acprof:oso/9780198738916.001.0001
How to cite this entry . Preview the PDF version of this entry at the Friends of the SEP Society . Look up topics and thinkers related to this entry at the Internet Philosophy Ontology Project (InPhO). Enhanced bibliography for this entry at PhilPapers , with links to its database.
- Freschi, Elisa., manuscript, “ The Refutation of Any Extra-Sensory Perception in Vedānta Deśika: A Philosophical Appraisal of Seśvaramīmāṃsā ad MS 1.1.4 .”
innateness: and contemporary theories of cognition | mind: modularity of | perception: experience and justification | perception: the contents of | science: theory and observation in
Acknowledgments
Special thanks for their comments to Susanna Siegel, Rebecca Copenhaver, and to the University of Pennsylvania Perceptual Learning Reading Group: Gary Hatfield, Adrienne Prettyman, Louise Daoust, Ting Fung Ho, Ben White, and Devin Curry. This entry was prepared with funding from the Cambridge New Directions in the Study of the Mind Project.
Copyright © 2017 by Kevin Connolly < kevinlconnolly @ gmail . com >
- Accessibility
Support SEP
Mirror sites.
View this site from another server:
- Info about mirror sites
The Stanford Encyclopedia of Philosophy is copyright © 2023 by The Metaphysics Research Lab , Department of Philosophy, Stanford University
Library of Congress Catalog Data: ISSN 1095-5054

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Front Psychol
Attention and Conscious Perception in the Hypothesis Testing Brain
Jakob hohwy.
1 Department of Philosophy, Monash University, Melbourne, VIC, Australia
Conscious perception and attention are difficult to study, partly because their relation to each other is not fully understood. Rather than conceiving and studying them in isolation from each other it may be useful to locate them in an independently motivated, general framework, from which a principled account of how they relate can then emerge. Accordingly, these mental phenomena are here reviewed through the prism of the increasingly influential predictive coding framework. On this framework, conscious perception can be seen as the upshot of prediction error minimization and attention as the optimization of precision expectations during such perceptual inference. This approach maps on well to a range of standard characteristics of conscious perception and attention, and can be used to interpret a range of empirical findings on their relation to each other.
Introduction
The nature of attention is still unresolved, the nature of conscious perception is still a mystery – and their relation to each other is not clearly understood. Here, the relation between attention and conscious perception is reviewed through the prism of predictive coding. This is the idea that the brain is essentially a sophisticated hypothesis tester (Helmholtz, 1860 ; Gregory, 1980 ), which continually and at multiple spatiotemporal scales seeks to minimize the error between its predictions of sensory input and the actual incoming input (see Mumford, 1992 ; Friston, 2010 ). On this framework, attention and perception are two distinct, yet related aspects of the same fundamental prediction error minimization mechanism. The upshot of the review here is that together they determine which contents are selected for conscious presentation and which are not. This unifies a number of experimental findings and philosophical issues on attention and conscious perception, and puts them in a different light. The prediction error minimization framework transpires as an attractive, if yet still speculative, approach to attention and consciousness, and their relation to each other.
Attention is difficult to study because it is multifaceted and intertwined with conscious perception. Thus, attention can be endogenous (more indirect, top-down, or motivationally driven) or exogenous (bottom-up, attention grabbing); it can be focal or global; it can be directed at objects, properties, or spatial or temporal regions, and so on (Watzl, 2011a , b ). Attentional change often seems accompanied by a change in conscious perception such that what grabs attention is a new stimulus, and such that whatever is attended to also populates consciousness. It can therefore be difficult to ascertain whether an experimental manipulation intervenes cleanly on attention or whether it intervenes on consciousness too (Van Boxtel et al., 2010 ).
Consciousness is difficult to study, partly because of the intertwinement with attention and partly because it is multifaceted too. Consciousness can apply to an overall state (e.g., awake vs. dreamless sleep) or a particular representation (e.g., conscious vs. unconscious processing of a face) all somehow tied together in the unity of the conscious stream (Bayne, 2010 ); it can pertain to the notion of a self (self-awareness) or just to being conscious (experience), and so on (Hohwy and Fox, 2012 ) 1 . There are widely accepted tools for identifying the neural correlates of conscious experience, though there is also some controversy about how cleanly they manipulate conscious states rather than a wide range of other cognitive processes (Hohwy, 2009 ). In the background is the perennial, metaphysical mind–body problem (Chalmers, 1996 ), which casts doubt on the possibility of ever achieving a fundamentally naturalist understanding of consciousness; (we will not discuss any metaphysics in this paper, however).
Functionally, attention is sometimes said to be an “analyzer,” dissecting and selecting among the many possible and often competing percepts one has at any given time. Consciousness in contrast seems to be a “synthesizer,” bringing together and organizing our multitudinous sensory input at any given time (Van Boxtel et al., 2010 ). On the other hand, attention may bring unity too, via binding (Treisman and Gelade, 1980 ), and consciousness also has a selective role when ambiguities in the sensory input are resolved in favor of one rather than the other interpretation, as seems to happen in binocular rivalry.
Attention and consciousness, then, are both difficult to define, to operationalize in functional terms, and to manipulate experimentally. Part of the trouble here has to do with the phenomena themselves, and possibly even their metaphysical underpinnings. But a large part of the trouble seems due to their intertwined relations. It is difficult to resolve these issues by appeal to commonsense or empirically informed conceptual analyses of each phenomenon in isolation of the other. For this reason it may be fruitful to appeal to a very general theoretical framework for overall brain function, such as the increasingly influential prediction error minimization approach, and review whether it implies coherently related phenomena with a reasonable fit to attention and conscious perception.
Section “ Aspects of Prediction Error Minimization ” describes heuristically the prediction error minimization approach. Section “ Prediction Error and Precision ” focuses on two aspects of this approach, here labeled accuracy and precision, and maps these onto perceptual inference and attention. Section “ Conscious Perception and Attention as Determined by Precise Prediction Error Minimization ” outlines why this mapping might be useful for understanding conscious perception and its relation to attention. In Section “ Interpreting Empirical Findings in the Light of Attention as Precision Optimization ,” the statistical dimensions of precision and accuracy are used to offer interpretations of empirical studies of the relation between attention and consciousness. The final section briefly offers some broader perspectives.
Aspects of Prediction Error Minimization
Two things motivate the idea of the hypothesis testing brain: casting a core task for the brain in terms of causal inference, and then appealing to the problem of induction.
The brain needs to represent the world so we can act meaningfully on it, that is, it has to figure out what in the world causes its sensory input. Representation is thereby a matter of causal inference. Causal inference however is problematic since a many–many relation holds between cause and effect: one cause can have many different effects, and one effect can have many different causes. This is the kernel of Hume’s problem of induction (Hume, 1739–1740 , Book I, Part III, Section vi): cause and effect are distinct existences and there are no necessary connections between distinct existences. Only with the precarious help of experience can the contingent links between them be revealed.
For the special case of the brain’s attempt to represent the world, the problem of induction concerns how causal inference can be made “backwards” from the effects given in the sensory input to the causes in the world. This is the inverse problem, and it has a deep philosophical sting in the case of the brain. The brain never has independent access to both cause and effect because to have that it would already have had to solve the problem of representation. So it cannot learn from experience by just correlating occurrences of the two. It only has the effects to go by so must somehow begin the representational task de novo .
The prediction error minimization approach resolves this problem in time. The basic idea, described heuristically here, is simple whereas the computational details are complex (Friston, 2010 ). Sensory input is not just noise but has repeatable patterns. These patterns can give rise to expectations about subsequent input. The expectations can be compared to that subsequent input and the difference between them be measured. If there is a tight fit, then the pattern generating the expectation has captured a pattern in the real world reasonably well (i.e., the difference was close to expected levels of irreducible noise). If the fit is less good, that is, if there is a sizeable prediction error, then the states and parameters of the hypothesis or model of the world generating the expectation should be revised so that subsequent expectations will, over time, get closer to the actual input.
This idea can be summed up in the simple dictum that to resolve the inverse problem all that is needed is prediction error minimization. Expected statistical patterns are furnished by generative models of the world and instead of attempting the intractable task of inverting these models to extract causes from generated effects, prediction error minimization ensures that the model recapitulates the causal structure of the world and is implicitly inverted; providing a sufficient explanation for sensory input.
This is consistent with a Bayesian scheme for belief revision in the light of new evidence, and indeed both Bayes as well as Laplace (before he founded classical frequentist statistics) developed their theories in response to the Humean-inspired inverse problem (McGrayne, 2011 ). The idea is to weight credence in an existing model of the world by how tightly it fits the evidence (i.e., the likelihood or how well it predicts the input) as well as how likely the model is in the first place (i.e., the prior probability or what the credence for the model was before the evidence came in).
The inverse problem is then resolved because, even though there is a many–many relation between causes in the world and sensory effects, some of the relations are weighted more than others in an optimally Bayesian way. The problem is solved de novo , without presupposing prior representational capability, because the system is supervised not by another agent, nor by itself, but by the very statistical regularities in the world it is trying to represent.
This key idea is then embellished in a number of different ways, all of which have bearing on attention and conscious perception.
The prediction error minimization mechanism sketched above is a general type of statistical building block that is repeated throughout levels of the cortical hierarchy such that there is recurrent message passing between levels (Mumford, 1992 ). The input to the system from the senses is conceived as prediction error and what cannot be predicted at one level is passed on to the next. In general, low levels of the hierarchy predict basic sensory attributes and causal regularities at very fast, millisecond, time scales, and more complex regularities, at increasingly slower time scales, are dealt with at higher levels (Friston, 2008 ; Kiebel et al., 2008 , 2010 ; Harrison et al., 2011 ). Prediction error is concurrently minimized across all levels of the hierarchy, and this unearths the states and parameters that represent the causal structure and depth of the world.
Contextual probabilities
Predictions at any level are subject to contextual modulation. This can be via lateral connectivity, that is, by predictions or hypotheses at the same hierarchical level, or it can be through higher level control parameters shaping low level predictions by taking slower time scale regularities into consideration. For example, the low level dynamics of birdsong is controlled by parameters from higher up pertaining to slower regularities about the size and strength of the bird doing the singing (Kiebel et al., 2010 ). Similarly, it may be that the role of gist perception is to provide contextual clues for fast classification of objects in a scene (Kveraga et al., 2007 ). The entire cortical hierarchy thus recapitulates the causal structure of the world, and the bigger the hierarchy the deeper the represented causal structure.
Empirical Bayes
For any appeal to Bayes, the question arises where do the priors come from (Kersten et al., 2004 )? One scheme for answering this, and evading charges of excessive subjectivity, is empirical Bayes where priors are extracted from hierarchical statistical learning (see, e.g., Casella, 1992 ). In the predictive coding scheme this does not mean going beyond Bayes to frequentism. (Empirical) Priors are sourced from higher levels in the hierarchy, assuming they are learned in an optimally Bayesian fashion (Friston, 2005 ). The notion of hierarchical inference is crucial here, and enables the brain to optimize its prior beliefs on a moment to moment basis. Many of these priors would be formed through long-term exposure to sensory contingencies through a creature’s existence but it is also likely that some priors are more hard-wired and instantiated over an evolutionary time-scale; different priors should therefore be malleable to different extents by the creature’s sensation.
Free energy
In its most general formulation, prediction error minimization is a special case of free energy minimization, where free energy (the sum of squared prediction error) is a bound on information theoretical surprise (Friston and Stephan, 2007 ). The free energy formulation is important because it enables expansion of the ideas discussed above to a number of different areas (Friston, 2010 ). Here, it is mainly the relation to prediction error minimization that will be of concern. Minimizing free energy minimizes prediction error and implicitly surprise. The idea here is that the organism cannot directly minimize surprise. This is because there is an infinite number of ways in which the organism could seek to minimize surprise and it would be impossibly expensive to try them out. Instead, the organism can test predictions against the input from the world and adjust its predictions until errors are suppressed. Even if the organism does not know what will surprise it, it can minimize the divergence between its expectations and the actual inputs encountered. A frequent objection to the framework is that prediction error and free energy more generally can be minimized by committing suicide since nothing surprises a dead organism. The response is that the moment an organism dies it experiences a massive increase in free energy, as it decomposes and is unable to predict anything (there is more to say on this issue, see Friston et al., in press ; there is also a substantial issue surrounding how these types of ideas can be reconciled with evolutionary ideas of survival and reproduction, for discussion see, Badcock, 2012 ).
Active inference
A system without agency cannot minimize surprise but only optimize its models of the world by revising those models to create a tight free energy bound on surprise. To minimize the surprise it needs to predict how the system’s own intervention in the world (e.g., movement) could change the actual input such as to minimize free energy. Agency, in this framework, is a matter of selectively sampling the world to ensure prediction error minimization across all levels of the cortical prediction hierarchy (Friston et al., 2009 , 2011 ). To take a toy example: an agent sees a new object such as a bicycle, the bound on this new sensory surprise is minimized, and the ensuing favored model of the world lets the agent predict how the prediction error landscape will change given his or her intervention (e.g., when walking around the bike). This prediction gives rise to a prediction error that is not minimized until the agent finds him or herself walking around the bike, hence the label “active inference.” If the initial model was wrong, then active inference fails to be this kind of self-fulfilling prophecy (e.g., it was a cardboard poster of a bike). Depending on the depth of the represented causal hierarchy this can give rise to very structured behavior (e.g., not eating all your food now even though you are hungry and instead keeping some for winter, based on the prediction this will better minimize free energy).
There is an intuitive seesaw dynamic here between minimizing the bound and actively sampling the world. It would be difficult to predict efficiently what kind of sampling would minimize surprise if the starting point was a very poor, inaccurate, bound on surprise. Similarly, insofar as selective sampling never perfectly minimizes surprise, new aspects of the world are revealed, which should lead to revisiting the bound on surprise. It thus pays for the system to maintain both perceptual and active inference.
Top-down and bottom-up
This framework comes with a re-conceptualization of the functional roles of the bottom-up driving signal from the senses, and the top-down or backward modulatory signal from higher levels. The bottom-up signal is not sensory information per se but instead just prediction error. The backward signal embodies the causal model of the world and the bottom-up prediction error is then essentially the supervisory feedback on the model (Friston, 2005 ). It is in this way the sensory input ensures the system is supervised, not by someone else nor by itself, but by the statistical regularities of the world.
The upshot is an elegant framework, which is primarily motivated by principled, philosophical and computational concerns about representation and causal inference. It is embellished in a number of ways that capture many aspects of sensory processing such as context-dependence, the role of prior expectations, the way perceptual states comprise sensory attributes at different spatiotemporal resolutions, and even agency. We shall appeal to all these elements as predictive coding is applied to attention and conscious perception.
Prediction Error and Precision
As discussed above, there are two related ways that prediction error can be minimized: either by changing the internal, generative model’s states, and parameters in the light of prediction error, or keeping the model constant and selectively sampling the world and thereby changing the input. Both ways enable the model to have what we shall here call accuracy : the more prediction error is minimized, the more the causal structure of the world is represented 2 .
So far, this story leaves out a crucial aspect of perceptual inference concerning variability of the prediction error. Prediction error minimization of the two types just mentioned assumes noise to be constant, and the variability of all prediction errors therefore the same. This assumption does not actually hold as noise or uncertainty is state dependent. Prediction error that is unreliable due to varying levels of noise in the states of the world is not a learning signal that will facilitate confident veridical revision of generative models or make it likely that selective sampling of the world is efficient. Prediction error minimization must therefore take variability in prediction error messaging into consideration – it needs to assess the precision of the prediction error.
Predictions are tested in sensory sampling: given the generative model a certain input is predicted where this input can be conceived as a distribution of sensory samples. If the actual distribution is different from the expected distribution, then a prediction error is generated. One way to assess a difference in distributions is to assess central tendency such as the mean. However, as is standard in statistical hypothesis testing, even if the means seem different (or not) the variability may preclude a confident conclusion that the two distributions are different (or not). Hence, any judgment of difference must be weighed by the magnitude of the variability – this is a requirement for trusting prediction error minimization.
The inverse of variability is the precision (inverse dispersion or variance) of the distribution. In terms of the framework used here, when the system “decides” whether to revise internal models in the light of prediction errors and to sample the world accordingly, those errors are weighted by their precisions. For example, a very imprecise (i.e., noisy, variable) prediction error should not lead to revision, since it is more likely to be a random upshot of noise for a given sensory attribute.
However, the rule cannot be simply that the more the precision the stronger the weight of the prediction error. Our expectations of precision are context dependent. For example, precisions in different sensory modalities differ (for an example, see Bays and Wolpert, 2007 ), and differ within the same modality in different contexts and for different sensory attributes. Sometimes it may be that one relatively broad, imprecise distribution should be weighed more than another narrower, precise distribution. Similarly, an unusually precise prediction error may be highly inaccurate as a result of under-sampling, for example, and should not lead to revision. In general, the precision weighting should depend on prior learning of regularities in the actual levels of noise in the states of the world and the system itself (e.g., learning leading to internal representations of the regularity that sensory precision tends to decline at dusk).
There is then a (second order) perceptual inference problem because the magnitude of precision cannot be measured absolutely. It must be assessed in the light of precision expectations . The consequence is that generative models must somehow embody expectations for the precision of prediction error, in a context dependent fashion. Crucially, the precision afforded a prediction has to be represented; in other words, one has to represent the known unknowns.
If precision expectations are optimized then prediction error is weighted accurately and replicates the precisions in the world. In terms of perceptual inference, the learning signal from the world will have more weight from units expecting precision, whereas top-down expectations will have more influence on perception when processing concerns units expecting a lot of imprecision; one’s preconceptions play a bigger role in making sense of the world when the signal is deemed imprecise (Hesselmann et al., 2010 ). This precision processing is thought to occur in synaptic error processing such that units that expect precision will have more weight (synaptic gain) than units expecting imprecision (Friston, 2009 ).
Given a noisy world and non-linear interactions in sensory input, first order statistics (prediction errors) and second order statistics (the precision of prediction errors) are then necessary and jointly sufficient for resolving the inverse problem. In what follows, the optimization of representations is considered in terms of both precision and accuracy , precision refers to the inverse amplitude of random fluctuations around, or uncertainty about, predictions; while accuracy (with a slight abuse of terminology) will refer to the inverse amplitude of prediction errors per se . Minimizing free energy or surprise implies the minimization of precise prediction errors; in other words, the minimization of the sum of squared prediction error and an optimal estimate of precision.
Using the terminology of accuracy and precision is useful because it suggests how the phenomena can come apart in a way that will help in the interpretation of the relation between consciousness and attention. It is a trivial point that precision and accuracy can come apart: a measurement can be accurate but imprecise, as in feeling the child’s fever with a hand on the forehead or it can be very precise but inaccurate, as when using an ill calibrated thermometer. This yields two broad dimensions for perceptual inference in terms of predictive coding: accuracy (via expectation of sensory input) and precision (via expectation of variability of sensory input). These can also come apart. Some of the states and parameters of an internal model can be inaccurate and yet precise (being confident that the sound comes from in front of you when it really comes from behind, Jack and Thurlow, 1973 ). Or they can be accurate and yet, imprecise (correctly detecting a faint sound but being uncertain about what to conclude given a noisy background).
With this in mind, assume now that conscious perception is determined by the prediction or hypothesis with the highest overall posterior probability – which is overall best at minimizing prediction error (this assumption is given support in the next section). That is, conscious perception is determined by the strongest “attractor” in the free energy landscape; where, generally speaking, greater precision leads to higher conditional confidence about the estimate and a deeper, more pronounced minimum in the free energy landscape.
On this assumption, precision expectations play a key role for conscious perception. We next note the proposal, which will occupy us in much of the following, that optimization of precision expectations maps on to attention (Friston, 2009 ). It is this mapping that will give substance to our understanding of the relation between attention and consciousness. It is a promising approach because precision processing, in virtue of its relation to accuracy, has the kind of complex relation to prediction error minimization that seems appropriate for capturing both the commonsense notion that conscious perception and attention are intertwined and also the notion that they are separate mechanisms (Koch and Tsuchiya, 2007 ; Van Boxtel et al., 2010 ).
We can usefully think of this in terms of a system such that, depending on context (including experimental paradigms in the lab), sensory estimates may be relatively accurate and precise, inaccurate and imprecise, accurate and imprecise, or inaccurate and precise. With various simplifications and assumptions, this framework can then be sketched as in Figure Figure1 1 .

Schematic of statistical dimensions of conscious perception . The accuracy afforded by first order statistics refers to the inverse amplitude of prediction errors per se , while the precision afforded by second order statistics refers to the inverse amplitude of random fluctuations around, or uncertainty about, predictions. This allows for a variety of different types of states such that in general, and depending on context, inattentive but conscious states would cluster towards the lower right corner and attentive but unconscious states would cluster towards the upper left; see main text for further discussion.
By and large, conscious perception will be found for states that are both accurate and precise but may also be found for states that are relatively accurate and yet imprecise, and vice versa . Two or more competing internal models or hypotheses about the world can have different constellations of precision and accuracy: a relatively inaccurate but precise model might determine conscious perception over a competing accurate but imprecise model, and vice versa . Similarly, a state can evolve in different ways: it can for example begin by being very inaccurate and imprecise, and thus not determining conscious perception but attention can raise its conditional confidence and ensure it does get to determine conscious content.
On this framework, it should then also be possible to speak to some of the empirical findings of dissociations between attention and consciousness. A case of attention without consciousness would be where precision expectations are high for a state but prediction error for it is not well minimized (expecting a precise signal, or, expecting inference to be relatively bottom-up driven). A case of consciousness without attention would be where prediction error is well minimized but where precision is relatively low (expecting signals to be variable, or, expecting inference to be relatively top-down driven). It is difficult to say precisely what such states would be like. For example, a conscious, inattentive state might have a noisy, fuzzy profile, such as gist perception may have (Bar, 2007 ). It is also possible that increased reliance on top-down, prior beliefs could in fact paradoxically sharpen the representational profile (Ross and Burr, 2008 ) 3 . In general, in both types of cases, the outcome would be highly sensitive to the context of the overall free energy landscape, that is, to competing hypotheses and their precision expectations.
Section “ Interpreting Empirical Findings in the Light of Attention as Precision Optimization ” will begin the task of interpreting some studies in the field according to these accuracy and precision dimensions. The next section, however, will provide some prima facie motivation for this overall framework.
Conscious Perception and Attention as Determined by Precise Prediction Error Minimization
In this section, conscious perception and attention are dealt with through the prism of predictive coding. Though the evidence in favor of this approach is growing (see the excellent discussion in Summerfield and Egner, 2009 ) much of this is still speculative 4 . The core idea is that conscious perception correlates with activity, spanning multiple levels of the cortical hierarchy, which best suppresses precise prediction error: what gets selected for conscious perception is the hypothesis or model that, given the widest context, is currently most closely guided by the current (precise) prediction errors 5 .
Conscious perception can then thought to be at the service of representing the world, and the currently best internal, generative model is the one that most probably represents the causal structure of the world. Predictions by other models may also be able to suppress prediction error, but less well, so they are not selected. Conversely, often some other, possible models could be even better at suppressing prediction error but if the system has not learnt them yet, or cannot learn them, it must make do with the best model it has.
It follows that the predictions of the currently best model can actually be rather inaccurate. However, if it has no better competitor then it will win and get selected for consciousness. Conscious perception can then be far from veridical, in spite of its representational nature. This makes room for an account of illusory and hallucinatory perceptual content, which is an important desideratum on accounts of conscious perception. These would be cases where, for different reasons, poor models are best at precisely explaining away incoming data only because their competitors are even poorer.
The job of the predictive coding system is to attenuate sensory input by treating it as information theoretical surprise and predicting it as perfectly as possible. As the surprise is attenuated, models should stop being revised and predictive activity progressively cease throughout the hierarchy. This seems consistent with repetition suppression (Grill-Spector et al., 2006 ) where neural activity ceases in response to expected input in a manner consistent with prediction error minimization (Summerfield et al., 2008 ; Todorovic et al., 2011 ). At the limit it should have consequences for conscious perception too. When all the surprise is dealt with, prediction and model revision should cease. If it is also impossible to do further selective sampling then conscious perception of the object in question should cease. This follows from the idea that what we are aware of is the “fantasy” generated by the way current predictions attenuate prediction error; if there is no prediction error to explain away, then there is nothing to be aware of. Presumably there is almost always some input to some consumer systems in the brain (including during dreaming) but conceivably something close to this happens when stabilized retinal images fade from consciousness (Ditchburn and Ginsborg, 1952 ). Because such stimuli move with eye and head movement predictive exploration of them is quickly exhausted.
Conscious perception is often rich in sensory attributes, which are neatly bound together even though they are processed in a distributed manner throughout the brain. The predictive coding account offers a novel approach to this “binding” aspect of conscious perception. Distributed sensory attributes are bound together by the causal inference embodied in the parameters of the generative model. The model assumes, for example, that there is a red ball out there so will predict that the redness and the bouncing object co-occur spatiotemporally. The binding problem (Treisman, 1996 ) is then dealt with by default: the system does not have to operate in a bottom-up fashion and first process individual attributes and then bind them. Instead, it assumes bound attributes and then predicts them down through the cortical hierarchy. If they are actually bound in the states of the world, then this will minimize prediction error, and they will be experienced as such.
It is a nice question here what it means for the model with the highest posterior probability to be “selected for consciousness.” We can only speculate about an answer but it appears that on the predictive coding framework there does not have to be a specific selection mechanism (no “threshold” module, cf. Dennett, 1991 ). When a specific model is the one determining the consciously perceived content it is just because it best minimizes prediction error across most levels of the cortical hierarchy – it best represents the world given all the evidence and the widest possible context. This is the model that should be used to selectively sample the world to minimize surprise in active inference. Competing but less probable models cannot simultaneously determine the target of active inference: the models would be at cross-purposes such that the system would predict more surprise than if it relies on one model alone (for more on the relation between attention and action, see Wu, 2011 ).
Though there remain aspects of consciousness that seem difficult to explain, such as the conscious content of imagery and dreaming, this overall approach to conscious perception does then promise to account for a number of key aspects of consciousness. The case being built here is mainly theoretical. There is not yet much empirical evidence for this link to conscious perception, though a recent dynamical causal modeling study from research in disorders of consciousness (vegetative states and minimally conscious states) suggests that what is required for an individual to be in an overall conscious state is for them to have intact connectivity consistent with predictive coding (Boly et al., 2011 ).
As we saw earlier, in the normal course of events, the system is helped in this prediction error minimization task by precision processing, which (following Feldman and Friston, 2010 ) was claimed to map on to attention such that attention is precision optimization in hierarchical perceptual inference. A prediction error signal will have a certain absolute dispersion but whether the system treats this as precise or not depends on its precision expectations, which may differ depending on context and beliefs about prior precision. Precise prediction errors are reliable signals and therefore, as described earlier, enable a more efficient revision of the model in question (i.e., a tighter bound and better active inference). If that model then, partly resulting from precision optimization, achieves the highest posterior probability, it will determine the content of conscious perception. This begins to capture the functional role often ascribed to attention of being a gating or gain mechanism that somehow optimizes sensory processing (Hillyard and Mangun, 1987 ; Martinez-Trujillo and Treue, 2004 ). As shall be argued now, it can reasonably account for a wider range of characteristics of attention.
Exogenous attention
Stimuli with large spatial contrast and/or temporal contrast (abrupt onset) tend to “grab” attention bottom-up, or exogenously. These are situations where there is a relatively high level of sensory input, that is, a stronger signal. Given an expectation that stronger signals have better signal to noise ratio (better precision), than weaker signals (Feldman and Friston, 2010 , p. 9; Appendix), error units exposed to such signals should thus expect high precision and be given larger gain. As a result, more precise prediction error can be suppressed by the model predicting this new input, which is then more likely to be the overall winner populating conscious experience. Notice that this account does not mention expectations about what the signal stems from, only about the signal’s reliability. Also notice that this account does not guarantee that what has the highest signal to noise ratio will end up populating consciousness, it may well be that other models have higher overall confidence or posterior probability.
Endogenous attention
Endogenous attention is driven more indirectly by probabilistic context. Beginning with endogenous cueing, a central cue pointing left is itself represented with high precision prediction error (it grabs attention) and in the parameters of the generative model this cue representation is related to the representation of a stimulus to the left, via a learned causal link. This reduces uncertainty about what to predict there (increases prior probability for a left target) and it induces an expectation of high precision for that region. When the stimulus arrives, the resulting gain on the error units together with the higher prior help drive a higher conditional confidence for it, making it likely it is quickly selected for conscious perception.
The idea behind endogenous attention is then that it works as an increase in baseline activity of neuronal units encoding beliefs about precision. There is evidence that such increase in activity prior to stimulus onset is specific to precision expectations. The narrow distributions associated with precise processing tell us that in detection tasks the precision-weighted system should tend to respond when and only when the target appears. And indeed such baseline increases do bias performance in favor of hits and correct rejections (Hesselmann et al., 2010 ). In contrast, if increased baseline activity had instead been a matter of mere accumulation of evidence for a specific stimulus (if it had been about accuracy and not precision), then the baseline increase should instead have biased toward hits and false alarms.
A recent paper directly supports the role of endogenous attention as precision weighting (Kok et al., 2011 ). As we have seen, without attention, the better a stimulus is predicted the more attenuated its associated signal should be. Attention should reverse this attenuation because it strengthens the prediction error. However, attention depends on the predictability of the stimulus: there should be no strong expectation that an unpredicted stimulus is going to be precise. So there should be less attention-induced enhancement of the prediction error for unpredicted stimuli than for better predicted stimuli. Using fMRI, Kok et al. very elegantly provides evidence for this interaction in early visual cortex (V1).
In more traditional cases of endogenous attention (e.g., the individual deciding herself to attend left) the cue can be conceived as a desired state, for example, that something valuable will be spotted to the left. This would then generate an expectation of precision for that region such that stimuli located there are more likely to be detected. Endogenous attention of this sort has a volitional aspect: the individual decides to attend and acts on this decision. Such agency can range from sensorimotor interaction and experimentation to a simple decision to fixate on something. This agential aspect suggests that part of attention should belong with active inference (selective sampling to minimize surprise). The idea here would be that the sampling is itself subject to precision weighting. This makes sense since the system will not know if its sampling satisfies expectations unless it can assess the variability in the sampling. Without such an assessment, the system will not know whether to keep sampling on the basis of a given model or whether the bound on the model itself needs to be re-assessed. In support of this, there is emerging evidence that precision expectations are also involved in motor behavior (Brown et al., 2011 ).
Biased competition
An elegant approach to attention begins with the observation that neurons respond optimally to one object or property in their receptive field so that if more than one object is present, activity decreases unless competition between them is resolved. The thought is that attention can do this job, by biasing one interpretation over another (Desimone and Duncan, 1995 ). Attention is thus required to resolve ambiguities of causal inference incurred by the spatial architecture of the system. Accordingly, electrophysiological studies show decreased activity when two different objects are present in a neuron’s receptive field, and return to normal levels of activity when attention is directed toward one of them (Desimone, 1998 ).
The predictive coding framework augmented with precision expectations should be able to encompass biased competition. This is because, as mentioned, precision can modulate perceptual inference when there are two or more competing, and perhaps equally accurate, models. Indeed, computational simulation shows precision-weighted predictive coding can play such a biasing role in a competitive version of the Posner paradigm where attention is directed to a cued peripheral stimulus rather than a competing non-cued stimulus. A central cue thus provides a context for the model containing the cued stimulus as a hidden cause. This drives a high precision expectation for that location, which ensures relatively large gain, and quicker response times, when those error units are stimulated. This computational model nicely replicates psychophysics and electrophysiological findings (Feldman and Friston, 2010 , pp. 14–15).
Attentional competition is then not a matter somehow of intrinsically limited processing resources or of explicit competition. It is a matter of optimal Bayesian inference where only one model of the causal regularities in the world can best explain away the incoming signal, given prior learning, and expectations of state-dependent levels of noise.
Binding of sensory attributes by a cognitive system was mooted above as a natural element of predictive coding. Attention is also thought to play a role for binding (Treisman and Gelade, 1980 ; Treisman, 1998 ) perhaps via gamma activity (Treisman, 1999 ) such that synchronized neurons are given greater gain. Again, this can be cast in terms of precision expectations: sensory attributes bound to the same object are mutually predictive and so if the precision-weighted gain for one is increased it should increase for the other too. Though this is speculative, the predictive coding framework could here elucidate the functional role of increased gamma activity and help us understand how playing this role connects to attention and conscious perception.
Perhaps we should pause briefly and ask why we should adopt this framework for attention in particular – what does it add to our understanding of attention to cast it in terms of precision expectations? A worry could be that it is more or less a trivial reformulation of notions of gain, gating, and bias, which has long been used to explicate attention in a more or less aprioristic manner. The immediate answer is that this account of attention goes beyond mere reformulations of known theories, not just because its basic element is precision, but also because it turns on learning precision regularities in the world so different contexts will elicit different precision expectations. This is crucial because optimization of precision is context dependent and thus requires appeal to just the kind of predictive framework used here.
There is also a more philosophical motivation for adopting this approach. Normally, an account of attention would begin with some kind of operational, conceptual analysis of the phenomenon: attention has to do with salience, with some kind of selection of sensory channels, resource limitations, and so on. Then the evidence is consulted and theories formulated about neural mechanisms that could underpin salience and selection etc. This is a standard and fruitful approach in science. But sometimes taking a much broader approach gives a better understanding of the nature of the phenomenon of interest and its relation to other phenomena ( cf . explanation by unification, Kitcher, 1989 ). In our case, a very general conception of the fundamental computational task for the brain defines two functional roles that must be played: estimation of states and parameters, and estimation of precisions. Without beginning from a conceptual analysis of attention, we then discover that the element of precision processing maps on well to the functional role we associate with attention. This discovery tells us something new about the nature of attention: the reason why salience and selection of sensory channels matter, and the reason why there appears to be resource limitations on attention, is that the system as such must assess precisions of sensory estimates and weight them against each other.
Viewing attention from the independent vantage point of the requirements of predictive coding also allows us to revise the concept of attention somewhat, which can often be fruitful. For example, there is no special reason why attention should always have to do with conscious perception, given the ways precision and accuracy can come apart; that is, there may well be precision processing – attention – outside consciousness. The approach suggests a new way for us to understand how attention and perception can rely on separate but related mechanisms. This is the kind of issue to which we now turn.
Interpreting Empirical Findings in the Light of Attention as Precision Optimization
The framework for conscious perception sketched in Section “ Prediction Error and Precision ” (see Figure Figure1) 1 ) implied that studies of the relation between consciousness and attention can be located according to the dimensions of accuracy and precision. We now explore if this implication can reasonably be said to hold for a set of key findings concerning: inattentional blindness, change blindness, the effects of short term and sustained covert attention on conscious perception, and attention to unconscious stimuli.
The tools for interpreting the relevant studies must be guided by the properties of predictive coding framework we have set out above, so here we briefly recapitulate: (1) even though accuracy and precision are both necessary for conscious perception, it does not follow that the single most precise or the most accurate estimate in a competing field of estimates will populate consciousness: that is determined by the overall free energy landscape. For example, it is possible for the highest overall posterior probability to be determined by an estimate having high accuracy and relatively low precision even if there is another model available that has relatively low accuracy yet high precision, and so on. (2) Attention in the shape of precision expectation modulates prediction error minimization subject to precisions predicted by the context, including cues and competing stimuli; it can do this for prediction errors of different accuracies. (3) Precision weighting only makes sense if weights sum to one so that as one goes up the others must go down. Similarly, as the probability of one model goes up the probability of other models should go down – the other models are explained away if one model is able to account for and suppress the sensory input. This gives rise to model competition. (4) Conscious experience of unchanging, very stable stimuli will tend to be suppressed over time, as prediction error is explained away and no new error arises. (5) Agency is active inference: a model of the agent’s interaction with the world is used to selectively sample the world such as to minimize surprise. This also holds for volitional aspects of attention, such as the agency involved in endogenous attention to a spatial location.
The aim now is to use these properties of predictive coding to provide a coherent interpretation of the set of very different findings on attention and consciousness.
Types of inattentional blindness
The context for a stimulus can be a cue or an instruction or other sensory information, or perhaps a decision to attend. Various elements of this context can give a specific generative model two advantages: it can increase priors for its states and parameters (for this part of the view, see also Rao, 2005 ) and it can bias selection of that model via precision weighting. When the target stimulus comes, attention has thus already given the model for that stimulus a probabilistic advantage. If in contrast the context is invalid (non-predictive) and a different target stimulus occurs, the starting point for the model predicting it can be much lower both in terms of prior probability and in terms of precision expectation. If this lower starting point is sufficiently low, and if the invalidly contextualized stimulus is not itself strongly attention grabbing (is not abrupt in some feature space such as having sharp contrast or temporal onset), then “the invalid target may never actually be perceived” (Feldman and Friston, 2010 , pp. 9–10).
This is then what could describe forms of inattentional blindness where an otherwise visible stimulus is made invisible by attending to something at a different location: an attentional task helps bias one generative model over models for unexpected background or peripheral stimuli. A very demanding attentional task would have very strong bias from precision weighting, and correspondingly the weight given to other models must be weakened. This could drive overall posterior probability below selection for consciousness, such that not even the gist of, for example, briefly presented natural scenes is perceived.
It is natural to conclude in such experiments that attention is a necessary condition for conscious perception since unattended stimuli are not seen, and as soon as they are seen performance on the central task decreases (Cohen et al., 2011 ). This is right in the sense that any weighting of precision to the peripheral or background stimulus must go with decreased weight to the central task. However, the more fundamental truth here is that in a noisy world precision weighting is necessary for conscious perception so that at the limit, where noise expectations are uniform, there could be conscious perception even though attention plays very little actual role.
When inattentional blindness is less complete, the gist of briefly presented natural scenes can be perceived (see, Van Boxtel et al., 2010 ). This is consistent with relatively low precision expectation since gist is by definition imprecise. So in this case some, but relatively little prediction error is allowed through for the natural scene, leaving only little prediction error to explain away. It seems likely that this could give rise to gist rather than full perception. However, the distinction between gist and full perception is not well understood and there are more specific views on gist perception, also within the broad predictive coding framework (Bar, 2003 ).
In some cases of inattentional blindness, large and otherwise very salient stimuli can go unnoticed. Famously, when counting basketball passes a gorilla can be unseen, and when chasing someone a nearby fistfight can be unseen (Simons and Chabris, 1999 ; Chabris et al., 2011 ). This is somewhat difficult to explain because endogenous attention as described so far should raise the baseline for precision expectation for a specific location such that any stimulus there, whether it is a basketball pass or a gorilla, should be more likely to be perceived. A smaller proportion of participants experience this effect, so it does in fact seem harder to induce blindness in this kind of paradigm than paradigms using central–peripheral or foreground-background tasks. For those who do have inattentional blindness under these conditions, the explanation could be high precision expectations for the basketball passes specifically, given the context of the passes that have occurred before the gorilla enters. This combines with the way this precision error has driven up the conditional confidence of the basketball model, explaining away the gorilla model, even if the latter is fed some prediction error. This more speculative account predicts that inattentional blindness should diminish if the gorilla, for example, occurs at the beginning of the counting task.
This is then a way to begin conceptualizing feature- and object-based based attention instead of purely spatial attention. Van Boxtel et al. ( 2010 ) suggest that in gorilla type cases the context provided by the overall scene delivers a strong gist that overrides changes that fit poorly with it: “subjects do perceive the gist of the image correctly, interfering with detection of a less meaningful change in the scene as if it was filled in by the gist.” The predictive coding approach can offer an explanation of this kind of interference in probabilistic terms.
A further aspect can be added to this account of inattentional blindness. Attending, especially endogenous attending, is an activity. As such, performing an attention demanding task is a matter of active inference where a model of the world is used to selectively sample sensory input to minimize surprise. This means that high precision input are expected and sampled on the basis of one, initial (e.g., “basketball”) model, leaving unexpected input such as the occurrence of a gorilla with low weighting. Since the active inference required to comply with an attentional task must favor one model in a sustained way, blindness to unexpected stimuli follows.
The benefit of sustained attention viewed as active inference is then that surprise can be minimized with great precision, given an initial model’s states and parameters. On the other hand, the cost of sustained attention is that the prediction error landscape may change during the task; increasing the free energy and making things evade consciousness.
It can thus be disadvantageous for a system to be stuck in active inference and neglecting to revisit the bound on surprise by updating the model (e.g., if the gorilla is real and angry). Perhaps the reason attention can be hard to maintain is that to avoid such disadvantage the system continually seeks, perhaps via spontaneous fluctuations, to alternate between perceptual and active inference. Minor lapses of attention (e.g., missing a pass) could thus lead to some model revision and conscious perception; if the model revision has relatively low precision it may just give rise to gist perception (e.g., “some black creature was there”).
It is interesting here to speculate further that the functional role of exogenous attention can be to not only facilitate processing of salient stimuli but in particular to make the system snap out of active inference, which is often associated with endogenous attention, and back into revision of its generative model. Exogenous and endogenous attention seem to have opposing functional roles in precision optimization.
There remains the rather important and difficult question whether or not the unseen stimulus is in fact consciously perceived but not accessible for introspective report, or whether it is not consciously perceived at all; this question relates to the influential distinction between access consciousness and phenomenal consciousness (Block, 1995 , 2008 ). To some, this question borders on the incomprehensible or at least untestable (Cohen and Dennett, 2011 ), and there is agreement it cannot be answered directly (e.g., by asking participants to report). Instead some indirect, abductive answer must be sought. We cannot answer this question here but we can speculate that the common intuition that there is both access and phenomenal consciousness is fueled by the moments of predictive coding such that (i) access consciousness goes with active inference (i.e., minimizing surprise though agency, which requires making model parameters and states available to control systems), and (ii) phenomenal consciousness goes with perceptual inference (i.e., minimizing the bound on surprise by more passively updating model parameters and states).
If this is right, then a prediction is that in passive viewing, where attention and active inference is kept as minimal as possible, there should be more possibility of having incompatible conscious percepts at the same time, since without active inference there is less imperative to favor just one initial model. There is some evidence for this in binocular rivalry where the absence of attention seems to favor fusion (Zhang et al., 2011 ).
Overall, some inroads on inattentional blindness can be made by an appeal to precision expectations giving the attended stimulus a probabilistic advantage. A more full, and speculative, explanation conceives attention in agential terms and appeals to the way active inference can lead to very precise but eventually overall inaccurate perceptual states.
Change blindness
These are cases where abrupt and scene-incongruent changes like sudden mudsplashes attract attention and make invisible other abrupt but scene-congruent changes like a rock turning into a log or an aircraft engine going missing (Rensink et al., 1997 ). Only with attention directed at (or on repeated exposures grabbed by) the scene-congruent change will it be detected. This makes sense if the distractor (e.g., mudsplashes) has higher signal strength than the masked stimuli because, as we saw, there is a higher precision expectation for stronger signals. This weights prediction error for a mudsplash model rather than for a natural scenery model with logs or aircrafts. Even if both models are updated in the light of their respective prediction errors from the mudsplashes and the rock changing to the log, the mudsplash model will have higher conditional confidence because it can explain away precisely a larger part of the bottom-up error signal.
More subtly, change blindness through attention grabbing seems to require that the abrupt stimuli activate a competing model of the causes in the world. This means that the prediction error can be relevant to the states and parameters of one of these models. Thus, the mudsplashes mostly appear to be superimposed on the original image, which activates a model with parameters for causal interaction between mudsplashes and something like a static photo. In other words, the best explanation for the visual input is the transient occlusion or change to a photo, where, crucially, we have strong prior beliefs that photographs do not change over short periods of time. This contrasts with the situation prior to the mudsplashes occurring where the model would be tuned more to the causal relations inherent in the scene itself (that is, the entire scene is not treated as a unitary object that can be mudsplashed). With two models, one can begin to be probabilistically explained away by the other: as the posterior probability of the model that treats the scene as a unitary object increases, the probability of the model that treats it as composite scene will go down. Once change blindness is abolished, such that both mudsplashes and scene changes are seen, a third (“Photoshop”) model will have evolved on which individual components can change but not necessarily in a scene-congruent manner. All this predicts that there should be less change blindness for mudsplashes on dynamic stimuli such as movies because the causal model for such stimuli has higher accuracy; it also predicts less blindness if the mudsplashes are meaningful in the original scene such that competition between models is not engendered.
For some scene changes it is harder to induce change blindness. Mudsplashes can blind us when a rock in the way of a kayak changes into a log, but blinds us less when the rock changes into another kayak (Sampanes et al., 2008 ). This type of situation is often dealt with in terms of gist changes but it is also consistent with the interpretation given above. The difference between a log and another kayak in the way of the kayak is in the change in parameters of the model explaining away the prediction error. The change from an unmoving object (rock) to another unmoving object (log) incurs much less model revision than the change to a moving, intentional object (other kayak): the scope for causal interaction between two kayaks is much bigger than for one kayak and a log. The prediction error is thus much bigger for the latter, and updating the model to reflect this will increase its probability more, and make blindness less likely.
A different type of change blindness occurs when there is no distractor but the change is very slow and incremental (e.g., Simons et al., 2000 ), such as a painting where one part changes color over a relatively long period of time. Without attention directed at the changing property, the change is not noted. In this case it seems likely that each incremental change is within the expected variability for the model of the entire scene. When attention is directed at the slowly changing component of the scene, the precision expectation and thus the weighting goes up, and it is more likely that the incremental change will generate a prediction error. This is then an example of change blindness due to imprecise prediction error minimization. If this is right, a prediction is that change of precision expectation through learning, or individual differences in such expectations, should affect this kind of change blindness.
Short term covert attention enhances conscious perception
If a peripheral cue attracts covert attention to a grating away from fixation, then conscious experience of its contrast is enhanced (Carrasco et al., 2004 ). Similar effects are found for spatial frequency and gap size (Gobell and Carrasco, 2005 ). In terms of precision, the peripheral cue induces a high precision expectation for the cued region, which increases the weighting for prediction error from the low contrast grating placed there. Specifically, the expectation will be for a stimulus with an improved signal to noise ratio, that is, a stronger signal. This then seems to be a kind of self-fulfilling prophecy: an expectation for a strong bottom-up signal causing a stronger error signal. The result is that the world is being represented as having a stronger, more precise signal than it really has, and this is then reflected in conscious perception.
From this perspective, the attentional effect is parasitic on a causal regularity in the world. Normally, when attention is attracted to a region there will indeed be a high signal to noise event in that region. This is part of the prediction error minimization role for attention described above. If this regularity did not hold, then exogenous attention would be costly in free energy. In this way the effect from Carrasco’s lab is a kind of attentional visual illusion. A further study provides evidence for just this notion of an invariant relation between cue strength and expectation for subsequent signal strength: the effect is weakened as the cue contrast decreases (Fuller et al., 2009 ). The cue sets up an expectation for high signal strength (i.e., high precision) in the region and so it makes sense that the cue strength and the expectation are tied together. It is thus an illusion because a causal regularity about precision is applied to a case where it does not in fact hold. If it is correct that this effect relies on learned causal regularities, then it can be predicted that the effect should be reversible through learning, such that strong cues come to be associated with expectations for imprecise target stimuli and vice versa 6 .
At the limit, this paradigm provides an example of attention directed at subthreshold stimuli, and thereby enabling their selection into conscious perception (e.g., 3.5% contrast subthreshold grating is perceived as a 6% contrast threshold grating (Carrasco et al., 2004 ). This shows nicely the modulation by precision weighting of the overall free energy landscape: prediction error, which initially is so imprecise that it is indistinguishable from expected noise can be up-weighted through precision expectations such that the internal model is eventually revised to represent it. Paradoxically, however, here what we have deemed an attentional illusion of stimulus precision facilitates veridical perception of stimulus occurrence.
It is an interesting question if the self-fulfilling prophecy suggested to be in play here is always present under attention, such that attention perpetually enhances phenomenology. In predictive coding terms, the answer is probably “no.” The paradigm is unusual in the sense that it is a case of covert attention, which stifles normal active inference in the form of fixation shifts. If central fixation is abolished and the low contrast grating is fixated, the bound on free energy is again minimized, and this time the error between the model and the actual input from the grating is likely to override the expectation for a strong signal.
This attentional illusion works for exogenous cueing but also for endogenous cueing (Liu et al., 2009 ), where covert endogenous attention is first directed at a peripheral letter cue, is sustained there, and then enhances the contrast of the subsequent target grating at that location. There does not seem to be any studies of the effect of endogenous attention that is entirely volitional and not accompanied by high contrast cues in the target region (even Ling and Carrasco, 2006 has high contrast static indicators at the target locations).
From the point of view of predictive coding, the prediction is then that there will be less enhancing effect of such pure endogenous attention since the high precision expectation (increased baseline) in this case is not induced via a learned causal regularity linking strong signal cues to strong signal targets.
A more general prediction follows from the idea that attention is driven by the (hyper-) prior that cues with high signal strength have high signal to noise ratio. It may be possible to revert this prior through learning such that attention eventually is attracted by low strength cues and stronger cues are ignored. In support of this prediction, there is evidence that some hyperpriors can be altered, such as the light from above prior (Morgenstern et al., 2011 ).
This attentional effect is then explained by precision optimization leading to an illusory perceptual inference. It is a case of misrepresented high precision combined with relatively low accuracy.
Sustained covert attention diminishes conscious perception and enhances filling-in
In Troxler fading (Troxler, 1804 ) peripheral targets fade out of conscious perception during sustained central fixation. If attention but not fixation is endogenously directed at one type of sensory attribute, such as the color of some of the peripheral stimuli, then those stimuli fade faster than the unattended stimuli (Lou, 1999 ).
It is interesting that here attention seems to diminish conscious perception whereas in the cases discussed in the previous section it enhances it. A key factor here is the duration of trials: fading occurs after several seconds and enhancement is seen in trials lasting only 1–2 s. This temporal signature is consistent with predictive coding insofar as when the prediction error from a stimulus is comprehensively suppressed and no further exploration is happening (since active inference is subdued due to central fixation during covert attention) probability should begin to drop. This follows from the idea that what drives conscious perception is the actual process of suppressing prediction error. It translates to the notion that the system expects that the world cannot be unchanging for very long periods of time (Hohwy et al., 2008 ).
In Troxler fading there is an element of filling-in as the fading peripheral stimuli are substituted by the usually gray background. This filling-in aspect is seen more dramatically if the background is dynamic (De Weerd et al., 2006 ): as sustained attention diminishes perception of the peripheral target stimuli, it also amplifies conscious perception by illusory filling-in. A similar effect is seen in motion induced blindness (MIB). Here peripheral targets fade when there is also a stimulus of coherently moving dots, and the fading of the peripheral dots happens faster when they are covertly attended (Geng et al., 2007 ; Schölvinck and Rees, 2009 ).
The question is then why attention conceived as precision weighting should facilitate the fading of target stimuli together with enhancing filling-in in these cases. In Troxler fading with filling-in of dynamic background as well as in MIB there is an element of model competition. In MIB, there is competition between a model representing the coherently moving dots as a solid rotating disk, which if real would occlude the stationary target dots, and a model representing isolated moving dots, which would not occlude the target dots. The first model wins due to the coherence of the motion. An alternative explanation is that there is competition between a model on which there is an error (a “perceptual scotoma”) in the visual system, and a model where there is not; in the former case, it would make sense for the system to fill-in (New and Scholl, 2008 ). In the Troxler case with a dynamic background, there is competition between models representing the world as having vs. not having gaps at the periphery, with the latter tending to win. Sustained attention increases the precision weighting for all prediction error from the attended region, that is, for both the target stimuli and the context in which they are shown (i.e., the dynamic background or, as in MIB, the coherently moving foreground). This context is processed not only at that region but also globally in the stimulus array and this would boost the confidence that it fills the locations of the target stimuli. This means that as the prediction error for the peripheral target stimuli is explained away, the probabilistic balance might tip in favor of the model that represents the array as having an unbroken background, or a solid moving foreground (or a perceptual scotoma).
It is thus possible to accommodate these quite complex effects of covert attention within the notion of attention as precision expectation. On the one hand, exogenous cues can engender high precision expectations that can facilitate target perception, and, on the other hand these expectations can facilitate filling-in of the target location. At the same time, covert attention stifles active inference and engenders a degree of inaccuracy.
Exogenous attention to invisible stimuli
During continuous flash suppression, perceptually suppressed images of nudes can attract attention in the sense that they function as exogenous cues in a version of the Posner paradigm (Jiang et al., 2006 ). This shows that a key attentional mechanism works in the absence of conscious perception. When there are competing models, conscious perception is determined by the model with the highest posterior probability. It is conceivable that though the nude image is a state in a losing model it may still induce precision-related gain for a particular region. In general, in the processing of emotional stimuli, there is clear empirical evidence to suggest that fast salient processing (that could mediate optimization of precision expectations) can be separated from slower perceptual classification (Vuilleumier et al., 2003 ). Evidence for this separation rests on the differences in visual pathways, in terms of processing speeds and spatial frequencies that may enable the salience of stimuli to be processed before their content. Even though a high precision expectation could thus be present for the region of the suppressed stimulus, it is possible for the overall prediction error landscape to not favor the generative model for that stimulus over the model for the abruptly flashing Mondrian pattern in the other eye. The result is that the nude image is not selected for conscious perception but that there nevertheless is an expectation of high precision for its region of the visual field, explaining the effect.
Concluding Remarks
The relation between conscious perception and attention is poorly understood. It has proven difficult to connect the two bodies of empirical findings, based as they are on separate conceptual analyses of each of these core phenomena, and fit them into one unified picture of our mental lives. In this kind of situation, it can be useful to instead begin with a unified theoretical perspective, apply it to the phenomena at hand and then explore if it is possible to reasonably interpret the bodies of evidence in the light of the theory.
This is the strategy pursued here. The idea that the brain is a precision-weighted hypothesis tester provides an attractive vision of the relationship. Because the states of the world have varying levels of noise or uncertainty, perceptual inference must be modulated by expectations about the precisions of the sensory signal (i.e., of the prediction error). Optimization of precision expectations, it turns out (Feldman and Friston, 2010 ), fits remarkably well the functional role often associated with attention. And the perceptual inference which, thus modulated by attention, achieves the highest posterior probability fits nicely with being what determines the contents of conscious perception.
In this perspective, attention and conscious perception are distinct but naturally connected in a way that allows for what appears to be reasonable and fruitful interpretations of some key empirical studies of them and their relationship. Crudely, perception and attention stand to each other as accuracy and precision, statistically speaking, stand to each other. We have seen that this gives rise to reasonably coherent interpretations of specific types of experimental paradigms. Further mathematical modeling and empirical evidence is needed to fully bring out this conjecture, and a number of the interpretations were shown to lead to testable predictions.
To end, I briefly suggest this unifying approach also sits reasonably well with some very general approaches to attention and perception.
From a commonsense perspective, endogenous and exogenous attention have different functional roles. Endogenous attention can only be directed at contents that are already conscious (how can I direct attention to something I am not conscious of?) and when states of affairs grab exogenous attention they thereby become conscious (if I fail to become aware of something then how could my attention have been grabbed?). This is an oversimplification, as can be seen from the studies reviewed above. The mapping of conscious perception and attention onto the elements of predictive coding can explain the commonsense understanding of their relationship but also why it breaks down. Normally endogenous attention is directed at things we already perceive so that no change is missed, i.e., more precision is expected and the gain is turned up. But precision gain itself is neutral on the actual state of affairs, it just makes the system more sensitive to prediction error, so if we direct attention at a location that seems empty but that has a subthreshold stimulus we are still more likely to spot it in the end. Conversely, even if precision expectations are driven up by an increase in signal strength somewhere, and attention in this sense is grabbed, it does not follow that this signal must drive conscious perception. A competing model may as a matter of fact have higher probability.
It is sometimes said that a good way to conceive of conscious perception and attention is in terms of the former as a synthesizer that allows us to make sense of our otherwise chaotic sensory input, and the latter as an analyzer that allows us to descend from the overall synthesized picture and focus on a few more salient things (Van Boxtel et al., 2010 ). The predictive coding account allows this sentiment: prediction error minimization is indeed a way of solving the inverse problem of figuring out what in the world caused the sensory input, and attention does allow us to weight the least uncertain parts of this signal. The key insight from this perspective is however that though these are distinct neural processes they are both needed to allow the brain to solve its inverse problem. But when there are competing models, they can work against each other, and conscious perception can shift between models as precisions and bounds are optimized and the world selectively sampled.
Perhaps the most famous thing said about attention is from James:
Everyone knows what attention is. It is the taking possession by the mind, in clear and vivid form, of one out of what seem several simultaneously possible objects or trains of thought. Focalization, concentration, of consciousness are of its essence. It implies withdrawal from some things in order to deal effectively with others, and is a condition which has a real opposite in the confused, dazed, scatter-brained state which in French is called distraction , and Zerstreutheit in German (James, 1890 , Vol. I, pp. 403–404).
The current proposal is that “attention is simply the process of optimizing precision during hierarchical inference” (Friston, 2009 , p. 7). This does not mean the predictive coding account of attention stands in direct opposition to the Jamesian description. It is a more accurate, reductive and unifying account of the mechanism underlying parts of the phenomenon James is trying to capture: James’ description captures many of the aspects of endogenous attention and model competition that are discussed in terms of precision in this paper.
The sentiment that attention is intimately connected with perception in a hypothesis testing framework was captured very early on by Helmholtz. He argued, for example, that binocular rivalry is an attentional effect but he explicated attention in terms of activity, novelty, and surprise, which is highly reminiscent of the contemporary predictive coding framework:
The natural unforced state of our attention is to wander around to ever new things, so that when the interest of an object is exhausted, when we cannot perceive anything new, then attention against our will goes to something else. […] If we want attention to stick to an object we have to keep finding something new in it, especially if other strong sensations seek to decouple it (Helmholtz, 1860 , p. 770; translated by JH).
Helmholtz does not here mention precision expectations but they find a natural place in his description of attention’s role in determining conscious content: precision expectations enable attention to stick, where sticking helps, and to wander more fruitfully too.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Thanks to Karl Friston, Tim Bayne, and the reviewers for very helpful comments and suggestions. This research is supported by the Australian Research Council.
1 In addition to perceptual forms of consciousness there is also a live debate, set aside here, about non-perceptual forms of consciousness, such as conceptual thought (Bayne and Montague, 2011 ).
2 There is a simplification here: surprise has both accuracy and complexity components, such that minimizing surprise or free energy increases accuracy while minimizing complexity. This ensures the explanations for sensory input are parsimonious and will generalize to new situations; c.f., Occam’s razor.
3 There is also a very good question here about how this kind of confidence assessment fits with the psychological confidence of the organism, which appears a defining feature of consciousness, and which is often assessed in confidence ratings. (Thanks to a reviewer for raising this issue).
4 A further disclaimer: the speculation that conscious perception is a product of accuracy and precision in predictive coding is a limited speculation about an information processing mechanism. It is not a speculation about why experience is conscious rather than not conscious – predictive coding can after all be implemented in unconscious machines. The mystery of consciousness will remain untouched.
5 This claim depends on optimal Bayesian inference actually being able to recapitulate the causal structure of the world. Here we bracket for philosophical debate the fact that this assumption breaks down for perfect skeptical scenarios, such as Cartesian deceiving demons or evil scientists manipulating brains in vats, where minimizing free energy does not reveal the true nature of the world. We also bracket deeper versions of the problem of induction, such as the new riddle of induction (Goodman, 1955 ). though we note that when two hypotheses are equally good at predicting new input the free energy principle prefers the one with the smallest complexity cost.
6 It is a tricky question whether or not this attentional effect is then explained without appealing to “mental paint” (Block, 2010 ), and whether it is therefore a challenge to representationalism about conscious perception. Precision optimization is an integral part of perceptual inference, which is all about representing the causal structure of the world. As such the explanation is representational. But it concerns precision, which is an often neglected aspect of representation: the representationalism assumed here allows that a relatively accurate representation can fail to optimize precision. What attention itself affords is improved precision, not accuracy (see Prinzmetal et al., 1997 ).
- Badcock P. B. (2012). Evolutionary systems theory: a unifying meta-theory of psychological science . Rev. Gen. Psychol. 16 , 10–23 10.1037/a0026381 [ CrossRef ] [ Google Scholar ]
- Bar M. (2003). A cortical mechanism for triggering top-down facilitation in visual object recognition . J. Cogn. Neurosci. 15 , 600–609 10.1162/089892903321662976 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Bar M. (2007). The proactive brain: using analogies and associations to generate predictions . Trends Cogn. Sci. (Regul. Ed.) 11 , 280–289 10.1016/j.tics.2007.05.005 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Bayne T. (2010). The Unity of Consciousness . Oxford: Oxford University Press [ Google Scholar ]
- Bayne T., Montague M. (2011). Cognitive Phenomenology . Oxford: Oxford University Press [ Google Scholar ]
- Bays P. M., Wolpert D. M. (2007). Computational principles of sensorimotor control that minimize uncertainty and variability . J. Physiol. (Lond.) 578 , 387–396 10.1113/jphysiol.2006.120121 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Block N. (1995). On a confusion about a function of consciousness . Behav. Brain Sci. 18 , 227–287 10.1017/S0140525X00038188 [ CrossRef ] [ Google Scholar ]
- Block N. (2008). Consciousness, accessibility, and the mesh between psychology and neuroscience . Behav. Brain Sci. 30 , 481–499 [ PubMed ] [ Google Scholar ]
- Block N. (2010). Attention and mental paint . Philos. Issues 20 , 23–63 10.1111/j.1533-6077.2010.00177.x [ CrossRef ] [ Google Scholar ]
- Boly M., Garrido M. I., Gosseries O., Bruno M.-A., Boveroux P., Schnakers C., Massimini M., Litvak V., Laureys S., Friston K. (2011). Preserved feedforward but impaired top-down processes in the vegetative state . Science 332 , 858–862 10.1126/science.1202043 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Brown H., Friston K. J., Bestmann S. (2011). Active inference, attention and motor preparation . Front. Psychol. 2 :218. 10.3389/fpsyg.2011.00218 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Carrasco M., Ling S., Read S. (2004). Attention alters appearance . Nat. Neurosci. 7 , 308–313 10.1038/nn1194 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Casella G. (1992). Illustrating empirical Bayes methods . Chemometr. Intell. Lab. Syst. 16 , 107–125 10.1016/0169-7439(92)80050-E [ CrossRef ] [ Google Scholar ]
- Chabris C. F., Weinberger A., Fontaine M., Simons D. J. (2011). You do not talk about fight club if you do not notice fight club: inattentional blindness for a simulated real-world assault . i-Perception 2 , 150–153 10.1068/i0436 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Chalmers D. (1996). The Conscious Mind . Harvard: Oxford University Press [ Google Scholar ]
- Cohen M. A., Alvarez G. A., Nakayama K. (2011). Natural-scene perception requires attention . Psychol. Sci. 22 , 1165–1172 10.1177/0956797611419168 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Cohen M. A., Dennett D. C. (2011). Consciousness cannot be separated from function . Trends Cogn. Sci. (Regul. Ed.) 15 , 358–364 10.1016/j.tics.2011.10.004 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- De Weerd P., Smith E., Greenberg P. (2006). Effects of selective attention on perceptual filling-in . J. Cogn. Neurosci. 18 , 335–347 10.1162/jocn.2006.18.3.335 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Dennett D. C. (1991). Consciousness Explained . Boston: Little, Brown & Co [ Google Scholar ]
- Desimone R. (1998). Visual attention mediated by biased competition in extrastriate visual cortex . Philos. Trans. R. Soc. Lond. B Biol. Sci. 353 , 1245. 10.1098/rstb.1998.0280 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Desimone R., Duncan J. (1995). Neural mechanisms of selective visual attention . Annu. Rev. Neurosci. 18 , 193. 10.1146/annurev.ne.18.030195.001205 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Ditchburn R. W., Ginsborg B. L. (1952). Vision with a stabilized retinal image . Nature 170 , 36–37 10.1038/170036a0 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Feldman H., Friston K. (2010). Attention, uncertainty and free-energy . Front. Hum. Neurosci. 4 :215. 10.3389/fnhum.2010.00215 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Friston K. (2005). A theory of cortical responses . Philos. Trans. R. Soc. Lond. B Biol. Sci. 360 , 815–836 10.1098/rstb.2005.1622 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Friston K. (2008). Hierarchical models in the brain . PLoS Comput. Biol. 4 , e1000211. 10.1371/journal.pcbi.1000211 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Friston K. (2009). The free-energy principle: a rough guide to the brain? Trends Cogn. Sci. (Regul. Ed.) 13 , 293–301 10.1016/j.tics.2009.04.005 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Friston K. (2010). The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11 , 127–138 10.1038/nrn2787 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Friston K., Mattout J., Kilner J. (2011). Action understanding and active inference . Biol. Cybern. 104 , 137–160 10.1007/s00422-011-0424-z [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Friston K., Stephan K. (2007). Free energy and the brain . Synthese 159 , 417–458 10.1007/s11229-007-9237-y [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Friston K. J., Daunizeau J., Kiebel S. J. (2009). Reinforcement learning or active inference? PLoS ONE 4 , e6421. 10.1371/journal.pone.0006421 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Friston K. J., Thornton C., Clark A. (in press). Free-energy minimization and the dark room problem . Front. Psychol. [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Fuller S., Park Y., Carrasco M. (2009). Cue contrast modulates the effects of exogenous attention on appearance . Vision Res. 49 , 1825–1837 10.1016/j.visres.2009.04.019 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Geng H., Song Q., Li Y., Xu S., Zhu Y. (2007). Attentional modulation of motion-induced blindness . Chin. Sci. Bull. 52 , 1063–1070 10.1007/s11434-007-0309-7 [ CrossRef ] [ Google Scholar ]
- Gobell J., Carrasco M. (2005). Attention alters the appearance of spatial frequency and gap size . Psychol. Sci. 16 , 644–651 10.1111/j.1467-9280.2005.01588.x [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Goodman N. (1955). Fact, Fiction and Forecast . Cambridge, MA: Harvard University Press [ Google Scholar ]
- Gregory R. L. (1980). Perceptions as hypotheses . Philos. Trans. R. Soc. Lond. B Biol. Sci. 290 , 181–197 10.1098/rstb.1980.0090 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Grill-Spector K., Henson R., Martin A. (2006). Repetition and the brain: neural models of stimulus-specific effects . Trends Cogn. Sci. (Regul. Ed.) 10 , 14–23 10.1016/j.tics.2005.11.006 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Harrison L., Bestmann S., Rosa M. J., Penny W., Green G. G. R. (2011). Time scales of representation in the human brain: weighing past information to predict future events . Front. Hum. Neurosci. 5 :37. 10.3389/fnhum.2011.00037 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Helmholtz H. V. (1860). Treatise on Physiological Optics . New York: Dover [ Google Scholar ]
- Hesselmann G., Sadaghiani S., Friston K. J., Kleinschmidt A. (2010). Predictive coding or evidence accumulation? False inference and neuronal fluctuations . PLoS ONE 5 , e9926. 10.1371/journal.pone.0009926 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Hillyard S. A., Mangun G. R. (1987). Sensory gating as a physiological mechanism for visual selective attention . Electroencephalogr. Clin. Neurophysiol. Suppl. 40 , 61–67 [ PubMed ] [ Google Scholar ]
- Hohwy J. (2009). The neural correlates of consciousness: new experimental approaches needed? Conscious. Cogn. 18 , 428–438 10.1016/j.concog.2009.02.006 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Hohwy J., Fox E. (2012). Preserved aspects of consciousness in disorders of consciousness: a review and conceptual analysis . J. Conscious. Stud. 19 , 87–120 [ Google Scholar ]
- Hohwy J., Roepstorff A., Friston K. (2008). Predictive coding explains binocular rivalry: an epistemological review . Cognition 108 , 687–701 10.1016/j.cognition.2008.05.010 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Hume D. (1739. –1740). A Treatise of Human Nature . Oxford: Oxford: Clarendon Press [ Google Scholar ]
- Jack C. E., Thurlow W. R. (1973). Effects of degree of visual association and angle of displacement on the “ventriloquism” effect . Percept. Mot. Skills 37 , 967–979 10.2466/pms.1973.37.3.967 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- James W. (1890). The Principles of Psychology . New York: Holt [ Google Scholar ]
- Jiang Y., Costello P., Fang F., Huang M., He S. (2006). A gender- and sexual orientation-dependent spatial attentional effect of invisible images . Proc. Natl. Acad. Sci. U.S.A. 103 , 17048–17052 10.1073/pnas.0605678103 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Kersten D., Mamassian P., Yuille A. (2004). Object perception as Bayesian inference . Annu. Rev. Psychol. 55 , 271–304 10.1146/annurev.psych.55.090902.142005 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Kiebel S. J., Daunizeau J., Friston K. J. (2008). A hierarchy of time-scales and the brain . PLoS Comput. Biol. 4 , e1000209. 10.1371/journal.pcbi.1000209 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Kiebel S. J., Daunizeau J., Friston K. J. (2010). Perception and hierarchical dynamics . Front. Neuroinformatics 4 , 12 [ PMC free article ] [ PubMed ] [ Google Scholar ]
- Kitcher P. (1989). “Explanatory unification and the causal structure of the world,” in Scientific Explanation , eds Kitcher P., Salmon W. (Minneapolis: University of Minnesota Press; ), 410–505 [ Google Scholar ]
- Koch C., Tsuchiya N. (2007). Attention and consciousness: two distinct brain processes . Trends Cogn. Sci. (Regul. Ed.) 11 , 16–22 10.1016/j.tics.2006.10.012 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Kok P., Rahnev D., Jehee J. F. M., Lau H. C., De Lange F. P. (2011). Attention reverses the effect of prediction in silencing sensory signals . Cereb. Cortex . 10.1093/cercor/bhr310 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Kveraga K., Ghuman A. S., Bar M. (2007). Top-down predictions in the cognitive brain . Brain Cogn. 65 , 145–168 10.1016/j.bandc.2007.06.007 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Ling S., Carrasco M. (2006). When sustained attention impairs perception . Nat. Neurosci. 9 , 1243–1245 10.1038/nn1761 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Liu T., Abrams J., Carrasco M. (2009). Voluntary attention enhances contrast appearance . Psychol. Sci. 20 , 354–362 10.1111/j.1467-9280.2009.02300.x [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Lou L. (1999). Selective peripheral fading: evidence for inhibitory sensory effect of attention . Perception 28 , 519–526 10.1068/p2816 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Martinez-Trujillo J. C., Treue S. (2004). Feature-based attention increases the selectivity of population responses in primate visual cortex . Curr. Biol. 14 , 744–751 10.1016/j.cub.2004.04.028 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- McGrayne S. B. (2011). The Theory That Would Not Die: How Bayes’ Rule Cracked the Enigma Code, Hunted Down Russian Submarines, and Emerged Triumphant from Two Centuries of Controversy . New Haven: Yale University Press [ Google Scholar ]
- Morgenstern Y., Murray R. F., Harris L. R. (2011). The human visual system’s assumption that light comes from above is weak . Proc. Natl. Acad. Sci. U.S.A. 108 , 12551–12553 10.1073/pnas.1100794108 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Mumford D. (1992). On the computational architecture of the neocortex. II. The role of cortico-cortical loops . Biol. Cybern. 66 , 241–251 10.1007/BF00198477 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- New J. J., Scholl B. J. (2008). Perceptual scotomas . Psychol. Sci. 19 , 653–659 10.1111/j.1467-9280.2008.02228.x [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Prinzmetal W., Nwachuku I., Bodanski L., Blumenfeld L., Shimizu N. (1997). The Phenomenology of Attention . Conscious. Cogn. 6 , 372–412 10.1006/ccog.1997.0313 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Rao R. P. N. (2005). Bayesian inference and attentional modulation in the visual cortex . Neuroreport 16 , 1843–1848 10.1097/01.wnr.0000183900.92901.fc [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Rensink R., O’Regan J., Clark J. (1997). To see or not to see: the need for attention to perceive changes in scenes . Psychol. Sci. 8 , 368. 10.1111/j.1467-9280.1997.tb00427.x [ CrossRef ] [ Google Scholar ]
- Ross J., Burr D. (2008). The knowing visual self . Trends Cogn. Sci. (Regul. Ed.) 12 , 363–364 10.1016/j.tics.2008.06.007 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Sampanes A. C., Tseng P., Bridgeman B. (2008). The role of gist in scene recognition . Vision Res. 48 , 2275–2283 10.1016/j.visres.2008.07.011 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Schölvinck M. L., Rees G. (2009). Attentional influences on the dynamics of motion-induced blindness . J. Vis. 9 (Article 38):1–8 10.1167/9.6.1 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Simons D. J., Chabris C. F. (1999). Gorillas in our midst: sustained inattentional blindness for dynamic events . Perception 28 , 1059–1074 10.1068/p2952 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Simons D. J., Franconeri S. L., Reimer R. L. (2000). Change blindness in the absence of a visual disruption . Perception 29 , 1143–1154 10.1068/p3104 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Summerfield C., Egner T. (2009). Expectation (and attention) in visual cognition . Trends Cogn. Sci. (Regul. Ed.) 13 , 403–409 10.1016/j.tics.2009.06.003 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Summerfield C., Trittschuh E. H., Monti J. M., Mesulam M. M., Egner T. (2008). Neural repetition suppression reflects fulfilled perceptual expectations . Nat. Neurosci. 11 , 1004–1006 10.1038/nn.2163 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Todorovic A., Van Ede F., Maris E., De Lange F. P. (2011). Prior expectation mediates neural adaptation to repeated sounds in the auditory cortex: an MEG study . J. Neurosci. 31 , 9118–9123 10.1523/JNEUROSCI.1425-11.2011 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Treisman A. (1996). The binding problem . Curr. Opin. Neurobiol. 6 , 171–178 10.1016/S0959-4388(96)80070-5 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Treisman A. (1998). Feature binding, attention and object perception . Philos. Trans. R. Soc. Lond. B Biol. Sci. 353 , 1295–1306 10.1098/rstb.1998.0284 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Treisman A. (1999). Solutions to the binding problem: review progress through controversy summary and convergence . Neuron 24 , 105–110 10.1016/S0896-6273(00)80826-0 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Treisman A. M., Gelade G. (1980). A feature-integration theory of attention . Cogn. Psychol. 12 , 97–136 10.1016/0010-0285(80)90005-5 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Troxler D. (1804). “Über das Verschwindern gegebener Gegenstande innerhalb unsers Gesichtskreises,” in Ophthalmologisches Bibliothek , eds Himly K., Schmidt J. A. (Jena: Fromman; ), 1–119 [ Google Scholar ]
- Van Boxtel J. J. A., Tsuchiya N., Koch C. (2010). Consciousness and attention: on sufficiency and necessity . Front. Psychol. 1 :217. 10.3389/fpsyg.2010.00217 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Vuilleumier P., Armony J. L., Driver J., Dolan R. J. (2003). Distinct spatial frequency sensitivities for processing faces and emotional expressions . Nat. Neurosci. 6 , 624–631 10.1038/nn1057 [ PubMed ] [ CrossRef ] [ Google Scholar ]
- Watzl S. (2011a). The nature of attention . Philos. Compass 6 , 842–853 10.1111/j.1747-9991.2011.00433.x [ CrossRef ] [ Google Scholar ]
- Watzl S. (2011b). The philosophical significance of attention . Philos. Compass 6 , 722–733 10.1111/j.1747-9991.2011.00432.x [ CrossRef ] [ Google Scholar ]
- Wu W. (2011). Confronting many-many problems: attention and agentive control . Noûs 45 , 50–76 10.1111/j.1468-0068.2010.00804.x [ CrossRef ] [ Google Scholar ]
- Zhang P., Jamison K., Engel S., He B., He S. (2011). Binocular rivalry requires visual attention . Neuron 71 , 362–369 10.1016/j.neuron.2011.05.035 [ PMC free article ] [ PubMed ] [ CrossRef ] [ Google Scholar ]
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 24 September 2019
Perceptual and conceptual processing of visual objects across the adult lifespan
- Rose Bruffaerts 1 , 2 , 3 ,
- Lorraine K. Tyler 1 , 4 ,
- Meredith Shafto 1 ,
- Kamen A. Tsvetanov 1 , 4 ,
- Cambridge Centre for Ageing and Neuroscience &
- Alex Clarke ORCID: orcid.org/0000-0001-7768-5229 1
Scientific Reports volume 9 , Article number: 13771 ( 2019 ) Cite this article
4896 Accesses
15 Citations
2 Altmetric
Metrics details
Making sense of the external world is vital for multiple domains of cognition, and so it is crucial that object recognition is maintained across the lifespan. We investigated age differences in perceptual and conceptual processing of visual objects in a population-derived sample of 85 healthy adults (24–87 years old) by relating measures of object processing to cognition across the lifespan. Magnetoencephalography (MEG) was recorded during a picture naming task to provide a direct measure of neural activity, that is not confounded by age-related vascular changes. Multiple linear regression was used to estimate neural responsivity for each individual, namely the capacity to represent visual or semantic information relating to the pictures. We find that the capacity to represent semantic information is linked to higher naming accuracy, a measure of task-specific performance. In mature adults, the capacity to represent semantic information also correlated with higher levels of fluid intelligence, reflecting domain-general performance. In contrast, the latency of visual processing did not relate to measures of cognition. These results indicate that neural responsivity measures relate to naming accuracy and fluid intelligence. We propose that maintaining neural responsivity in older age confers benefits in task-related and domain-general cognitive processes, supporting the brain maintenance view of healthy cognitive ageing.
Similar content being viewed by others

The vertical position of visual information conditions spatial memory performance in healthy aging

Three major dimensions of human brain cortical ageing in relation to cognitive decline across the eighth decade of life

Two separate, large cohorts reveal potential modifiers of age-associated variation in visual reaction time performance
Introduction.
Recognizing objects is a fundamental aspect of human cognition. Accessing the meaning of an object is essential in order to interact successfully with the world around us, and is therefore a vitally important cognitive function to maintain across the adult lifespan. Research with young adults suggests that accessing meaning from vision is accomplished within the first half second of seeing an object 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , and involves recurrent activity within the ventral temporal cortex extending into the anteromedial temporal cortex 2 , 10 , 11 , 12 , 13 , 14 . As the visual input is processed along this pathway, it is transformed into an initial coarse grained semantic representation (e.g. animal, tool ) in the inferior temporal cortex before a more semantically specific representation emerges (e.g. cow, hammer ) in the anteromedial temporal cortex 12 , 15 , 16 .
Using multivariate analysis enables quantification of the representation of perceptual and semantic information during this rapid transformation process. Clarke et al . 4 investigated the time course of single object processing using a computational model of vision 17 combined with semantic-feature information 18 . In young participants, perceptual information was represented within the first 150 ms of object presentation, with the addition of semantic information providing a better account of object representations up to 400 ms 4 . The combination of explicit models of vision and semantics provides an integrated account of the processing of perceptual and conceptual information of visual objects 19 , 20 . While it is well-known that visual processing becomes slower in middle-aged and mature people 21 , 22 , 23 , it is unclear whether there are age-related differences in the processing of visual or semantic information of single objects. Here, we evaluated differences in measures of perceptual and semantic information across the lifespan using MEG in a large population-derived ageing cohort from the Cambridge Centre for Ageing and Neuroscience (Cam-CAN; http://www.cam-can.org ). Possible age-related neural differences in object processing may or may not relate to behavior: changes may impact either task-performance or domain-general cognitive function, or both. To address this, we relate neural measures of perceptual and semantic information processing to different metrics of cognition to evaluate their relevance for healthy cognitive ageing.
It is well established that both early and late aspects of visually evoked neural responses show age-related changes, where activity is reduced and delayed with age 22 , 24 , 25 , 26 , 27 , 28 . For example, recently Price et al . 28 used MEG to show that the initial neural response to checkerboards in early visual cortex is increasingly delayed across the lifespan. Further, age-related differences in later visual components have been observed, such as delayed N170 25 and slower information processing of faces 26 , 27 . However, it remains to be determined if age-related changes are related to early visual processes or semantic activation, how changes in the initial visual processes (amplitude or delay) impact semantics, and further if such changes have behavioural consequences.
Rather than a mere description of age-related neural differences, a challenge is to relate these differences to cognition to elucidate what happens during successful ageing 29 , 30 . Across the adult lifespan, differences in fluid intelligence and picture naming accuracy can be predicted from the degree to which different brain networks are responsive to these tasks 31 . This suggests that maintenance of neural responsivity could support successful cognitive ageing. The “maintenance view” hypothesizes that the brains of mature adults whose neurobiology is well preserved, will show activation patterns similar to younger adults which are germane to proficient performance 32 . However, many current models of healthy cognitive ageing are primarily based on fMRI studies 29 , which could be confounded by the effects of age on vasculature 33 . Therefore, we need electrophysiological studies to complement fMRI research, and extend our current theoretical models of neurocognitive ageing. Research techniques such as MEG, provide both a direct measure of neural activity and allow us to examine temporal dynamics, and therefore offer an ideal approach to examine neurocognitive models of ageing.
In the current study, we ask whether the representation of perceptual and semantic information reflected in the MEG signal is different across the adult lifespan, and whether this relates to task–related measures of cognition, e.g. naming accuracy, and domain-general cognitive measures, namely fluid and crystallized intelligence. We analyzed MEG signals during a picture naming task from the Cam-CAN cohort study 34 . By relating single-object measures of vision and semantics to MEG signals, we were able to test (1) whether representations of visual and semantic information are different across the adult lifespan (2) whether changes in representation of visual information impacts semantics, and (3) do these age-related differences in neural processing relate to behavioral performance.
Rather than using an approach based on raw MEG signals, we follow the strategy used in our previous study 4 where we modelled MEG signals with explicit models of vision and semantics. The outcome, which is a quantification of the individual’s capacity to represent visual or semantic information, can be seen as a measure of neural responsivity. In other words, the individual’s ability to neurally represent a stimulus – quantified by a higher correlation between neural activity and the visual or semantic model - implies higher neural responsivity. The brain maintenance hypothesis suggests that better neural responsivity supports better cognition in older individuals 32 , and we predict that we will see evidence of this through our measures of visual and semantic processing. Moreover, moderation analysis can be used to test whether age plays a role in the relationship between neural responsivity and behavioral performance. Following Samu et al . 31 , we investigated picture naming accuracy, a task-specific cognitive measure of object naming, which is based on the output of visual and semantic information processing. Additionally, we investigated domain-general performance (fluid and crystallized intelligence) because neural responsivity might reflect a more general neural property of performance across tasks. Fluid intelligence is on average lower in mature adults, while crystallized intelligence is unchanged 31 , 35 , 36 . This difference prompts us to study the relationship between neural responsivity and both cognitive measures.
Behavioural results
Overall object naming accuracy for the 302 common objects was high (90.9%, SD 5.3%), but decreased significantly with age (Pearson’s r = −0.476, p < 0.001) (Fig. 1a ). When dividing the participants into equally sized age groups, we found mean accuracy was 92.3% (SD 4.7%) in the young group (24–37 years old), in the middle-aged group (47–60 years old) it was 93.8% (SD 3.8%) and in the mature group (70–87 years old) it was 85.4% (SD 4.8%). These results are consistent with previously reported age-related differences in accuracy for the same participants during fMRI picture naming 31 . Mean reaction times for correct responses tended to increase with age, but did not reach significance (r = 0.200, p = 0.066; Fig. 1b ).

Behavioural results for ( a ) naming accuracy, ( b ) reaction times, ( c ) Spot the Word and ( d ) Cattell Culture Fair versus age.
Crystallized intelligence (measured with the Spot the Word task 37 ) did not change with age in our sample (r = 0.078, p = 0.475, Fig. 1c ). As expected, fluid intelligence (measured with Cattell Culture Fair 38 ) significantly declined with age (r = −0.712, p < 0.001, Fig. 1d ). Crystallized intelligence and fluid intelligence correlated with naming accuracy (resp. r = 0.246, p = 0.023; r = 0.560, p < 0.001). Mean reaction times for correct responses were faster when fluid intelligence scores were higher (r = −0.281, p = 0.009). Mean reaction times for correct responses did not correlate to crystallized intelligence (r = −0.143, p = 0.189).
Visual and semantic model fits decrease across the lifespan
We next evaluated differences in visual and semantic neural processes across the lifespan by quantifying how much of the variability in the MEG signals could be explained by the models of vision and semantics – namely the AlexNet Deep Convolutional Neural Network 39 and a semantic feature-based model 18 , 40 . Regularised regression was performed at each time-point and for every MEG sensor separately, providing a measure of how well the visual or semantic models could explain the MEG signals over time.
First, using the fit between the visual model and the MEG signals, we calculated a single measure of the individual’s visual model fit (Fig. 2a ), and an individual peak latency (Fig. 2c ). After removing effects attributed to the visual model (Fig. 2a ), a second regression was used to calculate how well the semantic-feature based model could explain the residual MEG signals over time (after accounting for the visual model, Fig. 2b ). The individual semantic model fit was determined as the average semantic model fit between 150 and 400 ms (interval derived in an independent sample 4 ). Using this approach, we obtained independent measures of visual and semantic model fits for each individual.

Schematic representation of the analysis pipeline. Calculation of ( a ) visual model fit, ( b ) semantic model fit and ( c ) peak latency. See method section for details.
Overall, we see positive visual model fits across all ages peaking close to 110 ms (Fig. 3a–d ), with the greatest model fits over posterior sensors (Fig. 4a–c ). The visual model fit significantly decreased across the adult lifespan (r = −0.274, p = 0.011; Figs 3d and 5a ) indicating that the capacity to represent visual information, as reflected by the AlexNet model, is reduced in the mature group. Across all age groups, the semantic model demonstrated increasing model fits between 150 and 400 ms (Fig. 3e–h ), with the highest model fits observed over temporal sensors (Fig. 4d–f ). Semantic model fits significantly decreased with age (r = −0.284, p = 0.009; Figs 3h and 5b ). Variability for the semantic model fits do not change across the lifespan (Fligner-Killeen test of homogeneity of variances: p = 0.593), whilst for the visual model fit, variability was lower in the mature group (p = 0.002).

Model fits across time showing R² values for the (abcd) visual and (efgh) semantic model for the (ae) young, (bf) middle-aged and (cg) mature groups for all sensors and averaged across sensors for the three age groups (dh). Note that the effect sizes cannot be directly compared, as the visual model fit is calculated on the raw MEG signal and the semantic model fit is calculated on the residuals after the visual model fits are regressed out (see methods and Fig. 2 ).

Topographies of visual model fit at 110 ms after stimulus onset, the mean peak latency, (abc) and semantic model fit at 290 ms after stimulus onset, derived from Clarke et al . (2015) as time with maximal classification accuracy for the semantic model, (def). Topographies for magnetometers gradiometers are visualized in the young (ad), middle-aged (be) and mature (cf) age groups.

Relationship between the visual model fit, the semantic model fit, age and accuracy. ( a ) Correlation between age and the visual model fit, ( b ) Correlation between age and the semantic model fit, ( c ) Correlation between visual and semantic model fit (corrected for age), ( d ) Correlation between accuracy and semantic model fit (corrected for age).
A key question is whether the visual model fit influences the semantic model fit, and how model fits relate to task performance. We found a significant positive correlation between the visual and semantic model fits (r = 0.353, p < 0.001), which remained even after controlling for age (r = 0.287, p = 0.008) (Fig. 5c ). This shows that the initial visual representation of an item has subsequent consequences for its semantic representation, over and above the age-related differences. Further, we observed that higher semantic model fits correlated with higher naming accuracy levels, over and above the effect of age (r = 0.242, p = 0.026; Fig. 5d ). This effect was not present for the visual models fits (r = 0.122, p = 0.264, not shown). No correlation was found between visual or semantic model fits and domain-general performance measures namely Cattell Score and Spot the Word score (p > 0.247).
Effect of age on the relationship between performance and visual and semantic model fits
Having a higher semantic model fit related to better accuracy for object naming. Next we ask whether the relationship between either of our measures of neural responsivity, the visual and semantic model fits, and cognition is different across the age groups using moderation analysis. Moderation analysis determines whether the relationship between the independent variable (e.g. visual model fit) and a dependent variable (e.g. accuracy) varies as a function of another dependent variable, i.e. moderator variable (e.g. age). In terms of the brain maintenance view, it would be expected that when the visual and semantic model fits are higher, and therefore more like the younger and middle-aged participants, cognitive performance should be better.
We evaluated whether age moderates the relationship between the visual or semantic model fit and measures of cognition (fluid intelligence, crystallized intelligence, naming accuracy). Fluid intelligence could be predicted from a moderation model including age, the semantic model fit and the interaction of age and the semantic model fit (R² = 0.575, F(80, 4) = 27.0, p < 0.001, Table 1 ). The main effect of age was significant (β = −0.355, p < 0.001), but the main effect of the semantic model fit was not (β = −898, p = 0.072). Critically, the interaction between age and the semantic model fit was significant (β = 20.5, p = 0.013) (Fig. 6a , Table 1 ). Visualization of this relationship for a subsample divided into young, middle-aged and mature groups, shows that the relationship between fluid intelligence and semantic model fit becomes stronger for older individuals, i.e. high fluid intelligence in old age is associated with high semantic model fit (Fig. 6b ). A trend for significance was found for the interaction between age and visual model fit (β = 2.66, p = 0.062, Table 2 ), that produced a qualitatively similar effect. No moderation effects were seen in relation to naming accuracy or crystallized intelligence using the semantic model fit (Table 1 ) or visual model fit (Table 2 ).

Prediction of fluid intelligence: (ab) interaction between age and the semantic model fit. ( a ) The interaction effect is visualized by generation of the predicted Cattell Score for every combination of age and semantic model fit based on the interaction term from the moderation model. ( b ) The correlation within the young, middle-aged and mature group.
Impact of peak visual latency on visual and semantic information
In addition to the amplitude of the visual model fits, the peak latency of the visual model fit was calculated for every subject to test if the speed of visual information processing related to age. Second, we tested if the speed of processing related to the capacity to represent visual and semantic information, as measured by the model fits.
The average peak of the visual model fit across all participants occurred at 110 ms. The latency of individual participants’ visual model fit peaks increased significantly with age (r = 0.379, p < 0.001; Fig. 7a ), showing age-related delays in the visual processing of complex objects. We next tested whether the peak latency of the visual model influences the visual and/or semantic model fits. Since both the peak latency and the visual and semantic model fit are negatively affected by age, the following analysis was corrected for age. Peak latency showed no correlation with the visual model fit (r = −0.142, p = 0. 195) (Fig. 7b ) or the semantic model fit (r = −0.024, p = 0.825) (Fig. 7c ).

Relationship between the peak latency, age and the visual and semantic model fits. ( a ) Correlation between age and peak latency, ( b ) Correlation between peak latency and visual model fit (corrected for age), ( c ) Correlation between peak latency and semantic model fit (corrected for age).
Like above, correlation analyses were conducted to ask if the relationship between the peak latency of the visual model and measures of cognition (fluid intelligence, crystallized intelligence, naming accuracy) were linked, but we found no evidence of this (p > 0.748). Moderation analyses were conducted to test if the relationship between the peak latency of the visual model and measures of cognition varied as a function of age, but no moderation effects were seen (all p’s > 0.1). Therefore, we find no evidence that neural slowing has a dramatic influence on how visual and semantic information is represented.
We investigated differences in object processing across the adult lifespan in a large population-derived sample of cognitively healthy adults using a well-validated model of object processing in the ventral stream 12 . Here, we (1) characterize visual and semantic processes involved in object processing across the adult lifespan, (2) ask if differences in visual processing impact semantics, and (3) evaluate how measures of visual and semantic representations, which we argue reflect the neural responsivity of the visual and semantic processes, relate to cognitive function. We find clear evidence of differences across the adult lifespan in the representation of visual and semantic information: our results show neural slowing and decreases in measures of representation of visual and semantic information with age, while decreased visual effects also relate to decreased semantic effects. In relation to cognition, we see that higher measures of semantic processing are found in subjects with higher naming accuracy, and that higher semantic processing in older age was associated with increased fluid intelligence scores. Together, our results support a view that maintaining high-levels of neural responsivity is associated with both better task-related performance, and more domain general cognitive functions in line with the brain maintenance hypothesis.
Our results demonstrate a relationship between an individual’s semantic processing and both task-specific and domain-general measures of cognition. We find that higher measures of semantic processing were associated with better naming accuracy (Fig. 5d ), showing that the semantic model fits are capturing semantic representations that are related to behaviour. It is well established that picture naming errors increase with age (for a review 41 ), and this has been previously linked to phonological retrieval errors 41 , 42 . Our study adds to this by showing that the semantic processing in the first 400 ms, likely prior to phonological processing, may also contribute to naming errors. We also observed a second relationship between semantic model fit and cognition, where model fit became increasingly related to fluid intelligence with increasing age (Fig. 6 ). Whilst only significant for the semantic model fits, the effects were qualitatively similar and marginally significant for the visual model fits suggesting that neural responsivity overal becames increasingly related to fluid intelligence with increasing age. This illustrates that the capacity to represent visual or semantic information in neural signals, a measure of the neural responsivity of the visual system, could be relevant to a general measure of cognition.
Increased neural responsivity has previously been linked to higher fluid intelligence 31 , 43 and cognitive control 44 . Samu et al . 31 reported that mean-task responsive (MTR) components (also a measure of neural responsivity) that related to task performance showed significant age-related declines. The MTR components in Samu’s study gave an aggregate measure of fMRI task responsivity during either picture naming or a fluid intelligence task, and were able to explain individual variability in task performance. These task related activations further declined with age, and increased with task performance. The majority of voxels contributing to the MTR components were from occipitotemporal cortex, with the implication being that the greater task responsivity, the better that performance will be maintained into older adulthood.
Based on our model fits, which we view as measures of neural responsivity derived from MEG data, we find additional evidence that better neural responsivity plays a role in healthy cognitive ageing. This is further supported by correlations we observe between our model fits and MTR components from Samu et al . 31 for the same participants (data for 63/85 of our participants also in 31 ). There was a strong correlation between the MTR of the fMRI picture naming task and the visual model fit of the same participants in the MEG picture naming task (r = 0.487, p < 0.001). This suggests that the MTR components at least partially reflect the responsitivity of the neural substrate of visual object processing which we derived in this study. In addition, there was a correlation between the MTR of the fMRI picture naming task and the MEG semantic model fit (r = 0.274, p = 0.030). Overall, this provides additional evidence that the model fits are estimates of neural responsivity. Our analyses are consistent with the idea that better cognitive performance is supported by good neural responsivity. We hypothesize that a reduced ability to modulate task-relevant brain networks may contribute to age-related declines in cognition. Like Samu et al . 31 our results are consistent with the brain maintenance hypothesis, which states that individual differences in age-related brain changes, such as neural responsivity, allow some people to show little or no age-related cognitive decline 32 . Thus, retaining youth-like neural function is key to preservation of cognitive performance across the lifespan 45 .
Another mechanism which is sometimes proposed to compensate for potential age-related changes is the recruitment of contralateral and prefrontal regions 46 , 47 . Our study does not allow us to differentiate between maintenance and compensation as the mechanism by which some mature controls perform at similar levels to the younger groups. The focus in our study is the timing and untangling of visual and semantic effects, and did not examine regional effects which would be required to test for top-down compensation mechanisms or the recruitment of additional regions. To the contrary, we elected to avoid assumptions about the localization of our effects at the individual level and used data from all available sensors. Our approach leaves open the possibility of a top-down modulatory process on early visual activity, which would be in line with compensation mechanisms. This notion is supported by connectivity studies showing increased frontal to posterior connectivity during object naming in older adults 48 , 49 . However, our MEG effects did correlate with fMRI-based MTR components that are localized to occipitotemporal cortex which may not be compatible with compensation, suggesting our results are more consistent with the brain maintenance hypothesis than compensation.
Several lines of research suggest an age-related slowing of neural responses to visual stimuli 22 , 24 , 25 , 26 , 27 , 28 . Consistent with this, we demonstrate a clear increase in the delay in visual information processing with increasing age, but found no evidence this delay related to age-related cognitive changes. This may argue against the universality of the general slowing hypothesis, which proposes that general slowing leads to age-related declines in performance 50 . Instead, our data argues that although visual slowing does occur across the adult lifespan, it does not necessarily have detrimental consequences for cognition, while the magnitude of the visual and semantic model fits does relate to both task-specific and domain general measures of cognition. However, it has also been noted that age-related processing speed declines may only impact cognition in task with high cognitive demands 51 , 52 , 53 . In the current study, participants are naming a series of highly familiar, easily nameable pictures, and it could be the case that the age-related visual delay we observed would only have cognitive impacts in more challenging situations.
Our finding that the capacity to represent visual and semantic information is lower in mature adults, might be viewed as supporting evidence for the information degradation hypothesis 54 . Repeatedly, correlations have been observed between visual perceptual decline and cognitive decline across the adult lifespan in large samples 55 , 56 , 57 . The information degradation hypothesis states that degraded perceptual input resulting from age-related neurobiological changes causes a decline in cognitive processes 54 . We find that the capacity to represent visual information correlates with the capacity to represent semantic information, which is consistent with this hypothesis. Because our approach is correlational, we cannot make any claims about the causal nature of the changes in neural responsitivity to visual input on semantic processing. To support the information degradation hypothesis and rule out e.g. the influence of cognition on perceptual processing or other confounding effects, experimental manipulation of perceptual input is required 58 . However, our approach does yield a sensitive method to determine neural responsitivity to visual input at the individual level, which can benefit further work aimed at corroborating or refuting the information degradation hypothesis.
Even though we have made use of a large sample of healthy adults from the population-representative Cam-CAN cohort 34 , we acknowledge the need for longitudinal research to further examine the hypothesis that neural responsivity decreases across the lifespan, and that these changes have an impact on cognitive function. From our cross-sectional sample, we can only assess age-related differences 59 . The relationships which we observe do not allow us to make causal inferences and might also underestimate nonlinear age trends 60 . Secondly, our findings offer only a partial explanation for the variability in naming accuracy and fluid intelligence in older adulthood. Note that we investigated visual and semantic processing during picture naming, but not phonological retrieval and articulatory response generation. A future direction which might explain additional variability in naming accuracy consists of the implementation of explicit phonological and articulatory models to elucidate these 2 processes. A consideration is the relatively high education level across individuals in our sample. The limited variability of education levels across the age ranges precludes claims about the effect of education on brain maintenance. Importantly, including education as a covariate of no interest did not change our results, suggesting that the observed findings are beyond the effects of education. Specifically targeted large population-based samples are needed to investigate this in more detail.
In conclusion, our results show that in healthy elderly adults, visual object processing is slower and the capacity of the brain to represent visual and semantic object information is reduced. In elderly participants, having higher measures of neural responsivity were linked to better measures of fluid intelligence, and higher semantic neural responsivity was associated with higher naming accuracy. These results are in line with the brain maintenance hypothesis, which states that individual differences in age-related brain changes allow some people to show little or no age-related cognitive decline. Our measures of neural responsivity suggest that age-related declines may partly be underpinned by a reduced ability to modulate task-relevant brain networks.
Participants
One hundred and eighteen members of the CamCan cohort of healthy adults aged 18–88 years 34 participated in this study. Exclusion criteria for the Cam-CAN Phase III cohort, that was selected for extensive neuroimaging, included Mini Mental State Examination scores <25 61 , poor vision (<20/50 on the Snellen test 62 ), non-native English speakers, drug abuse, a serious psychiatric condition or serious health conditions (for full exclusion criteria, see 34 ). Informed consent was obtained from all participants and ethical approval for the study was obtained from the Cambridgeshire 2 (now East of England-Cambridge Central) Research Ethics Committee. All experiments were performed in accordance with relevant guidelines and regulations.
From this subset, 85 participants were included in the current analysis. They were all right-handed and were aged 24–87 years (M = 53.2, SD = 18.0, 44 male). Of the initial total of 118 participants, 19 were excluded because of technical problems during data acquisition, 12 were excluded at the preprocessing stage because of poor data quality (see MEG preprocessing) and 2 were excluded because they were strictly left-handed (assessed by means of the Edinburgh Handedness Inventory). The overall education level in this subset of the population-derived cohort was high: 70.2% obtained a degree, and 88.2% obtained at least an A-level certification. In our sample, age negatively correlated with education level (r: −0.365, p < 0.001). The average score on the HADS depression scale was 2.48 (s.d. 2.89) and on the HADS anxiety scale 4.73 (s.d. 3.34), and these scores did not correlate with age in our dataset (p > 0.167).
Experimental design
Participants named pictures of single objects at the basic-level (e.g., “tiger”,”broom”). The stimulus set is the same as in Clarke et al . 4 and consisted of 302 items from a variety of superordinate categories that represented concepts from an anglicized version of a large property generation study 18 , 40 . The items were presented as colour photographs of single objects on a white background. Each trial began with a black fixation cross (500 ms), followed by presentation of the item (500 ms). Afterwards a blank screen was shown, lasting between 2400 and 2700 ms. Each item was presented once. The order of stimuli was pseudo-randomized such that consecutive stimuli were not phonologically related (i.e., shared an initial phoneme) and no more than 4 living or non-living items could occur in a row. Stimuli were presented using Eprime (version 2; Psychology Software Tools, Pittsburgh, PA, USA) and answers were recorded by the experimenter. Offline, responses were checked for accuracy (synonyms, e.g. “couch” for “sofa”, were scored as correct).
Crystallized and fluid intelligence tests were administered offline during a prior stage of the Cam-CAN study 34 . Crystallized intelligence was measured using the Spot the Word test in which participants performed a lexical decision task on word-nonword pairs (e.g. pinnace-strummage) 37 . This test was designed to measure lifetime acquisition of knowledge. Fluid intelligence was measured using the Cattell Culture Fair, Scale 2 Form A, a timed pen-and-paper test in which participants performed 4 subtests with different types of nonverbal puzzles: series completion, classification, matrices and conditions 38 .
Stimulus measures
Visual information for each item was derived from the AlexNet deep convolutional neural network model 39 , as implemented in the Caffe deep learning framework 63 , and trained on the ILSVRC12 classification data set from ImageNet. We used the layers 2 to 7 of the DNN, consisting of five convolutional layers (conv2–conv5) followed by two fully connected layers (fc6 and fc7). The convolutional kernels learned in each convolutional layer correspond to filters receptive to particular kinds of visual input (conv1 was discarded because conv2 has been shown to mimic the activity in early visual cortex more closely than conv1 8 , 19 ). We presented our 302 stimuli to the DNN which produced activation values for all nodes in each layer of the network for each image. Activation values for all nodes were concatenated across layers, resulting in an objects by nodes matrix. PCA reduction was used to obtain 100 components, otherwise the blank space surrounding objects would be represented across a large number of nodes 64 .
The semantic measures used were the same as those used as in Clarke et al . 4 , and derived from semantic feature norms 18 , 40 . For every concept, these feature norms consist of an extensive list of features generated by participants in response to this concept. These features are visual, auditory, tactile, encyclopedic, etc. The relationship between items can be captured through the similarity of their features, where similar concepts will share many features, while the distinctive properties of a concept will differentiate it from other category members. For each of the 302 concepts, a binary vector indicates whether semantic features (N = 1510) are associated with the concept or not. PCA was used to reduce the concept-feature matrix from 1510 features for every concept, to 6 components for every concept.
MEG/MRI recording
MEG and MRI acquisition in the Cam-CAN cohort is described in detail in Taylor et al . 65 . Continuous MEG data were recorded using a whole-head 306 channel (102 magnetometers, 204 planar gradiometers) Vector-view system (Elekta Neuromag, Helsinki, Finland) located at the MRC Cognition and Brain Sciences Unit, Cambridge, UK. Participants were in a seated position. Eye movements were recorded with electro-oculogram (EOG) electrodes. ECG was recorded by means of one pair of bipolar electrodes. Five head-position indicator (HPI) coils were used to record the head position within the MEG helmet every 200 ms. The participant’s head shape was digitally recorded using >50 measuring points by means of a 3D digitizer (Fastrak Polhemus, Inc., Colchester, VA, USA) along with the position of the EOG electrodes, HPI coils and fiducial points (nasion, left and right periauricular). MEG signals were recorded at a sampling rate of 1000 Hz, with a highpass filter of 0.03 Hz. If required, participants were given MEG-compatible glasses to correct their vision.
MEG preprocessing
Initial preprocessing of the raw data used MaxFilter version 2.2 (Elekta-Neuromag Oy, Helsinki, Finland) as described in the Cam-CAN pipeline 66 . For each run, temporal signal space separation 67 was applied to remove noise from external sources and from HPI coils for continuous head-motion correction (correlation threshold: 0.98, 10 s sliding window), and to virtually transform data to a common head position. MaxFilter was also used to remove mains-frequency noise (50 Hz notch filter) and automatically detect and virtually reconstruct noisy channels.
Further preprocessing was performed using SPM12 (Wellcome Institute of Imaging Neuroscience, London, UK). MEG data were low-pass filtered at 200 Hz (fifth order Butterworth filter) and high-pass filtered at 0.1 Hz (fourth order Butterworth filter). Initial epoching from −1s to 1 s was performed before artifact removal by means of Independent Component Analysis (ICA) using RUNICA 68 . Artifactual components were identified using the SASICA toolbox 69 consisting of components related to blinks, eye movements, rare events, muscle artifacts and saccades. Spatial topographies of the ICs suggested by SASICA were visually inspected prior to their rejection. Finally, IC epochs were averaged and correlated with a “speech template” curve that was modelled as a sigmoidal curve with a slope starting at 200 ms reaching a plateau at 1200 ms. ICs with a correlation of >0.8 were removed. ICA was applied to magnetometers and gradiometers separately. Following ICA, items that were not correctly named or only named after a hesitation period, were excluded from further analysis at the subject level. Finally, MEG data were baseline corrected (time window: −200 to 0 ms) and cropped to the epoch of interest from −200 ms to 600 ms. Temporal signal-to-noise ratio (tSNR) was calculated as the ratio between the mean and standard deviation for the baseline period. Participants with tSNR < 1 were excluded from further processing (N = 12). No significant tSNR differences were observed between age groups (p = 0.183). Data were downsampled to 100 Hz to obtain manageable computing times.
Visual model fit
Using lasso linear regression, R 2 values were calculated that captured how well the MEG signals (dependent variable) were modelled by the AlexNet model (independent variables) (Fig. 2a ). Lasso regression was used to avoid overfitting. Lasso regression was implemented using glmnet for Matlab 70 where the regularization parameter lambda was set using 10 fold cross-validation from a set of 100 potential lambda values defined automatically based on the data. Using the optimal lambda value, R² was calculated for each participant at each timepoint and sensor independently. To derive one model fit value per timepoint, R² values were subsequently averaged across all sensors (magnetometers and gradiometers) to construct a time course for every participant. We averaged across all sensors because visual object processing elicits widespread neural responses and the distribution of these responses might vary between individuals and age groups. For this reason, we did not want to make any assumptions by using predefined regions. To correct for individual differences in model fit unrelated to object processing, we subtracted the average R² values before stimulus onset (−200 to 0 ms) from the R² values after stimulus onset (0 to 600 ms) for every participant. To obtain a measure of each individual’s peak model fit latency, a mean template across all participants was constructed, before each individual’s timecourse was virtually shifted in 10 ms steps relative to the mean template to find the maximal correlation to the template 28 . The individual’s peak latency was calculated from the mean peak latency (110 ms) and the shift needed to maximally correlate to the template (Fig. 2c ). The individual visual model fit is the visual model fit averaged across sensors at the individual’s peak latency (Fig. 2c ).
Semantic model fit
In a second step, multiple linear regression was performed between the semantic model and the residuals from the visual model fit (Fig. 2b ). A time windows of interest between 150 and 400 ms was derived from Clarke et al . 4 (note that the 14 participants from Clarke et al . 4 are not part of the Cam-CAN cohort). An individual’s semantic model fit was calculated by averaging across time points and sensors between 150 and 400 ms. In this way, we are modelling semantic information in a very stringent way, that is over and above what the AlexNet model can explain. By regressing out the visual model, all variability which can be explained by the visual model will be removed from the MEG signals.
Statistical analysis
To test for age-related changes in visual and semantic processing, the measures of visual and semantic model fit, as well as the measure of peak latency, were correlated with age. Secondly, we investigated the relationships between peak latency, visual model fit and semantic model fit and added age as a covariate of no interest. Next, we correlated peak latency, visual model fit and semantic model fit on one hand with our cognitive measures (naming accuracy, fluid or crystallized intelligence) on the other hand with age as a covariate of no interest.
Using moderation analysis, we test whether the relationship between visual or semantic model fits and our cognitive measures is different across the age groups. As in Samu et al . 31 , we used multiple linear regression with an interaction term to test the potential moderation effect of age on the relation between two other variables 71 . More specifically, if we wanted to investigate the relation between X and Y, and Z is the moderator variable “age” to be tested, we ran a multiple linear regression with Y as the dependent variable, and X, Z and the interaction term XZ as predictor variables. A significantly non-zero coefficient of predictor XZ would in turn indicate a moderator effect of Z (“age”) on the relationship between X and Y. In all correlation and moderation analyses, gender was added as a covariate of no interest 31 . Normality was assessed using Q-Q plots and homogeneity of variances was determined by Fligner-Killeen’s Equality of Variances test.
The statistical analyses were performed using all 85 subjects (24–87 years old), with age treated as a continuous variable. However, visualization of e.g. moderation analysis is not always straightforward. Therefore, for visualization purposes we split the dataset in three equal groups of 21 subjects each which were separated by a ten year age gap to highlight changes between age groups. The youngest group consisted of all participants between 24 and 37 years old (12 female, 9 male), the middle-aged group consisted of all participants between 47 and 60 years old (10 female, 11 male), the oldest group consisted of all participants between 70 and 87 years old (10 female, 11 male).
Data Availability
The data set analysed in this study is part of the Cambridge Centre for Ageing and Neuroscience (Cam-CAN) research project ( www.cam-can.com ). The entire Cam-CAN dataset will be made publicly available in the future.
Schendan, H. E. & Maher, S. M. Object knowledge during entry-level categorization is activated and modified by implicit memory after 200 ms. NeuroImage 44 , 1423–1438 (2009).
Article Google Scholar
Clarke, A., Taylor, K. I. & Tyler, L. K. The evolution of meaning: spatio-temporal dynamics of visual object recognition. J. Cogn. Neurosci. 23 , 1887–1899 (2011).
Clarke, A., Taylor, K. I., Devereux, B., Randall, B. & Tyler, L. K. From Perception to Conception: How Meaningful Objects Are Processed over Time. Cereb. Cortex 23 , 187–197 (2013).
Clarke, A., Devereux, B. J., Randall, B. & Tyler, L. K. Predicting the Time Course of Individual Objects with MEG. Cereb. Cortex 25 , 3602–3612 (2015).
Cichy, R. M., Pantazis, D. & Oliva, A. Resolving human object recognition in space and time. Nat. Neurosci. 17 , 455–462 (2014).
Article CAS Google Scholar
Leonardelli, E., Fait, E. & Fairhall, S. L. Temporal dynamics of access to amodal representations of category-level conceptual information. Sci. Rep. 9 , 239 (2019).
Article ADS Google Scholar
Kaiser, D., Azzalini, D. C. & Peelen, M. V. Shape-independent object category responses revealed by MEG and fMRI decoding. J. Neurophysiol. 115 , 2246–2250 (2016).
Cichy, R. M., Khosla, A., Pantazis, D., Torralba, A. & Oliva, A. Comparison of deep neural networks to spatio-temporal cortical dynamics of human visual object recognition reveals hierarchical correspondence. Sci. Rep . 6 (2016).
Isik, L., Meyers, E. M., Leibo, J. Z. & Poggio, T. The dynamics of invariant object recognition in the human visual system. J. Neurophysiol. 111 , 91–102 (2014).
Schendan, H. E. & Ganis, G. Electrophysiological potentials reveal cortical mechanisms for mental imagery, mental simulation, and grounded (embodied) cognition. Front. Psychol. 3 , 329 (2012).
Kravitz, D. J., Saleem, K. S., Baker, C. I., Ungerleider, L. G. & Mishkin, M. The ventral visual pathway: an expanded neural framework for the processing of object quality. Trends Cogn. Sci. 17 , 26–49 (2013).
Clarke, A. & Tyler, L. K. Understanding What We See: How We Derive Meaning From Vision. Trends Cogn. Sci. 19 , 677–687 (2015).
Chen, Y. et al . The ‘when’ and ‘where’ of semantic coding in the anterior temporal lobe: Temporal representational similarity analysis of electrocorticogram data. Cortex 79 , 1–13 (2016).
Rupp, K. et al . Semantic attributes are encoded in human electrocorticographic signals during visual object recognition. NeuroImage 148 , 318–329 (2017).
Moss, H. E. Anteromedial Temporal Cortex Supports Fine-grained Differentiation among Objects. Cereb. Cortex 15 , 616–627 (2004).
Tyler, L. K. et al . Objects and categories: feature statistics and object processing in the ventral stream. J. Cogn. Neurosci. 25 , 1723–1735 (2013).
Serre, Wolf & Poggio. Object Recognition with Features Inspired by Visual Cortex. In Computer Vision and pattern recognition (2005).
Taylor, K. I., Devereux, B. J., Acres, K., Randall, B. & Tyler, L. K. Contrasting effects of feature-based statistics on the categorisation and basic-level identification of visual objects. Cognition 122 , 363–374 (2012).
Devereux, B. J., Clarke, A. & Tyler, L. K. Integrated deep visual and semantic attractor neural networks predict fMRI pattern-information along the ventral object processing pathway. Sci. Rep. 8 , 10636 (2018).
Bruffaerts, R. et al . Redefining the resolution of semantic knowledge in the brain: advances made by the introduction of models of semantics in neuroimaging. Neurosci. Biobehav. Rev , https://doi.org/10.1016/j.neubiorev.2019.05.015 (2019).
Chaby, L., George, N., Renault, B. & Fiori, N. Age-related changes in brain responses to personally known faces: an event-related potential (ERP) study in humans. Neurosci. Lett. 349 , 125–129 (2003).
Onofrj, M., Thomas, A., Iacono, D., D’Andreamatteo, G. & Paci, C. Age-related changes of evoked potentials. Neurophysiol. Clin. Clin. Neurophysiol. 31 , 83–103 (2001).
Spear, P. D. Neural bases of visual deficits during aging. Vision Res. 33 , 2589–2609 (1993).
Allison, T., Hume, A. L., Wood, C. C. & Goff, W. R. Developmental and aging changes in somatosensory, auditory and visual evoked potentials. Electroencephalogr. Clin. Neurophysiol. 58 , 14–24 (1984).
Nakamura, A. et al . Age-related changes in brain neuromagnetic responses to face perception in humans. Neurosci. Lett. 312 , 13–16 (2001).
Rousselet, G. A. et al . Age-related delay in information accrual for faces: evidence from a parametric, single-trial EEG approach. BMC Neurosci. 10 , 114 (2009).
Rousselet, G. A. et al . Healthy aging delays scalp EEG sensitivity to noise in a face discrimination task. Front. Psychol. 1 , 19 (2010).
PubMed PubMed Central Google Scholar
Price et al . Age-Related Delay in Visual and Auditory Evoked Responses is Mediated by White- and Gray-matter Differences. Nat. Commun (2017).
Grady, C. The cognitive neuroscience of ageing. Nat. Rev. Neurosci. 13 , 491–505 (2012).
Geerligs, L. & Tsvetanov, K. A. The use of resting state data in an integrative approach to studying neurocognitive ageing–commentary on Campbell and Schacter (2016). Lang. Cogn. Neurosci . 32 (2017).
Samu, D. et al . Preserved cognitive functions with age are determined by domain-dependent shifts in network responsivity. Nat. Commun. 8 , ncomms14743 (2017).
Nyberg, L., Lövdén, M., Riklund, K., Lindenberger, U. & Bäckman, L. Memory aging and brain maintenance. Trends Cogn. Sci. 16 , 292–305 (2012).
Tsvetanov, K. A. et al . The effect of ageing on fMRI: Correction for the confounding effects of vascular reactivity evaluated by joint fMRI and MEG in 335 adults. Hum. Brain Mapp. 36 , 2248–2269 (2015).
Shafto, M. A. et al . The Cambridge Centre for Ageing and Neuroscience (Cam-CAN) study protocol: a cross-sectional, lifespan, multidisciplinary examination of healthy cognitive ageing. BMC Neurol. 14 , 204 (2014).
Salthouse, T. A. Quantity and structure of word knowledge across adulthood. Intelligence 46 , 122–130 (2014).
Campbell, K. L. et al . Robust Resilience of the Frontotemporal Syntax System to Aging. J. Neurosci. 36 , 5214–5227 (2016).
Baddeley, A., Emslie, H. & Nimmo-Smith, I. The Spot-the-Word test: A robust estimate of verbal intelligence based on lexical decision. Br. J. Clin. Psychol. 32 , 55–65 (1993).
Cattell, R. B. & Cattell, A. K. S. Handbook for the individual or group Culture Fair Intelligence Test (1960).
Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems 1097–1105 (2012).
McRae, K., Cree, G. S., Seidenberg, M. S. & Mcnorgan, C. Semantic feature production norms for a large set of living and nonliving things. Behav. Res. Methods 37 , 547–559 (2005).
Burke, D. M., Shafto, M. A., Craik, F. I. M. & Salthouse, T. A. Language and aging. Handb. Aging Cogn. 3 , 373–443 (2008).
Google Scholar
Shafto, M. A., James, L. E., Abrams, L. & Tyler, L. K., Cam-CAN. Age-Related Increases in Verbal Knowledge Are Not Associated With Word Finding Problems in the Cam-CAN Cohort: What You Know Won’t Hurt You. J. Gerontol. B. Psychol. Sci. Soc. Sci. 72 , 100–106 (2017).
Tsvetanov, K. A. et al . Extrinsic and Intrinsic Brain Network Connectivity Maintains Cognition across the Lifespan Despite Accelerated Decay of Regional Brain Activation. J. Neurosci. 36 , 3115–3126 (2016).
Tsvetanov, K. A. et al . Activity and Connectivity Differences Underlying Inhibitory Control Across the Adult Life Span. J. Neurosci. 38 , 7887–7900 (2018).
Düzel, E., Schütze, H., Yonelinas, A. P. & Heinze, H.-J. Functional phenotyping of successful aging in long-term memory: Preserved performance in the absence of neural compensation. Hippocampus 21 , 803–814 (2011).
PubMed Google Scholar
Park, D. C. & Reuter-Lorenz, P. The adaptive brain: aging and neurocognitive scaffolding. Annu. Rev. Psychol. 60 , 173–196 (2009).
Davis, S. W., Dennis, N. A., Daselaar, S. M., Fleck, M. S. & Cabeza, R. Que PASA? The posterior-anterior shift in aging. Cereb. Cortex N. Y. N 1991 18 , 1201–1209 (2008).
Gilbert, J. R. & Moran, R. J. Inputs to prefrontal cortex support visual recognition in the aging brain. Sci. Rep . 6 (2016).
Hoyau, E. et al . Aging modulates fronto-temporal cortical interactions during lexical production. A dynamic causal modeling study. Brain Lang. 184 , 11–19 (2018).
Salthouse, T. A Theory of Cognitive Aging . (Elsevier, 1985).
Salthouse, T. A. Aging associations: influence of speed on adult age differences in associative learning. J. Exp. Psychol. Learn. Mem. Cogn. 20 , 1486–1503 (1994).
Salthouse, T. A. The processing-speed theory of adult age differences in cognition. Psychol. Rev. 103 , 403–428 (1996).
Guest, D., Howard, C. J., Brown, L. A. & Gleeson, H. Aging and the rate of visual information processing. J. Vis. 15 , 10 (2015).
Schneider, B., Pichora-Fuller, M., Craik, F. I. M. & Salthouse, T. A. Implication of perceptual deterioration for cognitive aging research. In The handbook of Aging and Cognition 155–219 (2008).
Roberts, K. L. & Allen, H. A. Perception and Cognition in the Ageing Brain: A Brief Review of the Short- and Long-Term Links between Perceptual and Cognitive Decline. Front. Aging Neurosci . 8 (2016).
Chen, S. P., Bhattacharya, J. & Pershing, S. Association of Vision Loss With Cognition in Older Adults. JAMA Ophthalmol , https://doi.org/10.1001/jamaophthalmol.2017.2838 (2017).
Li, K. Z. H. & Lindenberger, U. Relations between aging sensory/sensorimotor and cognitive functions. Neurosci. Biobehav. Rev. 26 , 777–783 (2002).
Monge, Z. A. & Madden, D. J. Linking Cognitive and Visual Perceptual Decline in Healthy Aging: The Information Degradation Hypothesis. Neurosci. Biobehav. Rev. 69 , 166–173 (2016).
Salthouse, T. A. Neuroanatomical substrates of age-related cognitive decline. Psychol. Bull. 137 , 753–784 (2011).
Raz, N. & Lindenberger, U. Only time will tell: Cross-sectional studies offer no solution to the age–brain–cognition triangle: Comment on Salthouse (2011). Psychol. Bull. 137 , 790–795 (2011).
Folstein, M. F., Folstein, S. E. & McHugh, P. R. “Mini-mental state”. J. Psychiatr. Res. 12 , 189–198 (1975).
Snellen, H. Probebuchstaben zur bestimmung der sehscharfe . (Van de Weijer, 1862).
Jia, Y. et al . Caffe: Convolutional Architecture for Fast Feature Embedding. ArXiv14085093 Cs (2014).
Clarke, A., Devereux, B. J. & Tyler, L. K. Oscillatory Dynamics of Perceptual to Conceptual Transformations in the Ventral Visual Pathway. J. Cogn. Neurosci. 30 , 1590–1605 (2018).
Taylor, J. R. et al . The Cambridge Centre for Ageing and Neuroscience (Cam-CAN) data repository: Structural and functional MRI, MEG, and cognitive data from a cross-sectional adult lifespan sample. NeuroImage 144 , 262–269 (2017).
Taylor, J. R. et al . The Cambridge Centre for Ageing and Neuroscience (Cam-CAN) data repository: Structural and functional MRI, MEG, and cognitive data from a cross-sectional adult lifespan sample. NeuroImage , https://doi.org/10.1016/j.neuroimage.2015.09.018 (2015).
Taulu, S., Simola, J. & Kajola, M. Applications of the signal space separation method. IEEE Trans. Signal Process. 53 , 3359–3372 (2005).
Article ADS MathSciNet Google Scholar
Delorme, A. & Makeig, S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 134 , 9–21 (2004).
Chaumon, M., Bishop, D. V. M. & Busch, N. A. A practical guide to the selection of independent components of the electroencephalogram for artifact correction. J. Neurosci. Methods 250 , 47–63 (2015).
Qian, J., Hastie, T., Friedman, J., Tibshirani, R. & Simon, N. Glmnet for Matlab . Date of access: 2019 (2013).
Hayes, A. F. Introduction to mediation, moderation, and conditional process analysis: a regression-based approach . (The Guilford Press, 2013).
Download references
Acknowledgements
RB is a postdoctoral fellow of the Research Foundation Flanders (F.W.O.). The Cambridge Centre for Ageing and Neuroscience (Cam-CAN) research was supported by the Biotechnology and Biological Sciences Research Council (grant number BB/H008217/1). LKT, AC, MS are supported by an ERC Advanced Investigator Grant no 669820 awarded to LKT. KAT is supported by a British Academy Postdoctoral Fellowship (PF160048). We thank the Cam-CAN respondents and their primary care teams in Cambridge for their participation in this study.
Author information
Authors and affiliations.
Department of Psychology, University of Cambridge, Cambridge, CB2 3EB, UK
Rose Bruffaerts, Lorraine K. Tyler, Meredith Shafto, Kamen A. Tsvetanov, William D. Marslen-Wilson & Alex Clarke
Laboratory for Cognitive Neurology, Department of Neurosciences, University of Leuven, 3000, Leuven, Belgium
Rose Bruffaerts
Neurology Department, University Hospitals Leuven, 3000, Leuven, Belgium
Cambridge Centre for Ageing and Neuroscience (Cam-CAN), University of Cambridge and MRC Cognition and Brain Sciences Unit, Cambridge, CB2 7EF, UK
Lorraine K. Tyler, Kamen A. Tsvetanov, Carol Brayne, Edward T. Bullmore, Andrew C. Calder, Rhodri Cusack, Tim Dalgleish, John Duncan, Richard N. Henson, Fiona E. Matthews, William D. Marslen-Wilson, James B. Rowe, Karen Campbell, Teresa Cheung, Simon Davis, Linda Geerligs, Rogier Kievit, Anna McCarrey, Abdur Mustafa, Darren Price, David Samu, Jason R. Taylor, Matthias Treder, Janna van Belle, Nitin Williams, Lauren Bates, Tina Emery, Sharon Erzinçlioglu, Andrew Gadie, Sofia Gerbase, Stanimira Georgieva, Claire Hanley, Beth Parkin, David Troy, Tibor Auer, Marta Correia, Lu Gao, Emma Green, Rafael Henriques, Jodie Allen, Gillian Amery, Liana Amunts, Anne Barcroft, Amanda Castle, Cheryl Dias, Jonathan Dowrick, Melissa Fair, Hayley Fisher, Anna Goulding, Adarsh Grewal, Geoff Hale, Andrew Hilton, Frances Johnson, Patricia Johnston, Thea Kavanagh-Williamson, Magdalena Kwasniewska, Alison McMinn, Kim Norman, Jessica Penrose, Fiona Roby, Diane Rowland, John Sargeant, Maggie Squire, Beth Stevens, Aldabra Stoddart, Cheryl Stone, Tracy Thompson, Ozlem Yazlik, Dan Barnes, Marie Dixon, Jaya Hillman, Joanne Mitchell & Laura Villis
Author notes
A comprehensive list of consortium members appears at the end of the paper.
You can also search for this author in PubMed Google Scholar
Cambridge Centre for Ageing and Neuroscience
- Carol Brayne
- , Edward T. Bullmore
- , Andrew C. Calder
- , Rhodri Cusack
- , Tim Dalgleish
- , John Duncan
- , Richard N. Henson
- , Fiona E. Matthews
- , William D. Marslen-Wilson
- , James B. Rowe
- , Karen Campbell
- , Teresa Cheung
- , Simon Davis
- , Linda Geerligs
- , Rogier Kievit
- , Anna McCarrey
- , Abdur Mustafa
- , Darren Price
- , David Samu
- , Jason R. Taylor
- , Matthias Treder
- , Janna van Belle
- , Nitin Williams
- , Lauren Bates
- , Tina Emery
- , Sharon Erzinçlioglu
- , Andrew Gadie
- , Sofia Gerbase
- , Stanimira Georgieva
- , Claire Hanley
- , Beth Parkin
- , David Troy
- , Tibor Auer
- , Marta Correia
- , Emma Green
- , Rafael Henriques
- , Jodie Allen
- , Gillian Amery
- , Liana Amunts
- , Anne Barcroft
- , Amanda Castle
- , Cheryl Dias
- , Jonathan Dowrick
- , Melissa Fair
- , Hayley Fisher
- , Anna Goulding
- , Adarsh Grewal
- , Geoff Hale
- , Andrew Hilton
- , Frances Johnson
- , Patricia Johnston
- , Thea Kavanagh-Williamson
- , Magdalena Kwasniewska
- , Alison McMinn
- , Kim Norman
- , Jessica Penrose
- , Fiona Roby
- , Diane Rowland
- , John Sargeant
- , Maggie Squire
- , Beth Stevens
- , Aldabra Stoddart
- , Cheryl Stone
- , Tracy Thompson
- , Ozlem Yazlik
- , Dan Barnes
- , Marie Dixon
- , Jaya Hillman
- , Joanne Mitchell
- & Laura Villis
Contributions
R.B. Contributed unpublished analytic tools, Analyzed data, Wrote the paper, Made figures. L.K.T. Designed research, Analyzed data, Wrote the paper. M.S. Designed research, contributed unpublished analytic tools, Analyzed data. K.T. Performed research, contributed unpublished analytic tools, Analyzed data. Cam-CAN: Designed research, Performed research. A.C. Designed research, Contributed unpublished analytic tools, Analyzed data, Wrote the paper. All authors are in agreement on the final version of the paper. CamCan Corporate Authorship Membership.
Corresponding author
Correspondence to Lorraine K. Tyler .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Bruffaerts, R., Tyler, L.K., Shafto, M. et al. Perceptual and conceptual processing of visual objects across the adult lifespan. Sci Rep 9 , 13771 (2019). https://doi.org/10.1038/s41598-019-50254-5
Download citation
Received : 14 February 2019
Accepted : 02 September 2019
Published : 24 September 2019
DOI : https://doi.org/10.1038/s41598-019-50254-5
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Recurrent connectivity supports higher-level visual and semantic object representations in the brain.
- Jacqueline von Seth
- Victoria I. Nicholls
- Alex Clarke
Communications Biology (2023)
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

REVIEW article
A review of empirical evidence on different uncanny valley hypotheses: support for perceptual mismatch as one road to the valley of eeriness.

- Department of Computer Science, School of Science, Aalto University, Espoo, Finland
The uncanny valley hypothesis, proposed already in the 1970s, suggests that almost but not fully humanlike artificial characters will trigger a profound sense of unease. This hypothesis has become widely acknowledged both in the popular media and scientific research. Surprisingly, empirical evidence for the hypothesis has remained inconsistent. In the present article, we reinterpret the original uncanny valley hypothesis and review empirical evidence for different theoretically motivated uncanny valley hypotheses. The uncanny valley could be understood as the naïve claim that any kind of human-likeness manipulation will lead to experienced negative affinity at close-to-realistic levels. More recent hypotheses have suggested that the uncanny valley would be caused by artificial–human categorization difficulty or by a perceptual mismatch between artificial and human features. Original formulation also suggested that movement would modulate the uncanny valley. The reviewed empirical literature failed to provide consistent support for the naïve uncanny valley hypothesis or the modulatory effects of movement. Results on the categorization difficulty hypothesis were still too scarce to allow drawing firm conclusions. In contrast, good support was found for the perceptual mismatch hypothesis. Taken together, the present review findings suggest that the uncanny valley exists only under specific conditions. More research is still needed to pinpoint the exact conditions under which the uncanny valley phenomenon manifests itself.
Introduction
Masahito Mori predicted already in the 1970s that although people would in general have favorable reactions toward increasingly humanlike robots, almost but not fully human robots would be unsettling ( Mori, 2012 ). Mori used a hypothetical curve to characterize this relationship, and coined the sudden dip in this curve at almost humanlike levels as the uncanny valley (Figure 1 ). Although Mori focused on robots and other mechanical devices, the hypothesis was general enough to incorporate other domains as well. Some relevant technological innovations, such as prosthetic limbs and prototypes of anthropomorphic robots, already existed at the time when the uncanny valley hypothesis was published (cf. Mori, 2012 ). However, the uncanny valley hypothesis has become fully topical only during the last two decades or so, during which computer animation technologies have seen rapid advances. Although highly realistic computer-animated faces can already be produced (e.g., Alexander et al., 2010 ; Perry, 2014 ), contemporary computer animation techniques still tend to suffer from subtle imperfections related for example to rendering, lighting, surface materials, and movement dynamics. Hence, it is not surprising that the uncanny valley hypothesis has been adopted to explain the poor commercial success of some animated films in the media (cf. citations in Brenton et al., 2005 ; Geller, 2008 ; Eberle, 2009 ; Misselhorn, 2009 ; Pollick, 2010 ). The uncanny valley hypothesis has also motivated research in various fields beyond robotics and computer animation including, but not limited to, developmental psychology ( Matsuda et al., 2012 ), neuroimaging (e.g., Cheetham et al., 2011 ; Saygin et al., 2012 ), animal studies ( Steckenfinger and Ghazanfar, 2009 ), Bayesian statistics ( Moore, 2012 ), and philosophy ( Misselhorn, 2009 ).

Figure 1. Mori's uncanny valley curve demonstrating the non-linear relationship between the human-likeness of stimuli (clearly artificial to fully human-like) and the observers' sense of affinity for them (negative to positive) . Human-likeness levels ( L 1 to L4 ) that correspond roughly with the turning points of the curves have been highlighted on the horizontal axis, and the uncanny valley proper has been emphasized with a dark gray color. Adapted with permission from MacDorman (2005) .
Against this background, it is surprising that empirical evidence for the uncanny valley hypothesis is still ambiguous if not non-existent. Early research reviews from year 2005 noted the lack of empirical studies on the uncanny valley ( Brenton et al., 2005 ; Gee et al., 2005 ; Hanson, 2005 ). To our knowledge, empirical evidence for the existence of the uncanny valley has still not been reviewed systematically. Several reviews have elaborated the original hypothesis and its underlying mechanisms ( Ishiguro, 2006 , 2007 ; Tondu and Bardou, 2011 ) or applied the original hypothesis in specific contexts ( Eberle, 2009 ), but these reviews have not taken clear sides on the existence of the uncanny valley. Two recent reviews have concluded that the empirical evidence for the uncanny valley is either absent or inconsistent ( Pollick, 2010 ; Zlotowski et al., 2013 ). These reviews have, however, cited direct evidence from relatively few studies that pertained directly to their specific fields (psychology and human-robot interaction, respectively). A possible reason for the lack of empirical research reviews could be that although a plethora of uncanny valley articles have been published, it is difficult to identify which of them have tested the original hypothesis directly and which have been merely derived from it.
It is also possible that there exist not one but many plausible uncanny valley hypotheses. Because the original uncanny valley hypothesis was intended as a broadly applicable guideline rather than an explicit experimental hypothesis (cf. Pollick, 2010 ), it is likely to be consistent with several more specific hypotheses. Some of these hypotheses could be derived from established psychological constructs and theories. In some cases, minor adjustments to the original uncanny valley hypothesis could be justified. Because the two major dimensions of the uncanny valley—the human-likeness of stimuli and the observers' experience of affinity for them—were not defined clearly in the original uncanny valley formulation, these dimensions could be operationalized in various different ways. Consequently, different uncanny valley studies could end up addressing different theoretical constructs and hypotheses depending on their specific methodological decisions. Because the human-likeness is difficult to operationalize, confounding factors and other alternative explanations could also limit the conclusions that can be drawn from individual studies.
The main goal of the present article was to review up-to-date empirical research evidence for a framework of plausible uncanny valley hypotheses derived from the original uncanny valley article ( Mori, 2012 ) and other more recent publications. The review consists of five major sections. First, we will provide an interpretation of the original human-likeness and affinity dimensions of the uncanny valley (Section An Interpretation of the Uncanny Valley). We will argue that a literal interpretation of Mori's original examples, especially those involving morbid characters (i.e., corpses and zombies), would confound human-likeness with extraneous factors. We will also suggest that the original formulation of the affinity dimension could be interpreted both in terms of perceptual familiarity and emotional valence. Second, we will formulate a framework of empirically testable uncanny valley hypotheses based on the preceding analysis (Section A Framework of Uncanny Valley Hypotheses). In addition, we will reiterate the recent categorization ambiguity and perceptual mismatch hypotheses (e.g., Brenton et al., 2005 ; Pollick, 2010 ; Cheetham et al., 2011 ). Third, we will formulate explicit criteria for article inclusion and evaluation (Section Article Selection and Evaluation). Fourth, we will review empirical evidence for the formulated hypotheses based on the adopted evaluation criteria (Section Review of Empirical Evidence). Finally, we will discuss the implications and limitations of our findings and consider open questions in uncanny valley research (Section Discussion).
An Interpretation of the Uncanny Valley
What is human-likeness.
Human-likeness is not a single quality of artificial characters that could be traced back to specific static, dynamic, or behavioral features—instead, human-likeness could be varied in an almost infinite number of different ways. Mori (2012) himself used anecdotal examples to characterize different degrees of human-likeness. We have highlighted some of these examples in Figure 1 and summarized them in Table 1 . The hypothetical human-likeness levels corresponding with the selected examples have been labeled from L 1 to L 4 . Mori used industrial robots ( L 1 ) as an example of the least humanlike characters with any resemblance to real humans. Although clearly artificial, such characters have some remotely humanlike characteristics, such as arms for gripping objects. Stuffed animals and toy robots ( L 2 ) were placed close to the first peak of the uncanny curve. Like industrial robots, these characters are clearly artificial; however, unlike industrial robots, such characters have also been purposefully designed to resemble humans. Mori placed two different kinds of objects or characters near the bottom of the valley. First, Mori mentioned prosthetic hands ( L 3 ) as an example of manmade artifacts that have been meant to appear humanlike but that have failed to do so because of some artificial qualities. Second, Mori mentioned human corpses and zombies ( L m ) when considering danger avoidance as a speculative explanation of the uncanny valley. Finally, Mori used healthy humans ( L 4 ) as an example of full human-likeness. In these examples, Mori referred to both static and moving instances of similar characters (e.g., still and animate corpses) to illustrate how movement would amplify the uncanny curve (Figure 1 ).

Table 1. Focal points on the human-likeness dimension of the uncanny valley graph .
Table 1 also illustrates two extraneous factors that could affect affinity responses to the above anecdotal examples if they were taken literally. First, stuffed animals and toy robots could elicit positive reactions not only because they appear somewhat humanlike but because they have been purposefully designed to appear aesthetic. Similarly, human corpses, whether still or animate, would certainly not evoke negative reactions only because they appear humanlike but because they are morbid and horrifying. These considerations strongly suggest that Mori's original examples should not be adopted literally in empirical studies. However, once this approach is rejected, the question still remains which human-likeness manipulations should be used in empirical studies out of all imaginable possibilities. Although this question does not yet have an agreed upon answer, there seems to be a trend toward using image morphing and computer graphics (CG) techniques for manipulating facial stimuli in recent studies (cf. Table S1).
What Is Affinity?
Mori's original Japanese terms bukimi and shinwakan (or shin-wakan ) for the affinity dimension referred to several different concepts. The negative term bukimi translates quite unequivocally into eeriness ( Ho and MacDorman, 2010 ), although other similar terms such as creepiness and strangeness have also been used (cf. Ho et al., 2008 ). In contrast, the positive term shinwakan is an unconventional Japanese word, which does not have a direct equivalent in English ( Bartneck et al., 2007 , 2009 ). The earliest and the most common translation of this term has been familiarity; however, it has been argued that likability would be a more appropriate translation (ibid.). In the latest English translation of Mori's original article, shinwakan was translated as affinity (Mori, 1970/2012). Similarly, we have adopted affinity when referring to the bukimi – shinwakan dimension in the present article. Table 2 lists dictionary definitions (Merriam-Webster Online Dictionary; http://www.merriam-webster.com ; accessed 24.11.2014) for the most commonly used affinity terms. A closer inspection of these terms would suggest that all of them refer to various aspects of perceptual familiarity and emotional valence. Perceptual familiarity refers to recognizing that the perceived character has similar qualities as another object the observer is already well acquainted with (possibly, the observer himself or herself). Emotional valence covers various positive (liking, pleasantness, and attraction) and negative (aversive sensations) emotions elicited by the character. Although positive and negative affinity could be considered separately (e.g., Ho and MacDorman, 2010 ), emotional valence is an established psychological concept (e.g., Russell, 2003 ) that is able to incorporate both of them.

Table 2. Dictionary definitions for the common English translations of Mori's affinity dimension .
Given that the original terms for the affinity dimension (or at least their common translations) are ambiguous, empirical studies would be necessary for resolving which self-report items would be ideal for measuring affinity. Previous studies have suggested that eeriness is associated with other negative emotion terms such as fear, disgust, and nervousness ( Ho et al., 2008 ); or fear, unattractiveness, and disgust ( Burleigh et al., 2013 ). To our knowledge, only one previous study up to date has used factor analytic methods to develop a conclusive self-report questionnaire for uncanny valley studies ( Ho and MacDorman, 2010 ). This study identified orthogonal factors for human-likeness, eeriness (two separate factors: eerie and spine-tingling), and attractiveness. An informal evaluation would suggest some potential problems with this questionnaire, however. First, some of the questionnaire items are not necessarily ideal for measuring their intended constructs in all contexts. For example, the semantic differential items “ordinary—supernatural” and “without definite lifespan—mortal” could be inappropriate human-likeness measures when none of the evaluated stimuli are supernatural. Second, although the identified eeriness factors are consistent with Mori's original terms, their constituent items (e.g., “numbing—freaky” and “unemotional—hair-rising”) do not resemble items in typical emotion self-report questionnaires (cf. self-report items in Bradley and Lang, 1994 ). Third, familiarity items were not considered in the study, although familiarity would seem to be an integral part of the uncanny valley. Although future empirical studies might be useful for refining this scale, this work is an important step toward developing a common metric for the affinity dimension. The scale has already been applied in at least two studies ( Mitchell et al., 2011 ; MacDorman et al., 2013 ).
A Framework of Uncanny Valley Hypotheses
Figure 2 illustrates the preceding analysis of the uncanny valley phenomenon (Section An Interpretation of the Uncanny Valley) and the relations between the present hypotheses and the uncanny valley concepts.

Figure 2. A concept map demonstrating relations between the present uncanny valley hypotheses and different uncanny valley concepts derived from Mori (2012) . Dashed lines refer to constructs that have been explicated after Mori's original publication. Hypotheses: H1a—naïve UV proper, H1b—naïve HL, H1c—morbidity, H2a—UV proper for movement, H2b—HL for movement, H2c—movement modulation, H3a—category identification, H3b—perceptual discrimination, H3c—categorical identification difficulty, H3d—opposite perceptual discrimination, H3e—perceptual discrimination difficulty, H4a—inconsistent HL, H4b—atypicality; UV—uncanny valley, HL—human-likeness.
Naïve Hypotheses
The question of which specific human-likeness manipulations should be used in empirical uncanny valley studies could be sidestepped by assuming that any kind of manipulation would lead to the characteristic uncanny curve for affinity (Figure 1 ). However, this hypothesis is simplistic because it assumes that all imaginable human-likeness manipulations are equally relevant for the uncanny valley. Consequently, it could be referred to as a naïve uncanny valley hypothesis as opposed to more specific hypotheses (Section Refined Hypotheses). We have attempted to formulate this hypothesis so that it would be compatible with various human-likeness manipulations ranging from categorical manipulations with a minimal number of human-likeness levels to fully continuous manipulations. Figure 3 illustrates the original uncanny curve for the four most focal human-likeness levels (Table 1 ). These levels constitute the minimal set of human-likeness levels that could be used to capture the most relevant aspects of the original uncanny curve.

Figure 3. Predicted affinity levels (from negative to positive) for still and moving versions of characters representing different human-likeness levels . The characteristic uncanny curve is overlain on the data for illustration.
The core claim of the uncanny valley is that almost humanlike characters will elicit more negative affinity than any other characters (Figure 3 ). As can be seen in the darkened region of Figure 1 , this characteristic U-shaped curve forms the uncanny valley proper. Because almost humanlike characters would need to be compared to both more artificial and more humanlike characters, the bare minimum for testing this prediction would be three human-likeness levels (cf. Figure 3 ). Although not equally critical, the original uncanny valley hypothesis also predicts that, except for the uncanny valley proper, affinity will be more positive for increasingly humanlike characters. That is, affinity increases when moving from clearly artificial to somewhat humanlike characters, and there would also be a relative increase between somewhat and fully humanlike characters (Figure 3 ). Given that this hypothesis omits almost humanlike characters, at least the remaining three levels in Figure 3 would need to be used to test this prediction. These predictions can be formulated as the following hypotheses.
H1a (“naïve uncanny valley proper”): For any kind of human-likeness manipulation, almost humanlike characters will elicit more negative affinity (lower familiarity and/or more negative emotional valence) than any other more artificial or more humanlike characters .
H1b (“naïve human-likeness”): For any kind of human-likeness manipulation, more humanlike characters will elicit more positive affinity (higher familiarity and/or more positive emotional valence), with the possible exception of characters fulfilling H1a .
Morbidity Hypothesis
Although purposefully morbid characters could be adopted from the original uncanny valley formulation ( Mori, 2012 ) and used in empirical uncanny valley studies, such characters would confound the more interesting effects of varying human-likeness (Section What is Human-Likeness?). Although it is quite trivial that such characters should evoke negative affinity, we have nevertheless formulated the following hypothesis to help separate morbidity effects from those of other hypotheses.
H1c (“morbidity”): Morbid characters (e.g., corpses or zombies) will elicit more negative affinity (lower familiarity and/or more negative emotional valence) than any other characters .
Movement Hypotheses
In his original formulation, Mori (2012) also suggested that movement would amplify the uncanny curve. That is, the positive and negative affinity experiences elicited by the still characters should become more pronounced for moving characters. The role of movement could, however, be more complex than originally predicted. For example, although Mori considered movement as a dichotomous variable—it either is or is not present—movement features could also range in human-likeness and lead to an uncanny curve of their own. This leads to the following reformulations of the naïve uncanny hypotheses (H1a and H1b).
H2a (“uncanny valley proper for movement”): For any kind of human-likeness manipulation, “almost humanlike” movement patterns will elicit more negative affinity (lower familiarity and/or more negative emotional valence) than any other more artificial or more humanlike movement patterns .
H2b (“human-likeness for movement”): For any kind of human-likeness manipulation, more humanlike movement patterns will elicit more positive affinity (higher familiarity and/or more positive emotional valence), with the possible exception of movement patterns fulfilling H2a
The original movement hypothesis can be stated as follows.
H2c (“movement modulation”): Movement will amplify the affinity responses (changes in familiarity and/or emotional valence) associated with hypotheses H1a and H1b .
Testing movement hypotheses H2a–c would require the same number of minimum human-likeness levels as the more general hypotheses H1a and H1b (that is, three levels; the specific levels depending on the hypothesis).
Refined Hypotheses
Categorization ambiguity.
Early uncanny valley postulations have suggested that negative affinity would be caused by the ambiguity in categorizing highly realistic artificial characters as real humans or artificial entities (e.g., Ramey, 2005 [quoted in MacDorman and Ishiguro, 2006 ]; Pollick, 2010 ). Notably, this suggestion itself does not yet consider whether the human-likeness dimension of the uncanny valley is perceived continuously or categorically—that is, some intermediate characters could be difficult to categorize regardless of whether increasing human-likeness were perceived as a gradual continuum or discretely as artificial and human categories.
Categorical perception, which is an empirically and theoretically established construct in psychology, has been applied to the uncanny valley in recent empirical studies ( Cheetham et al., 2011 , 2014 ). Loosely speaking, categorical perception refers to the phenomenon where the categories possessed by an observer influence his or her perceptions ( Goldstone and Hendrickson, 2010 ). Specifically, categorical perception is thought to occur when the perceptual discrimination is enhanced for pairs of perceptually adjacent stimuli straddling a hypothetical category boundary between two categories, and decreased for equally spaced pairs belonging to the same category ( Repp, 1984 ; Harnad, 1987 ; Goldstone and Hendrickson, 2010 ). Applied to the uncanny valley, categorical perception would mean that “[… ] irrespective of physical differences in humanlike appearance, objects along the DOH [degree of human-likeness] are treated as conceptually equivalent members of either the category ‘non-human’ or the category ‘human,’ except at those levels of physical realism at the boundary between these two categories.” ( Cheetham et al., 2011 , p. 2).
The two most commonly agreed upon criteria for experimental demonstrations of categorical perception are category identification and perceptual discrimination ( Repp, 1984 ; Harnad, 1987 ). The identification criterion means that stimulus identification in a labeling task should follow a steep slope such that labeling probabilities change abruptly at the hypothetical category boundary. Given that the location of category boundary cannot be known in advance, the minimum number of required stimulus levels for testing this hypothesis cannot be determined precisely. In practice, previous uncanny valley studies have employed at least 11 evenly distributed human-likeness steps along the human-likeness continuum (e.g., Looser and Wheatley, 2010 ; Cheetham et al., 2011 , 2014 ). Response times have been used as an index of uncertainty in the identification task (e.g., Pisoni and Tash, 1974 ; de Gelder et al., 1997 ). Assuming that categorization ambiguity should be the greatest at the category boundary, the slowest response times should also coincide with this point. That is,
H3a (“category identification”): A steep category boundary will exist on the human-likeness axis such that characters on the left and right sides of this boundary are labeled consistently as “artificial” and “human,” respectively; and/or this identification task will elicit the slowest response times at the category boundary .
The discrimination criterion refers to the above requirement that perceptual discrimination should be better for stimulus pairs straddling the category boundary than for equally spaced stimulus pairs falling on the same side of the category boundary. As an example from previous work ( Cheetham et al., 2011 ), the four stimulus pairs artificial–artificial, artificial–human, human–artificial, and human–human could be derived from identification results and employed in the perceptual discrimination task. All possible stimulus pairs that are differentiated by an equal number of steps on the human-likeness continuum could also be used (e.g., Cheetham et al., 2014 ). As a summary, to demonstrate categorical perception for the human-likeness dimension of the uncanny valley, the following hypothesis should be confirmed in addition H3a.
H3b (“perceptual discrimination”): Character pairs that straddle the category boundary between “artificial” and “human” categories will be easier to discriminate perceptually than equally different character pairs located on the same side of the boundary .
After demonstrating that the human-likeness dimension is perceived categorically, it would still need to be shown that category identification difficulty (i.e., H3a) is also associated with subjective experiences of negative affinity. The most straightforward assumption would be that identification uncertainty at the category boundary (“categorization ambiguity”) leads to negative affinity. Strictly speaking, this hypothesis is not fully consistent with categorical perception as it is commonly understood, given that the hypothesis refers only to the category identification criterion (cf. H3a), whereas perceptual discrimination criterion (H3b) has been considered as the hallmark of categorical perception (e.g., Harnad, 1987 ). Hence, categorization ambiguity could lead to negative affinity even in the absence of categorical perception (i.e., when only H3a but not H3b holds true). However, we have included this hypothesis, as it is consistent with the early uncanny valley literature ( Ramey, 2005 [quoted in MacDorman and Ishiguro, 2006 ]; Pollick, 2010 ). Hence, we have formulated this hypothesis as follows.
H3c (“categorical identification difficulty”): Characters that are located at the category boundary between “artificial” and “human” categories (as identified in H3a-b) will elicit more negative affinity (lower familiarity and/or more negative emotional valence) than any other characters that are located on the left or right sides of the category boundary .
As suggested recently by Cheetham et al. (2014) , the original uncanny valley hypothesis is based on the implicit assumption that perceptual discrimination is the most difficult for characters in the uncanny valley. However, assuming that the uncanny valley proper is thought of as coinciding with the category boundary and that this boundary is considered in terms of the categorical perception framework, it follows (as in Cheetham et al., 2014 ) that perceptual discrimination performance should actually be easier for characters at or in the close vicinity of the category boundary and not more difficult. As can be seen, this is the position taken in hypothesis H3b, and the perceptual discrimination difficulty assumption would be its opposite. Assuming that perceptual discrimination would be more difficult for characters in the uncanny valley, this difficulty should also be associated with negative affinity. These hypotheses can be stated as follows.
H3d (“opposite perceptual discrimination”): Character pairs that straddle the category boundary between “artificial” and “human” categories will be more difficult to discriminate perceptually than equally different character pairs located on the same side of the boundary .
H3e (“perceptual discrimination difficulty”): Increased perceptual discrimination difficulty for adjacent character pairs will be associated with heightened negative affinity (lower familiarity and/or more negative emotional valence) .
Perceptual Mismatch
Hypotheses H3a-e are attractive because they are related to the well-established framework of categorical perception. However, there are several reasons for considering also other alternatives to these categorization ambiguity and categorical perception based explanations. First, there is no a priori reason for expecting that the human-likeness dimension should be perceived categorically rather than continuously. For example, Campbell et al. (1997) has demonstrated that whereas morphed continua between human and cow faces are perceived categorically, similar continua between humans and monkeys are continuous. Similarly as humans and other primates, humans and anthropomorphic characters share many fundamental similarities that could place them in the same overarching category of humanlike entities (cf. Campbell et al., 1997 ; Cheetham et al., 2011 ). Second, negative affinity could of course be caused by some other mechanisms in addition to (or instead of) categorization ambiguity or categorical perception. For example, it is conceivable that some characters on the “human” side of the category boundary would be considered eerie because they appeared human but contained features that are not “entirely right.” In this hypothetical but conceivable example, a negative affinity peak would be located on the right side of the category boundary.
The perceptual mismatch hypothesis, which is theoretically independent from the categorization ambiguity and categorical perception hypotheses, has been presented recently as another explanation for the uncanny valley (e.g., MacDorman et al., 2009 ; Pollick, 2010 ). This hypothesis suggests that negative affinity would be caused by an inconsistency between the human-likeness levels of specific sensory cues. Clearly artificial eyes on an otherwise fully human-like face—or vice versa—is an example of such inconsistency. A particularly interesting proposal is that negative affinity would be caused by inconsistent static and dynamic information ( Brenton et al., 2005 ; Pollick, 2010 ). The bare minimum for testing this hypothesis would be four experimental manipulation levels (i.e., two realism levels × two different features). We have formulated this hypothesis in more general terms below.
H4a (“inconsistent human-likeness”): Characters with inconsistent artificial and humanlike features will elicit more negative affinity (lower familiarity and/or more negative emotional valence) than characters with consistently artificial or characters with consistently humanlike features .
Another form of perceptual mismatch could be higher sensitivity to deviations from typical human norms for more humanlike characters (e.g., Brenton et al., 2005 ; MacDorman et al., 2009 ). Deviations from human norms could result, for example, from such atypical features as grossly enlarged eyes. In the uncanny valley context, a plausible explanation for this phenomenon could be that the human visual system has acquired more expertise with the featural restrictions of other humans than with the featural restrictions of artificial characters (cf. Seyama and Nagayama, 2007 ). This hypothesis is also consistent with previous studies demonstrating that faces with typical or average features are considered more attractive than atypical faces (e.g., Langlois and Roggman, 1990 ; Rhodes et al., 2001 ). The atypicality hypothesis is similar to the above inconsistency hypothesis, given that atypical features could also be considered artificial. In fact, these two hypotheses have previously been considered as the same hypothesis (e.g., MacDorman et al., 2009 ). However, the atypicality hypothesis could refer to any deviant features besides artificiality (e.g., any distorted human features) and, unlike the inconsistency hypothesis, it makes a unilateral prediction related to only humanlike characters. Testing atypicality would require at least four experimental manipulation levels (artificial without atypical features, artificial with atypical features, human without atypical features, human with atypical features), and it could be formulated as follows.
H4b (“atypicality”): Humanlike characters with atypical features will elicit more negative affinity (lower familiarity and/or more negative valence) than artificial characters with atypical features, or either humanlike or artificial characters without atypical features .
Relation to the Original Uncanny Valley Hypothesis
The above hypotheses can be seen as refinements of the original uncanny valley hypothesis such that each of them narrows the human-likeness conditions under which the uncanny valley is expected to occur. These hypotheses pertain only to the uncanny valley proper (i.e., the “almost humanlike” level), and they cannot account for the first peak in the uncanny curve (cf. H1b and Figure 3 ). Otherwise, all of these hypotheses would appear to be consistent with the original uncanny valley hypothesis. For example, all of them seem to be consistent with the following quote: “One might say that the prosthetic hand has achieved a degree of resemblance to the human form [… ]. However, once we realize that the hand that looked real at first sight is actually artificial, we experience an eerie sensation.” ( Mori, 2012 , p. 99; see also MacDorman et al., 2009 , p. 698). Here, the prosthetic hand could have appeared eerie because it caused an artificial–human category conflict (H3), it was perceived as containing mismatching artificial and human features (H4a), or because the hand resembled a real hand without fulfilling all of the typical characteristics of human hands (H4b).
Article Selection and Evaluation
Evaluation criteria.
Table 3 displays the criteria that were used for selecting individual studies and for evaluating their results. These criteria are based on the general validity typology of Shadish et al. (2002) , which describes four different types of validity and their associated threats. Our goal was to identify justifiable and plausible threats for conclusions that can be drawn from the reviewed studies to hypotheses H1–H4. Hence, we have not attempted to develop a comprehensive list of all possible threats to the experimental validity of individual studies.

Table 3. Evaluation criteria for possible threats that limit the conclusions that could be drawn from individual studies to the present hypotheses .
Statistical Conclusion Validity
Statistical conclusion validity refers to the validity of inferring that the experimental manipulations and measured outcomes covaried with each other. At the bare minimum, any kind of statistical test should be used to provide evidence against chance results. The predicted U-shaped relationship between human-likeness and affinity (Figure 1 ) could be tested, for example, by using second-order correlation tests or analysis of variance followed by post-hoc comparisons. Linear correlation test would, however, not be sufficient for testing the predicted nonlinear relationship. Statistical conclusion validity could also be compromised by uncontrolled variation in the stimuli. This issue could be a particular concern for realistic stimuli (e.g., video game characters), whose features cannot be fully controlled. Extraneous variation could possibly be reduced by careful pretesting of stimuli and the inclusion of a large number of stimuli for each stimulus category.
Internal Validity
Internal validity refers to whether the observed outcomes were caused solely by experimental manipulations or whether they would have occurred even without them. Failure to check or confirm that human-likeness manipulations elicited consistent changes in perceived human-likeness would raise doubts over whether human-likeness was actually varied as intended, and would hence threaten internal validity.
Artifacts produced by human-likeness manipulations could also be considered as threats to internal validity (strictly speaking, these and any other confounds would be threats to construct validity in the original typology; cf. Shadish et al., 2002 , p. 95). We will consider image morphing artifacts in detail because this method has become popular in uncanny valley studies (cf. Table S1). Image morphing procedure is used to construct a sequence of gradual changes between two images (e.g., CG and human faces), and it consists of three phases: geometric correspondence is established between the images, a warping algorithm is applied to match the shapes of the original objects, and color values are interpolated between the original and warped images (e.g., Wolberg, 1998 ). Image morphing algorithms are prone to at least two kinds of artifacts (e.g., Wu and Liu, 2013 ). First, ghosting or double-exposure between images can occur if they contain different features, geometric correspondence has not been established adequately, or warping has not been applied. Second, color interpolation typically causes some blurring because it combines values from several pixels in the original images. Image morphing artifacts are a threat to validity because they are likely to coincide with intermediate levels of human-likeness (i.e., the most processed images). Cheetham and Jäncke (2013) have published a detailed guideline for applying morphing to facial images in uncanny valley studies. We have adopted the following criteria from their guideline: (i) several morphed continua should be used, (ii) selected endpoint images should be similar to each other (i.e., the faces should have similar geometries, have neutral facial expressions, and represent individuals of similar ages), (iii) alignment disparities should be avoided, and (iv) any external features should be masked (i.e., hair and ears, jewelry, and other external features).
Construct Validity
Construct validity refers to the extent to which the experimental manipulations and measured outcomes reflect their intended cause and effect constructs. For example, if the categorization ambiguity hypothesis (H3c or H3e) were demonstrated for specific stimuli without also demonstrating that these stimuli indeed were perceived categorically (H3a–b), it could be uncertain whether categorical perception was in fact involved. For the present purposes, we have required that the outcome measures should tap into the perceptual familiarity and/or emotional valence constructs (Section What is Affinity?). A specific threat related to self-reported familiarity is that it could be confounded with previous experience (e.g., a video game character could be familiar because of its popularity). The inclusion of outlier stimuli that represent other constructs besides varying human-likeness, for example morbidity (Section What is Human-Likeness?), would also threaten construct validity. In the present context, the hypothesis H1c was intended to set such constructs apart from human-likeness. It is also possible that affinity changes could in some cases be explained by other alternative constructs or phenomena (e.g., poor lip synchronization). A narrow range of manipulated human-likeness (e.g., only CG characters) could threaten construct validity because the results would not necessarily generalize to the full range of human-likeness. Application of human-likeness manipulations to only a single stimulus character could also threaten construct validity, if it were plausible that the manipulation results would contain other irrelevant features in addition to or instead of human-likeness.
External Validity
External validity refers to what extent the observed causal relationship between manipulated and observed variables can be generalized to other participants, experimental manipulations, and measured outcomes. Generalizability could be considered by comparing results from different studies. In practice, this would be difficult because of the heterogeneity of uncanny valley studies (cf. Table S1). For the present purposes, we have considered external validity only to exclude results from individual studies with clearly unrepresentative participant samples (e.g., only children).
Article Selection
We identified empirical uncanny valley studies by searching for the key term “uncanny valley” in the following search engines: Scopus (search in article title, abstract, and keywords; including secondary documents; N = 273), PubMed (search in all fields; N = 23), Science Direct (search in all fields; N = 134), and Web of Science (search in topic; N = 114). The obtained list of articles was augmented by other articles cited in them and by articles identified from other sources ( N = 6). This initial list ( N = 550) was screened by the first author. Duplicate entries and other than full-length articles published in peer-reviewed journals or conference proceedings were removed semi-automatically, and a cursory selection was done to exclude studies that had clearly not tested or considered the present hypotheses.
The screened list ( N = 125) was evaluated by all authors for eligibility. The following inclusion criteria were used (cf. Table 3 ): (i) the study had addressed, implicitly or explicitly, at least one of the hypotheses H1–H4; (ii) the study had used at least the minimum number of human-likeness levels for each hypothesis (cf. Section A Framework of Uncanny Valley Hypotheses); (iii) human-likeness of stimuli had been tested explicitly and confirmed; (iv) unless irrelevant for the tested hypothesis (i.e., H3a, H3b, and H3d), the study had used any of the conventional self-report items (likability, eeriness, familiarity, or affinity) or their equivalents for measuring affinity responses; and (v) justified statistical test had been used for testing the relationship between human-likeness and affinity. Two studies that had not tested human-likeness explicitly ( Seyama and Nagayama, 2007 ; Mäkäräinen et al., 2014 ) were nevertheless included because their human-likeness manipulations (image morphing from artificial to human faces and increasingly more abstract image manipulations, respectively) should have been expected to elicit trivial changes in perceived human-likeness. The final list of selected articles ( N = 17) is given in Table S1.
Article and Hypothesis Evaluation
The validity of conclusions from individual studies to hypotheses H1–H4 was evaluated using those evaluation criteria in Table 3 that had not already been adopted as inclusion criteria. All threats that were considered possible are listed in Table S1; however, only those threats that were considered both plausible and relevant for a specific hypothesis were used for excluding individual results. To allow critical evaluation and possible reanalysis of the present findings, we have attempted to highlight potential controversies related to the inclusion and evaluation of studies when reviewing the evidence for each hypothesis.
Because the selected articles had used heterogeneous methodologies and most of them had not reported effect size statistics, a quantitative meta-analysis would not have been appropriate. Instead, we opted to present the numbers of findings providing significant and non-significant evidence for each hypothesis. Because significant findings opposite to hypotheses were rare, they were pooled with the non-significant findings. Significant opposite findings have been mentioned separately in the text. Although this kind of “box score” approach is inferior to quantitative meta-analytic methods ( Green and Hall, 1984 ), it can nevertheless be used to provide an overall quantification of result patterns in the reviewed literature. Following a previous recommendation ( Green and Hall, 1984 ), we adopted a 30% threshold for deciding how many positive findings would be considered significant evidence in favor of a specific hypothesis. All of the reported findings were clearly above this threshold.
Review of Empirical Evidence
Naïve and morbidity hypotheses.
Empirical evidence for naïve, morbidity, and movement hypotheses is presented in Table 4 . Whereas the results clearly confirmed that affinity increased linearly across increasing human-likeness (H1b; 7 out of 9 studies), the predicted uncanny valley proper (H1a) received almost no support (1 out of 8 studies). As an exception, one study showed that pictures of intermediate prosthetic hands were more eerie than pictures of either mechanical or human hands ( Poliakoff et al., 2013 ). Two other studies provided results that resembled the uncanny curve ( McDonnell et al., 2012 ; Piwek et al., 2014 ); however, closer inspection suggested that these results could have been explained by outlier stimuli—that is, in terms of the hypothesis H1c. Another one of these studies ( McDonnell et al., 2012 ) could have provided evidence for H1a even after the outlier stimulus (purposefully ill character) was excluded. However, we considered this evidence inconsistent because both unrealistic (“ToonBare” rendering) and realistic (“HumanBasic” rendering) stimuli were found to be less appealing, friendly, and trustworthy than the remaining stimuli.

Table 4. Empirical evidence for hypotheses H1 (naïve hypotheses and morbidity) and H2 (movement) .
One of the studies in Table 4 ( Yamada et al., 2013 ) was excluded from the total count because of plausible morphing artifacts. This study found a U-shaped curve for self-reported pleasantness vs. morphed human-likeness, which could have been taken as support for H1a. However, in this study, only one pair of images had been selected for creating the human-likeness continuum, the selected cartoon and human face were very dissimilar from each other, and no masking had been used (cf. Section Article Selection; and Cheetham and Jäncke, 2013 ). Hence, it is possible that the lower pleasantness ratings for intermediate morphs could have resulted from morphing artifacts rather than intermediate human-likeness level. Consistently with this interpretation, other morphing studies ( Looser and Wheatley, 2010 ; Cheetham et al., 2014 ) with masked faces and multiple matched face pairs have failed to find a similar U-shaped curve for participants' evaluations. Another morphing study in Table 4 ( Seyama and Nagayama, 2007 ) had also used unmasked and quite dissimilar face pairs; however, it is unlikely that the lack of significant findings in this study could have been explained by morphing artifacts.
Several other potentially interesting studies were excluded during the initial selection and were hence not included in Table 4 or Table S1. For example, seminal uncanny valley studies ( Hanson, 2006 ; MacDorman, 2006 ; MacDorman and Ishiguro, 2006 ) were excluded because these studies did not report statistical test results for their findings. Because these studies also seemed to be influenced by morphing artifacts or the use of heterogeneous stimuli, their results for hypotheses H1a–b would nevertheless have been excluded as per our evaluation criteria. Results from several studies using realistic video game (or similar) characters have also been excluded either because they had not used statistical tests or because they had tested only linear correlations statistically. Most of the excluded studies had also deliberately included outlier characters (e.g., zombies) in their experimental stimuli (e.g., Schneider et al., 2007 ; Tinwell et al., 2010 ) and some of their results could have been explained by alternative explanations (e.g., audiovisual asynchrony; Tinwell et al., 2010 , in press ). We were able to identify only one published study without such outlier characters ( Flach et al., 2012 ) that could be taken as tentative evidence for H1a. This study demonstrated an uncanny curve for experienced discomfort (measured as a dichotomous variable) across video game and film characters that represented different human-likeness levels. We considered this evidence tentative because no statistical tests had been used; furthermore, the human-likeness range was somewhat constrained by the use of only CG characters.
We were able to identify only two studies ( Thompson et al., 2011 ; Piwek et al., 2014 ) that could be taken as evidence for the independent movement hypotheses H2a and H2b (Table 4 ). Results from these two studies were, however, consistent with those of the more general hypotheses H1a–b. That is, more humanlike movement was found to elicit higher affinity (H2b) in both studies, whereas a nonlinear uncanny valley curve (H2a) was not observed in either one of them. No studies addressing the modulatory effect of movement (H2c) survived the initial selection and further evaluation. Two studies demonstrated modulatory movement effects; however, these effects were specific to plausible outlier characters (ill-looking face in McDonnell et al., 2012 ; and zombie character in Piwek et al., 2014 ). Furthermore, these studies provided conflicting evidence: the former reported a significant increase and the latter a significant decrease in negative affinity for the moving characters.
Categorization Ambiguity Hypotheses
Empirical evidence for categorization ambiguity (H3) and perceptual mismatch (H4) hypotheses is presented in Table 5 . Four studies demonstrated that a category boundary existed for the identification of morphed facial image continua (H3a) and three of these studies additionally demonstrated that discrimination performance reached its peak when the images straddled this category boundary (H3b). The opposite prediction that discrimination performance would be the poorest in the vicinity of category boundary (H3d) was not supported by any study. These results hence provided reasonable evidence for the categorical perception of morphed human-likeness continua. In contrast, we managed to identify only two studies that tested affinity responses elicited by categorization ambiguity (H3c); neither of which could be taken as evidence in favor of this hypothesis. Opposite to hypothesis H3e, one study ( Cheetham et al., 2014 ) demonstrated that increased perceptual discrimination difficulty is associated with positive rather than negative affinity.

Table 5. Empirical evidence for hypotheses H3 (categorization ambiguity) and H4 (perceptual mismatch) .
Two other studies demonstrating favorable evidence for H3c were excluded from the total count because of plausible threats to validity. One image morphing study ( Yamada et al., 2013 ) demonstrated that the slowest identification task response times and the most negative likability evaluations coincided with each other; however, these results were excluded because the likability evaluations could plausibly have been influenced by morphing artifacts (cf. Section Naïve and Morbidity Hypotheses). Consistently, two participants in this study had reported spontaneously after the experiment that “they [had] evaluated the likability of the images based on the presence or absence of morphing noise” (ibid., 4). A more systematic evaluation would be necessary for deciding this issue, however. Another study (Study II in Burleigh et al., 2013 ) demonstrated that intermediate CG modifications between a goat-like and a fully humanlike face elicited the most eerie and unpleasant evaluations. This result was, however, not taken as evidence for the artificial–human categorization ambiguity (H3c) because the presence of categorization boundary was not tested explicitly. The reported positive uncanny valley finding is nevertheless important in the present context, because it could be interpreted as evidence that some human-likeness manipulations can lead to the uncanny valley. This finding was not included as additional evidence for the hypothesis H1a, however, because several other human-likeness manipulations in this study ( Burleigh et al., 2013 ) did not lead to similar findings.
Perceptual Mismatch Hypotheses
As illustrated in Table 5 , the results provided good support for the perceptual mismatch hypotheses related to both inconsistent realism levels (H4a; 4 out of 4 studies) and sensitivity to atypical features (H4b; 3 out of 4 studies). Two studies ( Seyama and Nagayama, 2007 ; MacDorman et al., 2009 ) using continuous human-likeness manipulations demonstrated that the most negative affinity evaluations were elicited when the mismatch between the realism of eyes and faces was the greatest (H4a) and when artificially enlarged eyes were paired with the most realistic (fully human) faces (H4b). Two other studies provided further support for H4a. One study ( Mitchell et al., 2011 ), which had used a factorial design between the realism of a face (robot or human) and voice (synthetic or human), demonstrated that mismatched face–voice pairs elicited higher eeriness than similar matched pairs. This result was included as support for H4a, although it should be noticed that these results are somewhat limited because only one pair of stimuli were used in the study. Another study ( Gray and Wegner, 2012 ) with conceptual stimuli demonstrated that machines with characteristically human experiences (i.e., capability to feel) and humans without such experiences were considered unnerving.
Consistently with H4b, one additional study ( Mäkäräinen et al., 2014 ) in Table 5 demonstrated that unnaturally exaggerated facial expressions were rated as more strange on increasingly humanlike faces. Contrary to H4b, one other study ( Burleigh et al., 2013 ) failed to demonstrate higher eeriness or unpleasantness for increasingly realistic faces. Although this non-significant finding was included in the total count, it is possible that this result could have been specific to the atypical feature (rolled-back eye) used in the study. Unlike enlarged eyes (e.g., Seyama and Nagayama, 2007 ), for example, such features could appear disturbing both on human and artificial faces.
Some studies that were excluded during the initial selection because they were not fully consistent with the specific formulation of the atypicality hypothesis (H4b) could nevertheless provide further evidence for it. One previous study ( Green et al., 2008 ) demonstrated that individuals show greater agreement when judging the “best looking” facial proportions of human rather than artificial faces. Similar greater agreement for more realistic CG textures was demonstrated also in the second study of MacDorman et al. (2009) . Furthermore, the third study in the same article showed that extreme facial proportions were considered the most eerie at close to humanlike levels. These results strengthen the view that individuals are more sensitive and less tolerant to deviations from typical norms when judging human faces.
This review considered evidence for the uncanny valley hypothesis ( Mori, 2012 ) based on a framework of specific hypotheses motivated by previous literature. The results showed that whereas all human-likeness manipulations do not automatically lead to the uncanny valley, positive uncanny valley findings have been reported in studies using perceptually mismatching stimuli. In particular, positive uncanny valley findings have been reported for stimuli in which the realism levels of artificial and humanlike features are inconsistent with each other (e.g., human eyes on an artificial face) or in which atypical features (e.g., grossly enlarged eyes) are present on humanlike faces.
Evidence for Different Kinds of Uncanny Valleys
Given that the original uncanny valley formulation did not provide specific guidelines for operationalizing human-likeness, we first considered the straightforward prediction that any kind of successful human-likeness manipulation would lead to the characteristic U-shaped affinity curve at almost humanlike levels. The reviewed studies, which had used various human-likeness manipulations, provided very little support for this hypothesis. Nonlinear uncanny valley effects were found only in two studies that had studied images of hands ( Poliakoff et al., 2013 and a continuous CG modification between nonhuman and human faces (Study II in Burleigh et al., 2013 ). Whether these results could be explained by chance, some characteristics specific to these stimuli or by the other reviewed hypotheses (e.g., categorization ambiguity or perceptual mismatch) remains an open question. The absence of evidence for the naïve uncanny valley hypothesis suggests that all kinds of human-likeness manipulations do not automatically lead to the uncanny valley. This would also suggest that individual studies using only one type of human-likeness manipulation should not be taken as conclusive evidence for the existence or nonexistence of the uncanny valley.
The original uncanny valley formulation also led to the secondary prediction that any kind of human-likeness manipulations would elicit linear increases in experienced affinity. This prediction was supported by the bulk of studies. This suggests that as a general rule, increasing human-likeness is associated with more positive experiences. Exceptions to this general rule could be possible, however, given that different kinds of human-likeness manipulations were not considered systematically in the present review.
We have suggested that Mori used corpses and zombies only as metaphorical examples when discussing threat avoidance as a possible explanation for the uncanny valley. Because these examples could nevertheless be taken literally, we also considered the hypothesis that such morbid characters would elicit negative affinity. Not surprisingly, this hypothesis received support. The inclusion of this hypothesis was successful because it helped us avoid drawing false conclusions for the other hypotheses. We conclude that empirical studies should not use purposefully morbid characters to test the existence of the uncanny valley (such stimuli could, of course, be included for other purposes). Although another possible confound, purposeful aesthetic, could also have originated from a literal interpretation of the original examples, this issue did not seem to affect any of the reviewed studies.
The original uncanny valley formulation proposed that movement would amplify the characteristic uncanny curve. The reviewed studies did not support this prediction. In contrast, the reviewed studies again demonstrated a linear relationship between affinity and the human-likeness of movement patterns. Furthermore, no nonlinear uncanny valley effects were observed. This suggests that movement information imposes similar linear effects on affinity as any other variation in human-likeness. However, it should be noticed that refined uncanny valley hypotheses (see below) have up to date been studied using only static stimuli, and that movement could possibly amplify their effects.
An alternative claim to the prediction that any kind of human-likeness manipulation leads to the uncanny valley would be that the uncanny valley phenomenon is manifested only under specific conditions. For evaluating this possibility, we considered empirical evidence for two refined uncanny valley proposals as they have been presented in existing literature. First, we considered the claim that the uncanny valley would be caused by an artificial–human categorization ambiguity. Although the reviewed studies demonstrated that morphed artificial–human face continua are perceived categorically, we were able to identify only tentative evidence for negative affinity in the vicinity of category boundary. Taken together, these results suggest that the uncanny valley phenomenon could not be explained solely in terms of categorical perception. However, given the small number of reviewed studies, more conclusive results could yet be obtained in future studies. The uncanny valley hypothesis could also be interpreted such that it predicts greater perceptual discrimination difficulty and more negative affect in the vicinity of category boundary (cf. Cheetham et al., 2014 ). Neither of these hypotheses was supported by the reviewed evidence.
Second, we considered two different perceptual mismatch hypotheses for the uncanny valley. The first hypothesis predicted that the negative affinity associated with the uncanny valley would be caused by inconsistent realism levels (e.g., artificial eyes on a humanlike face or vice versa). The second hypothesis predicted that such negative affinity would be elicited by heightened sensitivity to atypical features (e.g., grossly enlarged eyes) on humanlike characters. Both of these hypotheses received support from the reviewed studies. This finding is important because it confirms the existence of the uncanny valley at least under some specific conditions. Although previous reviews have presented categorization difficulty and perceptual mismatch hypotheses separately (e.g., Pollick, 2010 ), we are not aware that a further distinction would have been made between different perceptual mismatch hypotheses. Notably, the reviewed inconsistency and atypicality hypotheses lead to slightly different symmetric and asymmetric predictions. That is, the inconsistency hypothesis would predict that both artificial features on humanlike characters and humanlike features on artificial characters will elicit negative affinity, whereas the atypicality hypothesis would predict atypicality effects only for humanlike stimuli. Because both predictions received support, this suggests that inconsistent realism levels and atypical features could represent different conditions leading to the uncanny valley.
Open Research Questions
The present review raises several open questions for the uncanny valley research. One of these is the relation between the perceptual mismatch and categorization ambiguity hypotheses, which are not necessarily independent from each other. For example, it is possible that realism level inconsistency and feature atypicality effects could be reduced to categorical perception. This idea could possibly be tested by varying the level of inconsistency between features (e.g., by morphing eyes and faces separately as in Seyama and Nagayama, 2007 ) or by varying the level of feature atypicality (e.g., by varying the eye size of artificial and human faces), and testing whether such continua would fulfill the category identification and perceptual discrimination criteria for categorical perception ( Repp, 1984 ; Harnad, 1987 ). If these criteria were fulfilled, the results would link these effects to the broader framework of categorical perception.
Another open question relates to whether any kind of perceptual mismatch would lead to the uncanny valley or whether this effect would apply the best or even exclusively to specific features. For example, it might not be a coincidence that two of the reviewed studies demonstrated a perceptual mismatch effect for inconsistent realism levels specifically between the eyes and faces and specifically for enlarged eyes presented on human faces ( Seyama and Nagayama, 2007 ; MacDorman et al., 2009 ). One of the earliest reviews on the uncanny valley suggested that the eyes would have a special role in producing the uncanny valley ( Brenton et al., 2005 ). Consistently, one image morphing study has demonstrated that human-likeness manipulations of eyes explain most (albeit not all) of the perceived animacy of faces ( Looser and Wheatley, 2010 ). Similarly, one eye tracking study has demonstrated that eyes receive longer gaze dwell time on categorically ambiguous than on categorically unambiguous artificial faces ( Cheetham et al., 2013 ). To our knowledge, the previous suggestion that negative affinity would be caused by inconsistent static and dynamic information ( Brenton et al., 2005 ; Pollick, 2010 ) also remains unexplored.
The lack of universally agreed upon operational definition for the affinity dimension is a critical issue for uncanny valley studies. The self-report items eeriness, likability, familiarity, and affinity could be derived from Mori's (1970) original formulation. Unfortunately, an inspection of the reviewed articles (Table S1) reveals that none of these single terms alone have been adopted in more than half of the reviewed articles, even after similar terms would be considered as their synonyms (e.g., creepy and strange for eerie; pleasant or appealing for likable; and strange–familiar for familiar). Furthermore, although these items are consistent with the original formulation, they are not necessarily theoretically justified. One starting point for operationalizing affinity could be the questionnaire developed by Ho and MacDorman (2010) . In the present investigation, we have defined affinity in terms of perceptual familiarity and emotional valence. However, these constructs are clearly separate from each other, and their relation in the uncanny valley context would merit further investigation.
Future studies could also consider the possible influences of image morphing artifacts on uncanny valley findings, for example by conducting independent image quality evaluations for morphed stimuli. Although the risk of image morphing artifacts can be diminished considerably by following the guidelines of Cheetham and Jäncke (2013) , it is nevertheless possible that all confounding factors would not be avoided. Specifically, some ghosting for subtle facial features that are present in only one of the original images and slight blurring of contours generated by color interpolation could be unavoidable. By the nature of image morphing procedure, middle images in the series of morphed images are the most processed (in a technical sense) and hence they differ the most from natural images that constitute the endpoints of the series. Assuming that morphing artifacts were a realistic concern, the level of visual distortions produced by morphing would hence increase toward the middle of the generated human-likeness continua. The effects of such visual distortions would likely depend on the adopted research question and experimental design, however. Visual distortions, which would likely elicit negative evaluations, could lead to false negative affinity findings at the middle of the scale. On the other hand, it seems unlikely that visual distortions would explain the enhanced discrimination of stimuli straddling the scale middle (i.e., category boundary), as has been reported in typical categorical perception studies. If discrimination were based on comparing visual distortion levels, discrimination should on the contrary be enhanced for adjacent images that are located on either the left or right sides of the scale middle (i.e., for images with different distortion levels) but decreased for images that straddle the scale middle (i.e., for images with symmetric distortion levels).
Limitations
A plausible limitation related to our conceptual analysis of the original uncanny valley formulation ( Mori, 2012 ) is that we have relied on its English translation and other secondary sources instead of the original article written in Japanese.
Given our inclusion criteria, we have only considered studies that have operationalized affinity by self-report measures. We acknowledge that the heterogeneity of self-report items used in the previous studies has significantly reduced the value of comparing their results with one another. Another consequence is that we have omitted several relevant studies that have used physiological and behavioral measures, such as gaze tracking (e.g., Shimada et al., 2006 ) and haemodynamic response measurements in the brain (e.g., Chaminade et al., 2007 ; Saygin et al., 2012 ). It could also be argued that identification task response times, which have already been utilized in some categorical studies (e.g., Looser and Wheatley, 2010 ; Cheetham et al., 2011 ), would in fact be good operational definitions of perceptual familiarity. A justification for the present focus on self-report measurements is that their results are easier to interpret than those of physiological or behavioral measures. On the other hand, it should be acknowledged that physiological and behavioral measures could possibly avoid the present ambiguities related to self-report items.
The present conclusions depend on the adopted evaluation criteria, which are to some extent open to subjective interpretations. The function of these criteria was to avoid drawing false conclusions for our hypotheses; consequently, the criteria focused on plausible threats to conclusions that could be drawn from individual studies. We have attempted to facilitate the critical evaluation of this procedure by making it as transparent as possible. Because all possible aspects of experimental validity were not covered, the adopted criteria cannot and should not be taken as evidence for the experimental validity of the evaluated studies themselves. It should also be noticed that although we have specified the minimal human-likeness levels required for testing each hypothesis, this has been done solely for covering as many studies as possible. These minimal levels should hence not be taken as practical guidelines for empirical studies.
Although we have considered only the categorization ambiguity and perceptual mismatch explanations for the uncanny valley, it is worth noting that several other explanations have also been suggested (e.g., see MacDorman and Ishiguro, 2006 ). For example, it has been suggested that realistic appearance would elicit unrealistic cognitive expectations (expectation violation); that non-lifelike characters would trigger innate fear of death (terror management); and that some artificial characters would be eerie because they appear unfit, infertile, ill, or elicit other evolutionarily motivated aversive responses (evolutionary aesthetics). These explanations operate at different levels—the first two refer to proximate causes (i.e., how the uncanny valley is caused), whereas the evolutionary explanation refers to an ultimate cause (why the uncanny valley exists; cf. Scott-Phillips et al., 2011 ). Other refinements of the uncanny valley theory have suggested, for example, that behavior that is consistent with a character's appearance will lead to more positive reactions (i.e., a synergy effect; Minato et al., 2004 ; Ishiguro, 2006 ). Although these are all empirically testable hypotheses, we have not included them in the present review because they are either similar to the already included hypotheses (e.g., expectation violation vs. inconsistent realism hypotheses) or because they address higher-level topics that seem to presuppose the existence of the uncanny valley in one form or another.
We also acknowledge a recent refinement of the categorization ambiguity hypothesis, which has been suggested in two other articles of the present Frontiers Research Topic. As discussed by Schoenherr and Burleigh (2015) , the uncanny valley could represent an overarching “inverse mere-exposure effect” (ibid., 3), in which negative affect is caused by a lack of exposure to specific stimuli or stimulus categories (e.g., the authors cite the octopus as a species that is mundanely difficult to categorize). Burleigh and Schoenherr (2015) extend this idea by demonstrating that categorization ambiguity and the frequency of exposure to specific within-category stimuli contribute independently to the uncanny valley. For example, novel stimuli that were extrapolations of their original training stimuli were categorized easily but were nevertheless considered more eerie than stimuli within their training set. These recent considerations suggest that the categorization ambiguity hypothesis alone would not necessarily be sufficient for predicting emotional responses to the uncanny valley.
Importance and Implications for Research and Practice
Previous articles have already reviewed the uncanny valley phenomenon (e.g., Brenton et al., 2005 ; Gee et al., 2005 ; Hanson, 2005 ; Ishiguro, 2007 ; Eberle, 2009 ; Pollick, 2010 ; Tondu and Bardou, 2011 ; Zlotowski et al., 2013 ) and explicated, for example, the categorization ambiguity (e.g., Cheetham et al., 2011 ) and perceptual mismatch (e.g., MacDorman et al., 2009 ) hypotheses. However, to our knowledge, this article is the first systematic review of the empirical evidence for the uncanny valley. Conceptual analysis of the uncanny valley and consideration of plausible threats to the conclusions drawn from previous studies to the present hypotheses were used to improve the accuracy of our conclusions. The main contribution of the present article is the conclusion that all kinds of imaginable human-likeness manipulations do not automatically lead to the uncanny valley.
The practical implications of the present findings for computer animators and human-computer or human-robot interaction developers hinge on whether these findings can be generalized to realistic stimuli and contexts—that is, whether they are externally valid (the somewhat redundant term ecological validity could also be used; cf. Kvavilashvili and Ellis, 2004 ). The present review failed to identify direct evidence for or against the uncanny valley in realistic stimuli, with the exception of some tentative findings ( Flach et al., 2012 ; for other excluded but relevant studies, see Schneider et al., 2007 ; Tinwell, 2009 ; Tinwell et al., 2010 ). However, the reviewed results for artificial but well-controlled stimuli should be generalizable to computer animations and other realistic stimuli as well, given that the experimental stimuli clearly represented phenomena that would be likely to exist also in the real world (cf. Kvavilashvili and Ellis, 2004 ). For example, it is easy to imagine real computer-animated characters, whose individual features differ from each other with respect to their realism (i.e., perceptual mismatch due to inconsistent realism).
The present results could be taken to encourage the development of increasingly realistic computer animations (and other artificial characters), given that more humanlike characters were in general found to elicit more positive affinity. However, the perceptual mismatch results suggest that the uncanny valley remains a plausible threat for such characters. A generally humanlike character with subtle flaws in some focal features (e.g., eyes), would be likely to elicit negative affinity. The reviewed findings that individuals are increasingly sensitive to atypical features on more humanlike characters would suggest that avoiding the uncanny valley will become exponentially more difficult as the characters' overall appearance approaches the level of full human-likeness. This does not mean that computer animators or robotics researchers should shy away from the grand challenge of creating fully humanlike artificial entities. However, for many practical applications, there may be certain wisdom in the Mori's (1970) original advice of escaping the uncanny valley by attempting to design only moderately humanlike entities.
Taken together, the present review suggested that although not any kind of human-likeness manipulation leads to the uncanny valley, the uncanny valley could be caused by more specific perceptual mismatch conditions. Such conditions could originate, at least, from inconsistent realism levels between individual features (e.g., artificial eyes on a humanlike face) or from the presence of atypical features (e.g., atypically large eyes) on an otherwise humanlike character. Categorical perception of human-likeness continua ranging from artificial to human was supported; however, the present findings failed to support the suggestion that categorization ambiguity would be associated with experienced negative affinity. The results also highlight the need for developing a unified metric for evaluating the subjective, perceptual, and emotional experiences associated with the uncanny valley.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work has been in part supported by the HeCSE and UCIT graduate schools. We thank Dr. Pia Tikka, Prof. Niklas Ravaja, and Dr. Aline de Borst for fruitful discussions on the topic.
Supplementary Material
The Supplementary Material for this article can be found online at: http://www.frontiersin.org/journal/10.3389/fpsyg.2015.00390/abstract
Alexander, O., Rogers, M., Lambeth, W., Chiang, J.-Y., Ma, W.-C., Wang, C.-C., et al. (2010). The Digital Emily project: achieving a photorealistic digital actor. IEEE Comput. Graph. Appl . 30, 20–31. doi: 10.1109/MCG.2010.65
PubMed Abstract | Full Text | CrossRef Full Text | Google Scholar
Bartneck, C., Kanda, T., Ishiguro, H., and Hagita, N. (2007). “Is the uncanny valley an uncanny cliff?” in Proceedings of the IEEE 16th International Workshop on Robot and Human Interactive Communication (RO-MAN) (Jeju), 368–373.
Bartneck, C., Kanda, T., Ishiguro, H., and Hagita, N. (2009). “My robotic doppelgänger—a critical look at the uncanny valley,” in Proceedings of the IEEE 18th International Workshop on Robot and Human Interactive Communication (RO-MAN) (Toyama), 269–276.
Bradley, M. M., and Lang, P. J. (1994). Measuring emotion: the self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 25, 49–59. doi: 10.1016/0005-7916(94)90063-9
Brenton, H., Gillies, M., Ballin, D., and Chatting, D. (2005). “The uncanny valley: does it exist?” in Proceedings of the 19th British HCI Group Annual Conference (Edinburgh).
Burleigh, T. J., and Schoenherr, J. R. (2015). A reappraisal of the uncanny valley: categorical perception or frequency-based sensitization? Front. Psychol . 5:1488. doi: 10.3389/fpsyg.2014.01488
Burleigh, T. J., Schoenherr, J. R., and Lacroix, G. L. (2013). Does the uncanny valley exist? An empirical test of the relationship between eeriness and the human likeness of digitally created faces. Comput. Hum. Behav . 29, 759–771. doi: 10.1016/j.chb.2012.11.021
CrossRef Full Text | Google Scholar
Campbell, R., Pascalis, O., Coleman, M., Wallace, S. B., and Benson, P. J. (1997). Are faces of different species perceived categorically by human observers? Proc. R. Soc. Lond. B 264, 1429–1434. doi: 10.1098/rspb.1997.0199
Carter, E. J., Mahler, M., and Hodgins, J. K. (2013). “Unpleasantness of animated characters corresponds to increased viewer attention to faces,” in Proceedings of the ACM Symposium on Applied Perception (SAP) (Dublin), 35–40.
Chaminade, T., Hodgins, J., and Kawato, M. (2007). Anthropomorphism influences perception of computer-animated characters' actions. Soc. Cogn. Affect. Neurosci . 2, 206–216. doi: 10.1093/scan/nsm017
Cheetham, M., and Jäncke, L. (2013). Perceptual and category processing of the Uncanny Valley hypothesis' dimension of human-likeness: some methodological issues. J. Vis. Exp . 76:e4375. doi: 10.3791/4375
Cheetham, M., Pavlovic, I., Jordan, N., Suter, P., and Jäncke, L. (2013). Category processing and the human likeness dimension of the uncanny valley hypothesis: eye-tracking data. Front. Psychol . 4:108. doi: 10.3389/fpsyg.2013.00108
Cheetham, M., Suter, P., and Jäncke, L. (2011). The human likeness dimension of the “uncanny valley hypothesis”: behavioral and functional MRI findings. Front. Hum. Neurosci . 5:126. doi: 10.3389/fnhum.2011.00126
Cheetham, M., Suter, P., and Jäncke, L. (2014). Perceptual discrimination difficulty and familiarity in the Uncanny Valley: more like a “Happy Valley.” Front. Psychol . 5:1219. doi: 10.3389/fpsyg.2014.01219
de Gelder, B., Teunisse, J.-P., and Benson, P. J. (1997). Categorical perception of facial expressions: categories and their internal structure. Cogn. Emot . 11, 1–23. doi: 10.1080/026999397380005
Eberle, S. G. (2009). Exploring the uncanny valley to find the edge of play. Am. J. Play 2, 167–194.
Google Scholar
Flach, L. M., de Moura, R. H., Musse, S. R., Dill, V., Pinho, M. S., and Lykawka, C. (2012). “Evaluation of the uncanny valley in CG characters,” in Proceedings of the Brazilian Symposium on Computer Games and Digital Entertainmen (SBGames) (Brasiìlia), 108–116.
Gee, F. C., Browne, W. N., and Kawamura, K. (2005). “Uncanny valley revisited,” in Proceedings of the 14th IEEE International Workshop on Robot and Human Interactive Communication (Nashville, TN), 151–157.
Geller, T. (2008). Overcoming the uncanny valley. IEEE Comput. Graph. Appl . 28, 11–17. doi: 10.1109/MCG.2008.79
Goldstone, R. L., and Hendrickson, A. T. (2010). Categorical perception. Wiley Interdiscip. Rev. Cogn. Sci . 1, 69–78, doi: 10.1002/wcs.26
Gray, K., and Wegner, D. M. (2012). Feeling robots and human zombies: mind perception and the uncanny valley. Cognition 125, 125–130. doi: 10.1016/j.cognition.2012.06.007
Green, B. F., and Hall, J. A. (1984). Quantitative methods for literature reviews. Ann. Rev. Psychol . 35, 35–53. doi: 10.1146/annurev.ps.35.020184.000345
Green, R. D., MacDorman, K. F., Ho, C.-C., and Vasudevan, S. (2008). Sensitivity to the proportions of faces that vary in human likeness. Comput. Hum. Behav . 24, 2456–2474. doi: 10.1016/j.chb.2008.02.019
Hanson, D. (2005). “Expanding the aesthetic possibilities for humanoid robots,” in Proceedings of the 5th IEEE-RAS International Conference on Humanoid Robots (Tsukuba).
Hanson, D. (2006). “Exploring the aesthetic range for humanoid robots,” in Proceedings of the 28th Annual Conference of the Cognitive Science Society (CogSci) (Vancouver, BC), 16–20.
Harnad, S. R. (1987). “Introduction: psychophysical and cognitive aspects of categorical perception: a critical overview,” in Categorical Perception: The Groundwork of Cognition , ed S. R. Harnad (Cambridge: Cambridge University Press), 1–29.
PubMed Abstract | Full Text | Google Scholar
Ho, C.-C., and MacDorman, K. F. (2010). Revisiting the uncanny valley theory: developing and validating an alternative to the godspeed indices. Comput. Hum. Behav . 26, 1508–1518. doi: 10.1016/j.chb.2010.05.015
Ho, C.-C., MacDorman, K. F., and Pramono, Z. A. W. (2008). “Human emotion and the uncanny valley: a GLM, MDS, and isomap analysis of robot video ratings,” in Proceedings of the 3rd ACM/IEEE International Conference on Human Robot Interaction (Amsterdam), 169–176.
Ishiguro, H. (2006). Android science—toward a new cross-interdisciplinary framework. Interact. Stud . 7, 297–337. doi: 10.1075/is.7.03mac
CrossRef Full Text
Ishiguro, H. (2007). Scientific issues concerning androids. Int. J. Rob. Res . 26, 105–117. doi: 10.1177/0278364907074474
Kvavilashvili, L., and Ellis, J. (2004). Ecological validity and the real-life/laboratory controversy in memory research: a critical (and historical) review. Hist. Phil. Psychol . 6, 59–80.
Langlois, J. H., and Roggman, L. A. (1990). Attractive faces are only average. Psychol. Sci . 1, 115–121. doi: 10.1111/j.1467-9280.1990.tb00079.x
Looser, C. E., and Wheatley, T. (2010). The tipping point of animacy: how, when, and where we perceive life in a face. Psychol. Sci . 21, 1854–1862. doi: 10.1177/0956797610388044
MacDorman, K. F. (2005). “Androids as experimental apparatus: why is there an uncanny valley and can we exploit it?” in Proceedings of the Cognitive Science Society (CogSci) Workshop on Toward Social Mechanisms of Android Science (Stresa), 108–118.
MacDorman, K. F. (2006). “Subjective ratings of robot video clips for human likeness, familiarity, and eeriness: an exploration of the uncanny valley,” in Proceedings of the 28th Annual Conference of the Cognitive Science Society (CogSci) (Vancouver), 26–29.
MacDorman, K. F., Green, R. D., Ho, C.-C., and Koch, C. T. (2009). Too real for comfort? Uncanny responses to computer generated faces. Comput. Hum. Behav . 25, 695–710. doi: 10.1016/j.chb.2008.12.026
MacDorman, K. F., and Ishiguro, H. (2006). The uncanny advantage of using androids in cognitive and social science research. Interact. Stud . 7, 297–337. doi: 10.1075/is.7.3.03mac
MacDorman, K. F., Srinivas, P., and Patel, H. (2013). The uncanny valley does not interfere with level-1 visual perspective taking. Comput. Hum. Behav . 29, 1671–1685. doi: 10.1016/j.chb.2013.01.051
Mäkäräinen, M., Kätsyri, J., and Takala, T. (2014). Exaggerating facial expressions: a way to intensify emotion or a way to the uncanny valley? Cogn. Comput . 6, 708–721. doi: 10.1007/s12559-014-9273-0
Matsuda, Y.-T., Okamoto, Y., Ida, M., Okanoya, K., and Myowa-Yamakoshi, M. (2012). Infants prefer the faces of strangers or mothers to morphed faces: an uncanny valley between social novelty and familiarity. Biol. Lett . 8, 725–728. doi: 10.1098/rsbl.2012.0346
McDonnell, R., Breidt, M., and Bülthoff, H. H. (2012). Render me real? Investigating the effect of render style on the perception of animated virtual humans. ACM Trans. Graph . 31, 1–11. doi: 10.1145/2185520.2185587
Minato, T., Shimada, M., Ishiguro, H., and Itakura, S. (2004). Development of an android robot for studying human-robot interaction. Lect. Notes Comput. Sci . 3029, 424–434. doi: 10.1007/978-3-540-24677-0_44
Misselhorn, C. (2009). Empathy with inanimate objects and the uncanny valley. Mind Mach . 19, 345–359. doi: 10.1007/s11023-009-9158-2
Mitchell, W. J., Szerszen, K. A., Lu, A. S., Schermerhorn, P. W., Scheutz, M., and MacDorman, K. F. (2011). A mismatch in the human realism of face and voice produces an uncanny valley. I-Perception 2, 10–12. doi: 10.1068/i0415
Moore, R. K. (2012). A bayesian explanation of the “Uncanny Valley” effect and related psychological phenomena. Sci. Rep . 2:864. doi: 10.1038/srep00864
Mori, M. (1970). Bukimi no tani [the uncanny valley]. Energy 7, 33–35. Transl. K. F. MacDorman and N. Kageki 2012, IEEE Trans. Rob. Autom . 19, 98–100. doi: 10.1109/MRA.2012.2192811
Perry, T. S. (2014). Leaving the uncanny valley behind. IEEE Spectr . 51, 48–53. doi: 10.1109/MSPEC.2014.6821621
Pisoni, D. B., and Tash, J. (1974). Reaction times to comparisons within and across phonetic categories. Percept. Psychophys . 15, 285–290. doi: 10.3758/BF03213946
Piwek, L., McKay, L. S., and Pollick, F. E. (2014). Empirical evaluation of the uncanny valley hypothesis fails to confirm the predicted effect of motion. Cognition 130, 271–277. doi: 10.1016/j.cognition.2013.11.001
Poliakoff, E., Beach, N., Best, R., Howard, T., and Gowen, E. (2013). Can looking at a hand make your skin crawl? Peering into the uncanny valley for hands. Perception 42, 998–1000. doi: 10.1068/p7569
Pollick, F. E. (2010). In search of the uncanny valley. Lect. Note Inst. Comput. Sci. Telecomm . 40, 69–78. doi: 10.1007/978-3-642-12630-7_8
Ramey, C. H. (2005). “The uncanny valley of similarities concerning abortion, baldness, heaps of sand, and humanlike robot,” in Proceedings of the 5th IEEE-RAS International Conference on Humanoid Robots (Tsukuba).
Repp, B. H. (1984). “Categorical perception: issues, methods, findings,” in Speech and Language: Advances in Basic Research and Practise Vol. 10, ed. N. J. Lass (Orlando: Academic Press), 243–335.
Rhodes, G., Yoshikawa, S., Clark, A., Lee, K., McKay, R., and Akamatsu, S. (2001). Attractiveness of facial averageness and symmetry in non-Western cultures: in search of biologically based standards of beauty. Perception 30, 611–625. doi: 10.1068/p3123
Rosenthal–von der Pütten, R., and Krämer, N. C. (2014). How design characteristics of robots determine evaluation and uncanny valley related responses. Comput. Hum. Behav . 36, 422–439. doi: 10.1016/j.chb.2014.03.066
Russell, J. A. (2003). Core affect and the psychological construction of emotion. Psychol. Rev . 110, 145–172. doi: 10.1037/0033-295X.110.1.145
Saygin, A. P., Chaminade, T., Ishiguro, H., Driver, J., and Frith, C. (2012). The thing that should not be: predictive coding and the uncanny valley in perceiving human and humanoid robot actions. Soc. Cogn. Affect. Neurosci . 7, 413–422. doi: 10.1093/scan/nsr025
Schneider, E., Wang, Y., and Yang, S. (2007). “Exploring the uncanny valley with Japanese video game characters,” in Proceedings of the Digital Games Research Association (DiGRA): Situated Play , ed B. Akira (Tokyo), 546–549.
Schoenherr, J. R., and Burleigh, T. J. (2015). Uncanny sociocultural categories. Front. Psychol . 5:1456. doi: 10.3389/fpsyg.2014.01456
Scott-Phillips, T. C., Dickins, T. E., and West, S. A. (2011). Evolutionary theory and the ultimate-proximate distinction in the human behavioral sciences. Perspect. Psychol. Sci . 6, 38–47. doi: 10.1177/1745691610393528
Seyama, J., and Nagayama, R. S. (2007). The uncanny valley: effect of realism on the impression of artificial human faces. Presence 16, 337–351. doi: 10.1162/pres.16.4.337
Shadish, W. R., Cook, T. D., and Campbell, D. T. (2002). Experimental and Quasi-experimental Designs for Generalized Causal Inference . Belmont, CA: Wadsworth.
Shimada, M., Minato, T., Itakura, S., and Ishiguro, H. (2006). “Evaluation of android using unconscious recognition,” in Proceedings of the IEEE-RAS International Conference on Humanoid Robots (Genova), 157–162.
Steckenfinger, S. A., and Ghazanfar, A. A. (2009). Monkey visual behavior falls into the uncanny valley. Proc. Natl. Acad. Sci. U.S.A . 106, 18362–18366. doi: 10.1073/pnas.0910063106
Thompson, J. C., Trafton, J. G., and McKnight, P. (2011). The perception of humanness from the movements of synthetic agents. Perception 40, 695–704. doi: 10.1068/p6900
Tinwell, A. (2009). Uncanny as usability obstacle. Lect. Notes Comput. Sci . 5621, 622–631. doi: 10.1007/978-3-642-02774-1_67
Tinwell, A., Grimshaw, M., and Nabi, D. A. (in press). The effect of onset asynchrony in audio-visual speech and the uncanny valley in virtual characters. Int. J. Digital Hum . 2.
Tinwell, A., Grimshaw, M., and Williams, A. (2010). Uncanny behaviour in survival horror games. J. Gaming Virtual Worlds 2, 3–25. doi: 10.1386/jgvw.2.1.3_1
Tondu, B., and Bardou, N. (2011). A new interpretation of Mori's uncanny valley for future humanoid robots. Int. J. Robot. Autom . 26, 337–348. doi: 10.2316/Journal.206.2011.3.206-3348
Wolberg, G. (1998). Image morphing: a survey. Vis. Comput . 14, 360–372. doi: 10.1007/s003710050148
Wu, E., and Liu, F. (2013). Robust image metamorphosis immune from ghost and blur. Vis. Comput . 29, 311–321. doi: 10.1007/s00371-012-0734-8
Yamada, Y., Kawabe, T., and Ihaya, K. (2013). Categorization difficulty is associated with negative evaluation in the “uncanny valley” phenomenon. Jpn. Psychol. Res . 55, 20–32. doi: 10.1111/j.1468-5884.2012.00538.x
Zlotowski, J., Proudfoot, D., Bartneck, C., and Złotowski, J. (2013). “More human than human: does the uncanny curve really matter?” in Proceedings of the HRI2013 Workshop on Design of Humanlikeness in HRI (Tokyo), 7–13.
Keywords: uncanny valley, human-likeness, anthropomorphism, perceptual mismatch, categorical perception, computer animation
Citation: Kätsyri J, Förger K, Mäkäräinen M and Takala T (2015) A review of empirical evidence on different uncanny valley hypotheses: support for perceptual mismatch as one road to the valley of eeriness. Front. Psychol . 6 :390. doi: 10.3389/fpsyg.2015.00390
Received: 15 August 2014; Accepted: 19 March 2015; Published: 10 April 2015.
Reviewed by:
Copyright © 2015 Kätsyri, Förger, Mäkäräinen and Takala. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jari Kätsyri, Department of Computer Science, School of Science, Aalto University, PO Box 15500, FIN-00076 Aalto, Espoo, Finland [email protected]
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
IMAGES
VIDEO
COMMENTS
Visual Perception Theory In Psychology
Second, there is the hypothesis of direct perception (HDP), which proposes that perceptual experience primarily is a process of directly revealing or disclosing the meaning of the perceived (Gallagher, 2008a; Zahavi, 2011). There are two complementary aspects to the HDP.
5.6 The Gestalt Principles of Perception
To understand perception, the signal codes and the stored knowledge or assumptions used for deriving perceptual hypotheses must be discovered. Systematic perceptual errors are important clues for appreciating signal channel limitations, and for discovering hypothesis-generating procedures.
Epistemology of Perception, The
Key Theories On The Psychology Of Perception
Perceptual Set In Psychology: Definition & Examples
If perception corresponds to hypothesis testing ( Gregory, 1980 ); then visual searches might be construed as experiments that generate sensory data. In this work, we explore the idea that saccadic eye movements are optimal experiments, in which data are gathered to test hypotheses or beliefs about how those data are caused.
Abstract. Philosophers concerned with perception traditionally consider phenomena of perception which may readily be verified by individual observation and a minimum of apparatus. Experimental psychologists and physiologists, on the other hand, tend to use elaborate experimental apparatus and sophisticated techniques, so that individual ...
In this paper, I advance a new hypothesis about what the ordinary concept of perceptual experience might be. To a first approximation, my hypothesis is that it is the concept of something that seems to present mind-independent objects. Along the way, I reveal two important errors in Michael Martin's argument for the very different view that the ordinary concept of perceptual experience is ...
The Perceptual Hypothesis opposes Inferentialism, which is the view that our knowledge of others' mental features is always inferential. The claim that some mental features are embodied is the claim that some mental features are realised by states or processes that extend beyond the brain. The view I discuss here is that the Perceptual ...
Perceptual analysis commonly refers to a specific process of the brain and mind— or a process of perception— that ultimately facilitates habituation, sensitization, and knowledge. ... the attentional selection will be dictated by the hypothesis that it is a beak and the content of its percept is more likely to be organized in a way that ...
Perceptual Sets in Psychology
Action-based Theories of Perception
Perception: The Sensory Experience of the World
Optimality and heuristics in perceptual neuroscience
Perceptual Learning - Stanford Encyclopedia of Philosophy
The core idea is that conscious perception correlates with activity, spanning multiple levels of the cortical hierarchy, which best suppresses precise prediction error: what gets selected for conscious perception is the hypothesis or model that, given the widest context, is currently most closely guided by the current (precise) prediction errors 5.
Perception: Conscious sensory experience. Electrical signals that represent something (eg. seeing a tiger) are somehow transformed into your experience of seeing a "tiger". Recognition: Our ability to place an object in a category, such as "tiger," that gives its meaning.
Beliefs and desires in the predictive brain
The information degradation hypothesis states that degraded perceptual input resulting from age-related neurobiological changes causes a decline in cognitive processes 54. We find that the ...
The perceptual mismatch hypothesis, which is theoretically independent from the categorization ambiguity and categorical perception hypotheses, has been presented recently as another explanation for the uncanny valley (e.g., MacDorman et al., 2009; Pollick, 2010). This hypothesis suggests that negative affinity would be caused by an ...
The Perceptual Hypothesis opposes Inferentialism, which is the view that our knowledge of others' mental features is always inferential. The claim that some mental features are embodied is the claim that some mental features are realised by states or processes that extend beyond the brain. The view I discuss here is that the Perceptual ...