- Increase Font Size

6 Mechanism of Speech Production
Dr. Namrata Rathore Mahanta
Learning outcome:
This module shall introduce the learner to the various components and processes that are at work in the production of human speech. The learner will also be introduced to the application of speech mechanism in other domains such as medical sciences and technology. After reading the module the learner will be able to distinguish speech from other forms of human communication and will be able to describe in detail the stages and processes involved in the production of human speech.
Introduction : What is speech and why it an academic discipline?
Speech is such a common aspect of human existence that its complexity is often overlooked in day to day life. Speech is the result of many interlinked intricate processes that need to be performed with precision. Speech production is an area of interest not only for language learners, language teachers, and linguists but also people working in varied domains of knowledge. The term ‘speech’ refers to the human ability to articulate thoughts in an audible form. It also refers to the formal one sided discourse delivered by an individual, on a particular topic to be heard by an audience.
The history of human existence and enterprise reveals that ‘speech’ was an empowering act. Heroes and heroines in history used ‘speech’ in clever ways to negotiate structures of power and overcome oppression. At times when the written word was an attribute of the elite and noble classes ‘speech’ was the vehicle which carried popular sentiments. In adverse times ‘speech’ was forbidden or regulated by authority. At such times poets and ordinary people sang their ‘speech’ in double meaning poems in defiance to authority. In present times the debate on an individual’s ‘right to free speech’ is often raised in varied contexts. As an academic discipline Speech Communication gained prominence in the 20th century and is taught in university departments across the globe. Departments of Speech Communication offer courses that engage with the speech interactions between people in public and private domain, in live as well as technologically mediated situations.
However, the student who peruses a study of ‘mechanism of speech production’ needs to focus primarily on the process of speech production. Therefore, the human brain and the physiological processes become the principal areas of investigation and research. Hence in this module ‘speech’ is delimited to the physiological processes which govern the production of different sounds. These include the brain, the respiratory organs, and the organs in our neck and mouth. A thorough understanding of the mechanism of speech production has helped correct speech disorders, simulate speech through machines, and develop devices for people with speech related needs. Needless to say, teachers of languages use this knowledge in the classroom in a variety of ways.
Speech and Language
In everyday parlance the terms ‘speech’ and ‘language’ are often used as synonyms. However, in academic use these two terms refer two very different things. Speech is the ‘spoken’ and ‘heard’ form of language. Language is a complex system of reception and expression of ideas and thoughts in verbal, non-verbal and written forms. Language can exist without speech but speech is meaningless without language. Language can exist in the mind in the form of a thought, on paper/screen in its orthographic form; it can exist in a gesture or action in its non-verbal form, it can also exist in a certain way of looking, winking or nodding. Thus speech is only a part of the vast entity of language. It is the verbal form of language.
Over the years Linguists have engaged themselves with the way in which speech and language exists within the human beings. They have examined the processes by which language is acquired and learnt. The role of the individual human being, the role of the society/community/the genetic or physiological attributes of the human beings all been investigated from time to time.
Ferdinand de Saussure a Swiss linguist who laid the foundation for Structuralism declared that language is imbibed by the individual within in a society or community. His lectures delivered at the University of Geneva during 1906-1911 were later collected and published in 1916 as Cours de linguistique générale . Saussure studied the relationship between speech and the evolution of language. He described language as a system of signs which exists in a pattern or structure. Saussure described language using terms such as ‘ langue ’ ‘ parole ’ and ‘langage ’. These terms are complex and cannot be directly translated. It would be misleading to equate Saussure’s ‘ langage ’ with ‘language’. However at an introductory stage these terms can be described as follows:
American linguist Avram Noam Chomsky argued that the human mind contains the innate source of language and declared that humans are born with a mind that is pre-programmed for language, i.e., humans are biologically programmed to use languages. Chomsky named this inherent human trait as ‘Innate Language’. He introduced two other significant terms: ‘Competence’ and ‘Performance’
‘Competence’ was described as the innate knowledge of language and ‘Performance’ as its actual use. Thus the concepts of ‘Innate Language’ ‘Language Competence’ and ‘Language Performance’ emerged and language came to be accepted as a cognitive attribute of humans while speech came to be accepted as one of the many forms of language communication. These ideas can be summarized in the chart given below:
In the present times speech and language are seen as interdependent and complementary attributes of humans. Current research focuses on finding the inner connections between speech and language. Consequently, the term ‘Speech and Language’ is used in most application based areas.
From Theory to Application
It is interesting to note that the knowledge of the intricacies of speech mechanism is used in many real life applications apart from Language and Linguistics. A vibrant area in Speech and Language application is ‘Speech and Language Processing’. It is used in Computational Linguistics, Natural Language Processing, Speech Therapy, Speech Recognition and many more areas. It is used to simulate speech in robots. Vocoders and Text to speech function (TTS) also makes use of speech mechanism. In Medical Sciences it is used to design therapy modules for different speech and language disorders, to develop advanced gadgets for persons with auditory needs. In Criminology it is used to recognize speech patterns of individuals and to identify manipulations in recorded speech patterns. Speech processing mechanism is also used in Music and Telecommunication in a major way.
What is Speech Mechanism?
Speech mechanism is a function which starts in the brain, moves through the biological processes of respiration, phonation and articulation to produce sounds. These sounds are received and perceived through biological and neurological processes. The lungs are the primary organs involved in the respiratory stage, the larynx is involved in the phonation stage and the organs in the mouth are involved in the articulatory stage.
The brain plays a very important role in speech. Research on the human brain has led to identification of certain areas that are classically associated with speech. In 1861, French physician Pierre Paul Broca discovered that a particular portion of the frontal lobe governed speech production. This area has been named after him and is known as Broca’s area. Injury to this area is known to cause speech loss. In 1874, German neuropsychiatrist Carl Wernicke discovered that a particular area in the brain was responsible for speech comprehension and remembrance of words and images. At a time when brain was considered to be a single organ, Wernicke demonstrated that the brain did not function as a single organ but as a multi pronged organ with distinctive functions interconnected with neural networks. His most important contribution was the discovery that brain function was dependent on these neural networks. Today it is widely accepted that areas of the brain that are associated with speech are linked to each other through complex network of neurons and this network is mostly established after birth, through life experience, over a period of time.
It has been observed that chronology and patterning of these neural networks differ from individual to individual and also within the same individual with the passage of time or life experience. The formation of new networks outside the classically identified areas of speech has also been observed in people who have suffered brain injury at birth or through life experience. Although extensive efforts are being made to replicate or simulate the plasticity and creativity of the human brain, complete replication has not been achieved. Consequently, complete simulation of human speech mechanism remains elusive.
The organs of speech
In order to understand speech mechanism one needs to identify the organs used to produce speech. It is interesting to note that each of these organs has a unique life-function to perform. Their presence in the human body is not for speech production but for other primary bodily functions. In addition to primary physiological functions, these organs participate in the production of speech. Hence speech is said to be the ‘overlaid’ function of these organs. The organs of speech can be classified according to their position and function.
- The respiratory organs consist of: The Lungs and trachea. The lungs compress air and push it up the trachea.
- The phonatory organs consist of the Larynx: The larynx contains two membrane- like structures called vocal cords or vocal folds. The vocal folds can come together or move apart.
- The articulatory organs consist of : lips, teeth, roof of mouth, tongue, oral and nasal cavities
The respiratory process involves the movement of air. Through muscle action of the lungs the air is compressed and pushed up to pass through the respiratory tract- trachea, larynx, pharynx, oral cavity, nasal cavity or both. While breathing in, the rib cage is expanded, the thoracic capacity is enlarged and lung volume is increased. Consequently, the air pressure in lungs drops down and the air is drawn into the lungs. While breathing out, the rib cage is contracted, the thoracic capacity is diminished and lung volume is decreased. Consequently, the air pressure in the lungs exceeds the outside pressure and air is released from the lungs to equalize it. Robert Mannel has explained the process through flowcharts and diagrammatic representations given below:
Once the air enters the pharynx, it can be expelled either through the oral passage, or through the nasal passage or through both depending upon the position of soft movable part of the roof of the mouth known as soft palate or velum.
Egressive and Ingressive Airstream: If the direction of the airstream is inward, it is termed as ‘Ingressive airstream. If the direction of the airstream is outward, it is ‘Egressive airstream’. Most languages of the world make use of Pulmonic Egressive airstream. Ingressive airstream is associated with Scandinavian languages of Northern Europe. However, no language can claim to use exclusively Ingressive or Egressive airstreams. While most languages of the world use predominantly Egressive airstreams, they are also known to use Ingressive airstreams in different situations. For extended list of use of ingressive mechanism you may visit Robert Eklund’s Ingressive Phonation and Speech page at www.ingressive.info .
Egressive process involves outward expulsion of air. Ingressive process involves inward intake of air. Egressive and Ingressive airstreams can be pulmonic (involving lungs) or non-pulmonic (involving other organs).
Non Pulmonic Airstreams: There are many languages which make use of non pulmonic airstream. In these cases the air expelled from the lungs is manipulated either in the pharyngeal cavity, or in the vocal tract, or in the oral cavity. Three major non pulmonic airstreams are:
In Ejectives, the air is trapped and compressed in the pharyngeal cavity by an obstruction in the mouth with simultaneous closure of the glottis. The larynx makes an upward movement which coincides with the removal of the obstruction causing the air to be released.
In Implosives, the air is trapped and compressed in the pharyngeal cavity by an obstruction in the mouth with simultaneous closure of the glottis. The larynx makes a downward movement which coincides with the removal of the obstruction causing the air to be sucked into the vocal tract.
In Clicks, the air is trapped and compressed in the oral cavity by lowering of the soft palate or velum and simultaneous closure of the mouth. Sudden opening causes air to be sucked in making a clicking sound. For a list of languages which use these airstream mechanisms you may visit https://community.dur.ac.uk/daniel.newman/phon10.pdf
While the process of phonation occurs before the airstream enters the oral or nasal cavity, the quality of speech is also determined by the state of the pharynx. Any irregularity in the pharynx leads to modification in speech quality.
The Phonatory Process: Inside the larynx are two membrane-like structures or folds called the vocal cords. The space between these is called the glottis. The vocal folds can be moved to varied distance. Robert Mannel has described five main positions of the vocal folds:
Voiceless: In this position the vocal folds are drawn far apart so that the air stream passes without any interference .
Breathy: Vocal folds are drawn loosely apart. The air passes making whisper like sound Voiced: Vocal folds are drawn close and are stretched. The air passes making vibrating sound.
Creaky : The vocal folds are drawn close & vibrate with maximum tension. Air passes making rough creaky sound. This sound is called ‘vocal fry’ and its use is on the rise amongst urban young women. However its sustained and habitual use is harmful.
For more details on laryngeal positions you may visit Robert Mannel’s page- http://clas.mq.edu.au/speech/phonetics/phonetics/airstream_laryngeal/laryngeal.html
You may see a small clip on the vocal fry by visiting the link – http://www.upworthy.com/what-is-vocal-fry-and-why-doesnt-anyone-care-when-men-talk- like-that
The Mouth The mouth is the major site for articulatory processes of speech production. It contains active articulators that can move and take different positions such as the tongue, the lips, the soft palate. There are passive articulators that cannot move but combine with the active articulators to produce speech. The teeth, the teeth ridge or the alveolar ridge, and the hard palate are the passive articulators.
Amongst the active articulators, the tongue can take the maximum number of positions and combinations to. Being an active muscle, its parts can be lowered or raised. The tongue is a major articulator in the production of vowel sounds. Position of the tongue determines the acoustics in the oral cavity during articulation of vowel sounds. For the purpose of identifying and describing articulatory processes, the tongue has been classified on two parameters.
a. The part of the tongue that is raised during the articulation process. There are four markers to classify the height to which the tongue is raised
- Maximum height
- Minimum height
- Two third of maximum height
- One third of maximum height
b. The height to which the tongue is raised during the articulation process. Three main parts of the tongue are identified as Front, Back, and Center.
For the purpose of description the positions of the tongue are diagrammatically represented through the tongue quadrilateral.
- Close: The Maximum height is called the high position or the close position. This is because the gap between the tongue and the roof of mouth is nearly closed.
- High-Mid or Half Close : Two third of maximum is called high- mid position or half – close position
- Low-Mid or Half Open : One third of maximum is called low – mid position or half- open position
- Low or Open : The Minimum height is called the Low or the Open position. This permits the maximum gap between the tongue and the roof of mouth.
The tongue also acts as an active articulator on the roof of the mouth to create obstruction in the oral cavity. Few prominent positions of the tongue are shown below
Lips: The lips are two strong muscles. In speech production the movement of the upper lip is less than that of the lower lip. The lips take different shapes: Rounded, Neutral or Spread
Teeth : The Upper Teeth are Passive Articulators.
The roof of the mouth:
The roof of the mouth has a hard portion and a soft portion which are fused seamlessly. The hard portion comprises of the Alveolar Ridge and the Hard Palate. The soft portion comprises of the Velum and the Uvula. The anterior part of the roof of the mouth is hard and unmovable. It begins from the irregular surface called alveolar ridge which lies behind the upper teeth. The alveolar ridge is followed by the hard palate which extends up to the centre of the tongue. The posterior part of the roof of the mouth is soft and movable. It lies after the hard palate and extends up to the small structure called the uvula.
The soft palate: It is movable and can take different positions during speech production.
- Raised position: In raised position the soft palate rests against the back of the mouth. The nasal passage is fully blocked and air passes through the mouth
- Lowered Position: In lowered position the soft palate rests against the back part of tongue in such a way that the oral passage is fully blocked and air passes through the nasal passage.
- Partially lowered Position: In partially lowered position, the oral as well as the nasal passages are partially open. Pulmonic air passes though the mouth as well as the nose to create ‘nasalized’ sounds.
The hard palate lies between the alveolar ridge and velum. It is a hard and unmovable part of the roof of the mouth. It lies opposite to the centre of the tongue and acts as a passive articulator against the tongue to produce sounds. Sounds produced with the involvement of the hard palate are called palatal sounds.
The alveolar ridge is the wavy part that lies just behind the teeth ridge opposite to the front of the tongue. It acts as a passive articulator against the tongue to produce sounds. Sounds produced with the involvement of the Alveolar ridge are called Alveolar sounds. Some sounds are created with the involvement of the posterior region of the Alveolar ridge. These sounds are called post alveolar sounds. Sometimes sounds are created with the involvement of the hindmost part of the alveolar ridge and the foremost part of the hard palate. Such sounds are called palato alveolar sounds.
Air stream mechanisms involved in speech production
The flow of air or the airstream is manipulated in a number of ways during production of speech. This is done with the movement of the active articulators in the oral cavity or the larynx. In this process the air stream plays a major role in the production of speech sound. Air stream works on the concept of air pressure. If the air pressure inside the mouth is greater than the pressure in the atmosphere, air will escape outward to create a balance. If the air pressure inside the mouth is lower than the pressure outside because of expansion of the oral or pharyngeal cavity, the air will move inward into the mouth to create balance. On the basis of the nature of the obstruction and manner of release, the following classification has been made:
Plosive: In this process there is full closure of the passage followed by sudden release of air. The air is compressed and when the articulators are suddenly removed the air in the mouth escapes with an explosive sound.
Affricate: In this process there is full closure of the passage followed by slow release of air.
Fricative : In this process the closure is not complete. The articulators come together to create a narrow passage. Air is compressed to pass through this narrow stricture so that air escapes with audible friction.
Nasal: The soft palate is lowered so that the oral cavity is closed. Air passes through the nasal passage creating nasal sounds. If the soft palate is partially lowered air passes simultaneously through the oral and nasal passages creating the ‘nasalized’ version of sounds. Lateral: The obstruction in the mouth is such that the air is free to pass on both sides of the obstruction.
Glide: The position of the articulators undergoes change during the articulation process. It begins with the articulators taking one position and then smoothly moving to another position.
Speech mechanism is a complex process unique to humans. It involves the brain, the neural network, the respiratory organs, the larynx, the oral cavity, the nasal cavity and the organs in the mouth. Through speech production humans engage in verbal communication. Since earliest times efforts have been made to comprehend the mechanism of speech. In 1791 Wolfgang von Kempelen made the first speech synthesizer. In the first few decades of the twentieth century scientific inventions such as x-ray, spectrograph, and voice recorders provided new tools for the study of speech mechanism. In the later part of the twentieth century electronic innovations were followed by the digital revolution in technology. These developments have made new revelations and have given new direction to the knowledge of human speech mechanism. In the digital world an understanding of speech mechanism has led to new applications in speech synthesis. Speech mechanism studies in present times are divided into areas of super specialization which focus intensively on any specialized attribute of speech mechanism.
References :
- Chomsky, Noam. Aspects of the Theory of Syntax.1965. Cambridge M.A.: MIT Press, 2015.
- Chomsky, Noam. Language and Mind. 3rd ed. New York: Cambridge University Press, 2006. Eklund, Robert. www.ingressive.info. Web. Accessed on 5 March 2017.
- Mannel,Robert. http://clas.mq.edu.au/speech/phonetics/phonetics/introduction/respiration.html. Web. Accessed on 5March 2017.
- Mannel,Robert. http://clas.mq.edu.au/speech/phonetics/phonetics/introduction/vocaltract_diagram.htm l. Web. Accessed on 5 March 2017.
- Mannel,Robert. http://clas.mq.edu.au/speech/phonetics/phonetics/airstream_laryngeal/laryngeal.html. Web. Accessed on 5 March 2017.
- Newman, Daniel. https://community.dur.ac.uk/daniel.newman/phon10.pdf. Web. Accessed on 5 March 2017.
- Saussure, Ferdinand. Course in General Linguistics. Translated by Wade Baskin. Edited by Perry Meisel and Haun Saussy. New York: Columbia University Press, 2011.
- Wilson, Robert Andrew and Frank C. Keil. Eds. The MIT Encyclopedia of Cognitive Sciences.1999. Cambridge M.A.: MIT Press, 2001.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
2.1 How Humans Produce Speech
Phonetics studies human speech. Speech is produced by bringing air from the lungs to the larynx (respiration), where the vocal folds may be held open to allow the air to pass through or may vibrate to make a sound (phonation). The airflow from the lungs is then shaped by the articulators in the mouth and nose (articulation).
Check Yourself
Video script.
The field of phonetics studies the sounds of human speech. When we study speech sounds we can consider them from two angles. Acoustic phonetics , in addition to being part of linguistics, is also a branch of physics. It’s concerned with the physical, acoustic properties of the sound waves that we produce. We’ll talk some about the acoustics of speech sounds, but we’re primarily interested in articulatory phonetics , that is, how we humans use our bodies to produce speech sounds. Producing speech needs three mechanisms.
The first is a source of energy. Anything that makes a sound needs a source of energy. For human speech sounds, the air flowing from our lungs provides energy.
The second is a source of the sound: air flowing from the lungs arrives at the larynx. Put your hand on the front of your throat and gently feel the bony part under your skin. That’s the front of your larynx . It’s not actually made of bone; it’s cartilage and muscle. This picture shows what the larynx looks like from the front.

This next picture is a view down a person’s throat.

What you see here is that the opening of the larynx can be covered by two triangle-shaped pieces of skin. These are often called “vocal cords” but they’re not really like cords or strings. A better name for them is vocal folds .
The opening between the vocal folds is called the glottis .
We can control our vocal folds to make a sound. I want you to try this out so take a moment and close your door or make sure there’s no one around that you might disturb.
First I want you to say the word “uh-oh”. Now say it again, but stop half-way through, “Uh-”. When you do that, you’ve closed your vocal folds by bringing them together. This stops the air flowing through your vocal tract. That little silence in the middle of “uh-oh” is called a glottal stop because the air is stopped completely when the vocal folds close off the glottis.
Now I want you to open your mouth and breathe out quietly, “haaaaaaah”. When you do this, your vocal folds are open and the air is passing freely through the glottis.
Now breathe out again and say “aaah”, as if the doctor is looking down your throat. To make that “aaaah” sound, you’re holding your vocal folds close together and vibrating them rapidly.
When we speak, we make some sounds with vocal folds open, and some with vocal folds vibrating. Put your hand on the front of your larynx again and make a long “SSSSS” sound. Now switch and make a “ZZZZZ” sound. You can feel your larynx vibrate on “ZZZZZ” but not on “SSSSS”. That’s because [s] is a voiceless sound, made with the vocal folds held open, and [z] is a voiced sound, where we vibrate the vocal folds. Do it again and feel the difference between voiced and voiceless.
Now take your hand off your larynx and plug your ears and make the two sounds again with your ears plugged. You can hear the difference between voiceless and voiced sounds inside your head.
I said at the beginning that there are three crucial mechanisms involved in producing speech, and so far we’ve looked at only two:
- Energy comes from the air supplied by the lungs.
- The vocal folds produce sound at the larynx.
- The sound is then filtered, or shaped, by the articulators .
The oral cavity is the space in your mouth. The nasal cavity, obviously, is the space inside and behind your nose. And of course, we use our tongues, lips, teeth and jaws to articulate speech as well. In the next unit, we’ll look in more detail at how we use our articulators.
So to sum up, the three mechanisms that we use to produce speech are:
- respiration at the lungs,
- phonation at the larynx, and
- articulation in the mouth.
Essentials of Linguistics Copyright © 2018 by Catherine Anderson is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Overview of Speech Production and Speech Mechanism
by BASLPCOURSE.COM
Overview of Speech Production and Speech Mechanism: Communication is a fundamental aspect of human interaction, and speech production is at the heart of this process. Behind every spoken word lies a series of intricate steps that allow us to convey our thoughts and ideas effectively. Speech production involves three essential levels: conceptualization, formulation, and articulation. In this article, we will explore each level and understand how they contribute to the seamless flow of communication.
Overview of Speech Production
Speech Production deals in 3 levels:
Conceptualization
Formulation , articulation .
Speech production is a remarkable process that involves multiple intricate levels. From the initial conceptualization of ideas to their formulation into linguistic forms and the precise articulation of sounds, each stage plays a vital role in effective communication. Understanding these levels helps us appreciate the complexity of human speech and the incredible coordination between the brain and the vocal tract. By honing our speech production skills, we can become more effective communicators and forge stronger connections with others.

Steps of Speech Production
Conceptualization is the first level of speech production, where ideas and thoughts are born in the mind. At this stage, a person identifies the message they want to convey, decides on the key points, and organizes the information in a coherent manner. This process is highly cognitive and involves accessing knowledge, memories, and emotions related to the topic.
During conceptualization, the brain’s language centers, such as the Broca’s area and Wernicke’s area, play a crucial role. The Broca’s area is involved in the planning and sequencing of speech, while the Wernicke’s area is responsible for understanding and accessing linguistic information.
For example, when preparing to give a presentation, the conceptualization phase involves structuring the content logically, identifying the main ideas, and determining the tone and purpose of the speech.
The formulation stage follows conceptualization and involves transforming abstract thoughts and ideas into linguistic forms. In this stage, the brain converts the intended message into grammatically correct sentences and phrases. The formulation process requires selecting appropriate words, arranging them in a meaningful sequence, and applying the rules of grammar and syntax.
At the formulation level, the brain engages the motor cortex and the areas responsible for language production. These regions work together to plan the motor movements required for speech.
During formulation, individuals may face challenges, such as word-finding difficulties or grammatical errors. However, with practice and language exposure, these difficulties can be minimized.
Continuing with the previous example of a presentation, during the formulation phase, the speaker translates the organized ideas into spoken language, ensuring that the sentences are clear and coherent.
Articulation is the final level of speech production, where the formulated linguistic message is physically produced and delivered. This stage involves the precise coordination of the articulatory organs, such as the tongue, lips, jaw, and vocal cords, to create the specific sounds and speech patterns of the chosen language.
Smooth and accurate articulation is essential for clear communication. Proper articulation ensures that speech sounds are recognizable and intelligible to the listener. Articulation difficulties can lead to mispronunciations or speech disorders , impacting effective communication.
In the articulation phase, the motor cortex sends signals to the speech muscles, guiding their movements to produce the intended sounds. The brain continuously monitors and adjusts these movements to maintain the fluency of speech.
For instance, during the presentation, the speaker’s articulation comes into play as they deliver each sentence, ensuring that their words are pronounced correctly and clearly.
Overview of Speech Mechanism

Speech Sub-system
The speech mechanism is a complex and intricate process that enables us to produce and comprehend speech. The speech mechanism involves a coordinated effort of speech subsystems working together seamlessly. Speech Mechanism is done by 5 Sub-systems:
- Respiratory System
Phonatory System
- Resonatory System
- Articulatory System
Regulatory System
I. Respiratory System
Respiration: The Foundation of Speech
Speech begins with respiration, where the lungs provide the necessary airflow. The diaphragm and intercostal muscles play a crucial role in controlling the breath, facilitating the production of speech sounds.
II. Phonatory System
Phonation: Generating the Sound Source
Phonation refers to the production of sound by the vocal cords in the larynx. As air from the lungs passes through the vocal cords, they vibrate, creating the fundamental frequency of speech sounds.
Phonation, in simple terms, refers to the production of sound through the vibration of the vocal folds in the larynx. When air from the lungs passes through the vocal folds, they rapidly open and close, generating vibrations that produce sound waves. These sound waves then resonate in the vocal tract, shaping them into distinct speech sounds.
The Importance of Phonation in Speech Production
Phonation is a fundamental aspect of speech production as it forms the basis for vocalization. The process allows us to articulate various speech sounds, control pitch, and modulate our voices to convey emotions and meaning effectively.
Mechanism of Phonation

Vocal Fold Structure
To understand phonation better, we must examine the structure of the vocal folds. The vocal folds, also known as vocal cords, are situated in the larynx (voice box) and are composed of elastic tissues. They are divided into two pairs, with the true vocal folds responsible for phonation.
The Process of Phonation
The process of phonation involves a series of coordinated movements. When we exhale, air is expelled from the lungs, causing the vocal folds to close partially. The buildup of air pressure beneath the closed vocal folds causes them to be pushed open, releasing a burst of air. As the air escapes, the vocal folds quickly close again, repeating the cycle of vibrations, which results in a continuous sound stream during speech.
III. Resonatory System
Resonance: Amplifying the Sound
The sound produced in the larynx travels through the pharynx, oral cavity, and nasal cavity, where resonance occurs. This amplification process adds richness and depth to the speech sounds.
IV. Articulatory System
Articulation: Shaping Speech Sounds
Articulation involves the precise movements of the tongue, lips, jaw, and soft palate to shape the sound into recognizable speech sounds or phonemes.
When we speak, our brain sends signals to the muscles responsible for controlling these speech organs, guiding them to produce different articulatory configurations that result in distinct sounds. For example, to form the sound of the letter “t,” the tongue makes contact with the alveolar ridge (the ridge behind the upper front teeth), momentarily blocking the airflow before releasing it to create the characteristic “t” sound.
The articulation process is highly complex and allows us to produce a vast array of speech sounds, enabling effective communication. Different languages use different sets of speech sounds, and variations in articulation lead to various accents and dialects.
Efficient articulation is essential for clear and intelligible speech, and any impairment or deviation in the articulatory process can result in speech disorders or difficulties. Speech therapists often work with individuals who have articulation problems to help them improve their speech and communication skills. Understanding the mechanisms of articulation is crucial in studying linguistics, phonetics, and the science of speech production.
Articulators are the organs and structures within the vocal tract that are involved in shaping the airflow to produce specific sounds. Here are some of the main articulators and the sounds they help create:

- The tongue is one of the most versatile articulators and plays a significant role in shaping speech sounds.
- It can move forward and backward, up and down, and touch various parts of the mouth to produce different sounds.
- For example, the tip of the tongue is involved in producing sounds like “t,” “d,” “n,” and “l,” while the back of the tongue is used for sounds like “k,” “g,” and “ng.”
- The lips are essential for producing labial sounds, which involve the use of the lips to shape the airflow.
- Sounds like “p,” “b,” “m,” “f,” and “v” are all labial sounds, where the lips either close or come close together during articulation.
- The teeth are involved in producing sounds like “th” as in “think” and “this.”
- In these sounds, the tip of the tongue is placed against the upper front teeth, creating a unique airflow pattern.
Alveolar Ridge:
- The alveolar ridge is a small ridge just behind the upper front teeth.
- Sounds like “t,” “d,” “s,” “z,” “n,” and “l” involve the tongue making contact with or near the alveolar ridge.
- The palate, also known as the roof of the mouth, plays a role in producing sounds like “sh” and “ch.”
- These sounds, known as postalveolar or palato-alveolar sounds, involve the tongue articulating against the area just behind the alveolar ridge.
Velum (Soft Palate):
- The velum is the soft part at the back of the mouth.
- It is raised to close off the nasal cavity during the production of non-nasal sounds like “p,” “b,” “t,” and “d” and lowered to allow airflow through the nose for nasal sounds like “m,” “n,” and “ng.”
- The glottis is the space between the vocal cords in the larynx.
- It plays a role in producing sounds like “h,” where the vocal cords remain open, allowing the airflow to pass through without obstruction.
By combining the movements and positions of these articulators, we can produce the vast range of speech sounds used in different languages around the world. Understanding the role of articulators is fundamental to the study of phonetics and speech production .
V. Regulatory system

Regulation: The Role of the Brain and Nervous System
The brain plays a pivotal role in controlling and coordinating the speech mechanism.
Broca’s Area: The Seat of Speech Production
Located in the left frontal lobe, Broca’s area is responsible for speech production and motor planning for speech movements.
Wernicke’s Area: Understanding Spoken Language
Found in the left temporal lobe, Wernicke’s area is crucial for understanding spoken language and processing its meaning.
Arcuate Fasciculus: Connecting Broca’s and Wernicke’s Areas
The arcuate fasciculus is a bundle of nerve fibers that connects Broca’s and Wernicke’s areas, facilitating communication between speech production and comprehension centers.
Motor Cortex: Executing Speech Movements
The motor cortex controls the muscles involved in speech production, translating neural signals into precise motor movements.
References :
- Speech Science Primer (Sixth Edition) Lawrence J. Raphael, Gloria J. Borden, Katherine S. Harris [Book]
- Manual on Developing Communication Skill in Mentally Retarded Persons T.A. Subba Rao [Book]
- SPEECH CORRECTION An Introduction to Speech Pathology and Audiology 9th Edition Charles Van Riper [Book]
You are reading about:
Share this:.
- Click to share on Twitter (Opens in new window)
- Click to share on Facebook (Opens in new window)
- Click to share on LinkedIn (Opens in new window)
- Click to share on Telegram (Opens in new window)
- Click to share on WhatsApp (Opens in new window)
- Click to print (Opens in new window)
If you have any Suggestion or Question Please Leave a Reply Cancel reply
Recent articles.
- Types of Earmolds for Hearing Aid – Skeleton | Custom
- Procedure for Selecting Earmold and Earshell
- Ear Impression Techniques for Earmolds and Earshells
- Speech and Language Disability Percentage Calculation
- Frenchay Dysarthria Assessment 2 (FDA 2): Scoring | Interpretation
Articulatory Mechanisms in Speech Production
- First Online: 18 April 2021
Cite this chapter

- Štefan Beňuš 2 , 3
1377 Accesses
The chapter builds the foundation for understanding how our bodies create speech. The discussion is framed around three main processes related to speaking: breathing, voicing and articulation. The discovery activities and commentaries bring awareness of multiple communicative functions produced by coordinated actions of various organs participating in speaking. Benus closes the chapter by comparing the vocal tracts of humans and chimpanzees and presenting the hypotheses of Philip Lieberman that the human speech apparatus evolved adaptively favouring the communicative function over the more basic ones linked to survival.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
But interested readers can find many great illustrations of the anatomy of the tongue in the internet, for example here https://www.yorku.ca/earmstro/journey/tongue.html .
Many authors refer to this part of the tongue as the ‘front’. However, this is not very intuitive and thus the term ‘body’ will be used in this book.
Anderson, Rindy C., Casey A. Klofstad, William J. Mayew, and Mohan Venkatachalam. 2014. Vocal fry may undermine the success of young women in the labor market. PLoS ONE 9 (5): e97506. https://doi.org/10.1371/journal.pone.0097506 .
Article Google Scholar
Fitch, Tecumseh W., Bart de Boer, Neil Mathur, and Asif A. Ghazanfar. 2016. Monkey vocal tracts are speech-ready. Science Advances 2 (12): e1600723. https://doi.org/10.1126/sciadv.1600723 .
Laver, John. 1980. The phonetic description of voice quality . Cambridge: Cambridge University Press.
Google Scholar
Lieberman, Philip. 2016. Comment on “Monkey vocal tracts are speech-ready”. Science Advances 3 (7): e1700442. https://doi.org/10.1126/sciadv.1700442 .
Lieberman, Philip. 1975. On the origins of language: An introduction to the evolution of human speech . New York: Macmillan.
Lieberman, Philip, Edmund S. Crelin, and Dennis H. Klatt. 1972. Phonetic ability and related anatomy of the newborn and adult human, neanderthal man, and the chimpanzee. American Anthropologist 74: 287–307.
Wolk, Lesley, Nassima B. Abdelli-Beruh, and Dianne Slavin. 2011. Habitual use of vocal fry in young adult female speakers. Journal of Voice 26(3): 111–116.
Yuasa, Ikuko P. 2010. Creaky Voice: A new feminine voice quality for young urban-oriented upwardly mobile American women? American Speech 85(3): 315–337.
Download references
Author information
Authors and affiliations.
Department of English and American Studies, Faculty of Arts, Constantine the Philosopher University in Nitra, Nitra, Slovakia
Štefan Beňuš
Institute of Informatics, Slovak Academy of Sciences, Bratislava, Slovakia
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Štefan Beňuš .
3.1 Electronic Supplementary Material
Ch3_links.docx.
(DOCX 28 kb)
Rights and permissions
Reprints and permissions
Copyright information
© 2021 The Author(s)
About this chapter
Beňuš, Š. (2021). Articulatory Mechanisms in Speech Production. In: Investigating Spoken English. Palgrave Macmillan, Cham. https://doi.org/10.1007/978-3-030-54349-5_3
Download citation
DOI : https://doi.org/10.1007/978-3-030-54349-5_3
Published : 18 April 2021
Publisher Name : Palgrave Macmillan, Cham
Print ISBN : 978-3-030-54348-8
Online ISBN : 978-3-030-54349-5
eBook Packages : Social Sciences Social Sciences (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 11 March 2020
Phonatory and articulatory representations of speech production in cortical and subcortical fMRI responses
- Joao M. Correia ORCID: orcid.org/0000-0001-6624-7012 1 , 2 ,
- César Caballero-Gaudes 1 ,
- Sara Guediche 1 &
- Manuel Carreiras ORCID: orcid.org/0000-0001-6726-7613 1 , 3 , 4
Scientific Reports volume 10 , Article number: 4529 ( 2020 ) Cite this article
8040 Accesses
21 Citations
2 Altmetric
Metrics details
- Motor cortex
Speaking involves coordination of multiple neuromotor systems, including respiration, phonation and articulation. Developing non-invasive imaging methods to study how the brain controls these systems is critical for understanding the neurobiology of speech production. Recent models and animal research suggest that regions beyond the primary motor cortex (M1) help orchestrate the neuromotor control needed for speaking, including cortical and sub-cortical regions. Using contrasts between speech conditions with controlled respiratory behavior, this fMRI study investigates articulatory gestures involving the tongue, lips and velum (i.e., alveolars versus bilabials, and nasals versus orals), and phonatory gestures (i.e., voiced versus whispered speech). Multivariate pattern analysis (MVPA) was used to decode articulatory gestures in M1, cerebellum and basal ganglia. Furthermore, apart from confirming the role of a mid-M1 region for phonation, we found that a dorsal M1 region, linked to respiratory control, showed significant differences for voiced compared to whispered speech despite matched lung volume observations. This region was also functionally connected to tongue and lip M1 seed regions, underlying its importance in the coordination of speech. Our study confirms and extends current knowledge regarding the neural mechanisms underlying neuromotor speech control, which hold promise to study neural dysfunctions involved in motor-speech disorders non-invasively.
Similar content being viewed by others

Basal ganglia and cerebellum contributions to vocal emotion processing as revealed by high-resolution fMRI

Hand posture affects brain-function measures associated with listening to speech

Motor engagement relates to accurate perception of phonemes and audiovisual words, but not auditory words
Introduction.
Despite scientific interest in verbal communication, the neural mechanisms supporting speech production remain unclear. The goal of the current study is to capture the underlying representations that support the complex orchestration of articulators, respiration, and phonation needed to produce intelligible speech. Importantly, voiced speech can be defined as an orchestrated task, where concerted phonation-articulation is mediated by respiration 1 . In turn, a more detailed neural specification of these gestures in fluent speakers is necessary to develop biologically plausible models of speech production. The ability to image the speech production circuitry at work using non-invasive methods holds promise for future application in studies that aim to assess potential dysfunction.
Upper motor-neurons located within the primary motor cortex (M1) exhibit a somatotopic organization that projects onto the brain-stem innervating the musculature of speech 2 , 3 , 4 , 5 , 6 . This functional organization of M1 has been replicated with functional magnetic resonance imaging (fMRI) for the lip, tongue and jaw control regions 7 , 8 , 9 , 10 , 11 . However, the articulatory control of the velum, which has an active role in natural speech (oral and nasal sounds) remains largely underspecified. Furthermore, laryngeal muscle control, critical for phonation, has more recently been mapped onto two separate areas in M1 4 , 5 , 12 : a ventral and a dorsal laryngeal motor area (vLMA and dLMA). Whereas the vLMA (ventral to the tongue motor area) is thought to operate the extrinsic laryngeal muscles, controlling the vertical position of the glottis within the vocal tract, and thereby modulating pitch in voice, the dLMA (dorsal to the lip motor area) is thought to operate intrinsic laryngeal muscles responsible for the adduction and abduction of the vocal cords, which is central to voicing in humans. Isolating the neural control of the intrinsic laryngeal muscles during natural voiced speech is critical for developing a mechanistic understanding of the speaking circuit. At least three research strategies have been adopted in the past in fMRI: (a) contrasting overt (voiced) and covert (imagery) speech 7 , 11 , 13 ; (b) production of glottal stops 12 ; and (c) contrasting voiced and whispered-like (i.e., exhalation) speech 14 . The latter potentially isolates phonation while preserving key naturalistic features of speech, including the sustained and partial adduction of the glottis, the synchronization of phonation, respiration and articulation, and the generation of an acoustic output. In this way, whispered speech can be considered an ecological baseline condition for isolating phonatory processes, free of confounds that may be present with covert speech and the production of glottal stops. Nevertheless, until now, its use has been limited across fMRI studies.
Despite the detailed investigations of M1, the somatotopic organization during overt speech in regions beyond M1 has been relatively unexplored, especially with fMRI. Studying articulatory processes using fMRI has several advantages over other neuroimaging techniques, including high spatial detail 15 , 16 , and simultaneous cortical and subcortical coverage, which can reveal brain connectivity during speech production helping to achieve a better understanding of the underlying neural circuitry. Despite the benefits of fMRI for speech production research, the signal collected during online speech tasks can be confounded by multiple artefactual sources 17 , for example those associated to head motion 18 and breathing 19 , 20 , 21 . Head motion is modulated by speech conditions and breathing affects arterial concentrations of CO 2 , regulating cerebral blood flow (CBF) and volume (CBV) and contributing to the measured fMRI signal. Here, we take advantage of several methodological strategies to avoid both head motion and breathing confounds by employing sparse-sampling fMRI 18 and experimental conditions with well-matched respiratory demands that are measured, respectively.
Using these methods, in this study we investigated fMRI representations of speech production, including articulatory and phonatory gestures across the human cortex and subcortex by employing multivariate decoding methods successfully used in fMRI studies of speech perception 22 , 23 , 24 . Articulatory representations were studied by discriminating individual speech gestures involving the lips, the tongue and the velum. Phonatory representations were studied by contrasting voiced and whispered speech. Furthermore, we recorded lung volume, articulatory measures and speech acoustics to rule out possible non-neural confounds in our analysis. Twenty fluent adults read a list of bi-syllabic non-words, balanced for bilabial and alveolar places of articulation, oral and nasal manners of articulation, and the non-articulated vowel ‘schwa’, using both voiced and whispered speech.
Our analysis employed multivariate decoding, based on anatomically-selected regions of interest (ROIs) that are part of the broad speech production circuitry, in combination with a recursive feature elimination (RFE) strategy 22 . Cortical results were further validated using a searchlight approach that uses a local voxel selection moved across the brain 25 . We expected to find articulatory-specific representations in multiple regions previously linked to somatotopic representations, which included the pre-motor cortex, SMA and pre-SMA, basal-ganglia, brain-stem and cerebellum 26 , 27 , 28 . We further expected to find evidence for larger fMRI responses for voiced in contrast to whispered speech in brain regions implicated in vocal fold adduction (e.g., dLMA 12 ). Finally, we investigated functional connectivity using seed regions responsible for lip and tongue control that were possible to localize at the individual subject-level. Accordingly, we expected connections between the different somatotopic organizations across the brain to differ for articulatory and phonatory processes, elucidating the distributed nature of the speaking circuitry 29 and the systems that support the control of different musculature for fluent speech. Overall, this study aims to replicate and extend prior fMRI work on the neural representations of voiced speech, which includes studying the neuromotor control of key speech articulators and phonation.
Participants
Twenty right-handed participants (5 males), native Spanish speaking, and aged between 20 and 44 years old (mean = 28, sd = 8.14) were recruited to this study using the volunteer recruitment platform ( https://www.bcbl.eu/participa ) at the Basque Centre on Cognition, Brain and Language (BCBL), Spain. Participation was voluntary and all participants gave their informed consent prior to testing. The experiment was conducted in accordance with the Declaration of Helsinki and approved by the BCBL ethics committee. Participants had MRI experience, and were informed of the scope of the project, and in particular the importance of avoiding head movements during the speech tasks. Two participants were excluded from group analyses due to exceeding head motion in the functional scans. We note that the group sample had an unbalanced number of male and female participants, which should be taken into account when comparing the results of this study to other studies. Attention to gender may be especially important when considering patient populations, where gender seems to play an important role in occurrence/recovery across different speech disorders 30 . Nevertheless, the objective of our research question relates to basic motor skills, which are not expected to differ extensively between male and female healthy adults with comparable levels of fluency 31 . For the voiced speech condition, participants were informed that they should utter the speech sounds at a comfortable low volume level as they would during a conversation with a friend located at one-meter distance. For the whispered speech condition, participants were informed and trained to produce soft whispering, minimizing possible compensatory supra-glottal muscle activation 32 . Because the fMRI sequence employed sparse sampling acquisition that introduced a silent period for production in absence of auditory MR-related noise, participants were trained to synchronize their speech with these silent periods prior to the imaging session, yielding production in more ecological settings.
Stimuli were composed of written text, presented for 1.5 second in Arial font-style and font-size 40 at the center of the screen with Presentation software ( https://www.neurobs.com ). Five text items were used (‘bb’, ‘dd’, ‘mm’, ‘nn’ and ‘әә’), where ‘ә’ corresponds to the schwa vowel (V) and consonant-consonant (CC) stimuli were instructed to be pronounced by adding the schwa vowel to form a CVCV utterance (e.g., ‘bb’ was pronounced ‘bәbә’). This assured the same number of letters across the stimuli. The schwa vowel involves minimal or no tongue and lip movements, which promoted a better discrimination of labial from tongue gestures. For the voiced speech task, items were presented in green color (RBG color code = [0 0 1]) and for the whispered speech task in red color (RGB color code = [1 0 0]). Throughout the fMRI acquisitions, we simultaneously obtained auditory recordings of individual (i.e., single token) productions using an MR-compatible microphone ( Optoacoustics, Moshav Mazor, Israel ) placed 2 to 4 cm away from the participants’ mouth. Auditory recordings (sampling rate = 22400 Hz) were used to obtain a list of acoustic measures per token, including speech envelope, spectrogram, formants F1 and F2, and loudness. Loudness was computed based on the average of the absolute acoustic signal in a time window of 100 ms centered at the peak of the speech envelope. Speech envelope was computed using the Hilbert transform: first, an initial high-pass filter was applied to the auditory signal (cut-off frequency = 150 Hz, Butterworth IIR design with filter order 4, implemented with the filtfilt Matlab function, Mathworks, version 2014); second, the Hilbert transform was computed using the Matlab function Hilbert ; finally, the magnitude signal (absolute value) of the Hilbert transform output was low-pass filtered (cut-off frequency = 8 Hz, Butterworth IIR design with filter order 4, implemented with the Matlab function filtfilt ). The spectrogram was computed using a short-time Fourier transformation based on the Matlab function spectrogram with a segment length of 100 time-points, overlap of 90% and 128 frequency intervals. From the spectrogram, F1 and F2 formants were computed based on a linear prediction filter ( lpc Matlab function).
The task was to produce a given item either as voiced or whispered speech during a silent gap introduced between consecutive fMRI scans (i.e., sparse sampling). The silent gap was 900 ms. The relevance of speech production during the silent period was three-fold: first, it avoided the Lombard effect (speech intensity compensation due to environmental noise) 33 ; second, it limited the contamination of head movements related to speech production during fMRI acquisition 18 ; and third, it facilitated voice recording. Trials were presented in a slow event-related design, with an inter-trial-interval (ITI) of 16 seconds. Within each trial, participants read a given item 3 times, separated by a single fMRI volume acquisition (time of repetition, TR = 2000 ms) (Fig. 1A ). At each utterance, a written visual text cue was presented for 1500 ms aligned with the beginning of the TR, and as instructed, it indicated participants to utter the corresponding item in the following silent gap (i.e., between 1100 ms and 2000 ms). Item repetition was included to obtain fMRI responses of greater magnitude (i.e., higher contrast-to-noise-ratio, CNR) 34 , 35 . Between consecutive trials, a fixation cross was presented to maintain the attention of the participants at the center of the visual field. Each run lasted 13 minutes. A session was composed of 4 functional runs. After the second run, two anatomical scans were acquired (T1-weighted and T2-weighted). After the third run, two scans (10 volumes) with opposite phase-encoding directions (anterior-posterior and posterior-anterior) were acquired for in-plane distortion correction. Diffusion weighted imaging (DWI) scans were also acquired between run 3 and 4 for future analyses, but not included in the present analyses.

Description of the task. ( A ) Overview of the task: MRI session composed of 4 functional runs divided in trials separated by an inter-trial-interval of 16 s. In each trial, participants produced a given item 3 times. Items are disyllabic non-words (e.g.., bәbә). ( B ) Stimuli and laryngeal control: stimuli was balanced for place of articulation (bilabial and alveolar) and manner of articulation (orals and nasals), and the controlled vowel schwa (ә); for the voiced condition, the IA (interarytenoid) and LCA (lateral cricoarytenoid) laryngeal muscles are recruited, whereas the PCA (posterior cricoarytenoid) is not, and the reversed for the whispered condition. ( C ) Detail of task for a given trial: 0.9 s of silent gap were introduced between consecutive TRs for speech production without MRI noise; top: sound recording in black and low-pass-filtered signal envelope in red; below-left: spectrogram image of an utterance example; below-right: scatter plot of F1 and F2 formants in a given participant (each dot represents an utterance), red for voiced and blue for whispered speech.
MRI acquisition and preprocessing
MRI was acquired at the BCBL facilities using a 3 Tesla Siemens MAGNETOM Prisma-fit scanner with a 64-channel head coil (Erlangen, Germany). Two anatomical scans included a T1-weighted and a T2-weighted MRI-sequences with an isotropic voxel resolution of 1 mm 3 (176 slices, field of view = 256 × 256 mm, flip angle = 7 degrees; GRAPPA accelaration factor 2). T1-weighted (MPRAGE) used a TR (time of repetition) = 2530 ms and TE (time of echo) = 2.36 ms. T2-weighted (SPACE) used a TR = 3390 ms and TE = 389 ms. These scans were used for anatomical-functional alignment, and for gray-matter segmentation and generation of subject-specific cortical surface reconstructions using FreeSurfer (version 6.0.0, https://surfer.nmr.mgh.harvard.edu ). Gray-matter versus white-matter segmentation used the T1-weighted tissue contrast and gray-matter versus cerebral-spinal-fluid (CSF) segmentation used the T2-weighted tissue contrast based on the FreeSurfer segmentation pipeline. Individual segmentations were visually inspected, but none required manual corrections. T2*-weighted functional images were acquired with an isotropic voxel resolution of 2 × 2 × 2 mm 3 using a gradient-echo (GRE) simultaneous multi-slice (aka multiband) EPI sequence 15 , 16 with multiband acceleration factor 5, FOV = 208 × 208 mm (matrix size = 104 × 104), 60 axial slices with no distance factor between slices, flip angle = 78 degrees, TR = 2000 ms including a silent gap of 900 ms, TE = 37 ms, echo spacing = 0.58, bandwidth = 2290 Hz/Px, and anterior-to-posterior (AP) phase-encoding direction. Slices were oriented axially (and in oblique fashion) along the inferior limits of the frontal lobe, brain-stem and cerebellum. In cases where coverage did not guarantee full brain coverage, a portion of the anterior temporal pole was excluded. A delay in TR of 900 ms was introduced between consecutive TRs to allow speech production in absence of MR-related noise and minimize potential head motion artifacts (i.e., TA = 1100 ms). All functional pre-processing steps were performed in AFNI software (version 18.02.16) 36 using the afni_proc.py program in the individual native space of each participant and included: slice-timing correction; removal of first 3 TRs (i.e., 6 seconds), blip-up (aka, top-up) correction using the AP and PA scans 37 , co-registration of the functional images due to head motion relative to the image with minimal distance from the average displacement; and co-registration between anatomical and functional images.
Simultaneously with fMRI acquisition, physiological signals of respiration (chest volume) and articulation (pressure sensor placed under the chin of the participants) were recorded using the MP150 BIOPAC system (BIOPAC, Goleta, CA, USA). The BIOPAC system included MRI triggers delivered at each TR onset for synchronization between the physiological signals and the fMRI data. The respiratory waveform was measured using an elastic belt placed around the participant’s chest, connected to a silicon-rubber strain assembly (TSD201 module). The belt inputs directly to a respiration amplifier (RSP100C module) at 1000 Hz sampling rate. A low-pass filter with 10 Hz cut-off frequency was applied to the raw respiratory signal. The same sampling rate and low-pass filter was used for the pressure sensor (TSD160C) measuring articulatory movements.
Univariate analyses
Univariate statistics were based on individual general linear models implemented in AFNI (3dDeconvolve) for each participant. At a first level analysis (subject-level) regressors of interest for each condition type (i.e., 10 condition types: 2 tasks - voiced and whispered, and 5 words - ‘bb’, ‘dd’, ‘mm’, ‘nn’ and ‘ee’) were created using a double-gamma function ( SPMG1 ) to model the hemodynamic response function (HRF). Each modelled trial consisted of 3 consecutive production events separated by 1 TR, i.e., 6 second duration. Regressors of non-interest modelling low frequency trends (Legendre polynomials up to order 5) and the 6 realignment parameters (translation and rotation) were included in the design matrix of the GLM. Time points where the Euclidean norm of the derivatives of the realignment motion parameters exceeded 0.4 mm were also included in the GLM to censor occasional excessive motion. At a second level univariate analysis (group-level statistics), volumetric beta value maps were projected onto the cortical surfaces of each subject using SUMA (version Sep. 12 2018, https://afni.nimh.nih.gov/Suma ), based on the gray-matter ribbon segmentation obtained in FreeSurfer. Individual cortical surfaces in SUMA were inflated and mapped onto a spherical template based on macro-level curvature (i.e., gyri and sulci landmarks), which guarantees the anatomical alignment across participants. T-tests were employed to obtain group-level statistics on the cortical surfaces using AFNI ( 3dttest ++). Statistical maps comprised voiced versus whispered, bilabial versus alveolar, and oral versus nasal items. Group-level alignment of the cerebellum and intra-cerebellar lobules relied on a probabilistic parcelation method 38 provided in the SUIT toolbox ( version 3.3 , www.diedrichsenlab.org/imaging/suit.htm ) in conjunction with SPM ( version 12 , www.fil.ion.ucl.ac.uk/spm ) using the T1 and fMRI activation maps in MNI space and NIFTI format. Alignment to a surface-based template of the cerebellum’s gray-matter assured a higher degree of lobule specificity and across subject overlap. All cerebellar maps were projected onto a flat representation of the cerebellum’s gray-matter together with lobule parcelations for display purposes.
Univariate results were not corrected for multiple comparisons. Corrected statistics depended on the sensitivity of MVPA. In order to prepare single trial features for the MVPA analyses (i.e., feature estimation), fMRI responses for each trial and voxel were computed in non-overlapping epochs of 16 secs locked to trial onset (i.e. 9 time points) from the residual pre-processed files after regressing out the Legendre polynomials, realignment parameters and motion censoring volumes. Subsequently, single-trial voxel-wise fMRI responses were demeaned and detrended for a linear slope.
ROI + RFE MVPA
We adopted an initial MVPA approach based on an anatomical ROI selection using the Desikan-Killiany atlas followed by a nested recursive feature elimination (RFE) procedure 22 that iteratively selected voxels based on their sensitivity to decode experimental conditions. Thirty-one anatomical ROIs were selected given their predicted role in speech production 3 , 39 , and covered cortical and sub-cortical regions including the basal-ganglia, cerebellum and brainstem. Because MVPA potentially offers superior sensitivity for discriminating subtle experimental conditions, it was possible to include additional ROIs that have been reported in other human speech production experiments as well as those known to show somatotopy in animal research but that have insofar not shown speech selectivity in human fMRI. The ROIs included the brainstem and a set 15 ROIs per hemisphere: cerebellum (cer), thalamus (thl), caudate (cau), putamen (put), pallidum (pal), hippocampus (hip), pars orbitalis (PrOr), pars opercularis (PrOp), pars triangularis (PrTr), post-central gyrus (ptCG), pre-central gyrus (prCG), supramarginal gyrus (SMG), insula (ins), superior temporal lobe (ST), superior frontal lobe (SF, including SMA - supplementary motor area - and pre-SMA regions). After feature selection, single-trial fMRI estimates were used in multivariate classification using SVM based on a leave-run-out cross-validation procedure. This procedure was used conjointly with RFE 22 . RFE iteratively (here, 10 iterations were used) eliminates the least informative voxels (here, 30% elimination criterion was used) based on a nested cross-validation procedure (here, 40 nested splits based on a 0.9 ratio random selection of trials with replacement was used). In other words, within each cross-validation, SVM classification was applied to the 40 splits iteratively. Every fourth split, we averaged the SVM weights, applied spatial smoothing using a 3D filter [3 × 3 × 3] masked for the current voxel selection and removed the least informative 30% of voxels based on their absolute values. This procedure based on eliminating the least informative features continued for 10 iterations. The final classification accuracy of a given ROI and contrast was computed as the maximum classification obtained across the 10 RFE iterations. Because the maximum criterion is used to obtain sensitivity from the RFE method, chance-level is likely inflated and permutation testing is required. Permutation testing consisted of 100 label permutations, while repeating the same RFE classification procedure for every participant, ROI and classification contrast. This computational procedure is slow but provides sensitivity for detecting spatially distributed multivariate response patterns 23 , 24 .
Classification for the ROI + RFE procedure was performed using support vector machines (SVM). SVM classification was executed in Matlab using the libsvm library and the sequential minimal optimization (SMO) algorithm. Validation of classification results that is inherent to MVPA was performed using a leave-run-out cross-validation procedure, where one experimental run is left-out for testing, while the data from the remaining runs is used for training the classification model. SVM was performed using a linear kernel for a more direct interpretation of the classification weights obtained during training. Furthermore, fMRI patterns were suggested to reflect somatotopic organizations, thus we expected to observe spatial clustering of voxel preferences in the mapping of the SVM weights. SVM regularization was further used to account for MVPA feature outliers during training, which would otherwise risk overfitting the classification model and reduce model generalization (i.e., produce low classification of the testing set). Regularization in the SMO algorithm is operationalized by the Karush-Kuhn-Tucker (KKT) conditions. We used 5% for KKT, which indicates the ratio of trials allowed to be misclassified during model training. Group-level statistics of the classification accuracies were performed against averaged permutation chance-level using two-tailed t-tests. Multiple comparisons correction (i.e., multiple ROIs) was done using FDR (q < 0.05).
Searchlight MVPA
In order to further validate the ROI + RFE approach, we conducted a second MVPA approach based on a moving spherical cortical ROI selection 25 . The searchlight allows us to determine whether multivoxel patterns are local. In contrast to the ROI + RFE approach, the searchlight approach is not influenced by the boundaries of the anatomical ROIs. It explores local patterns of fMRI activations by selecting neighboring voxels within a spherical mask (here, 7 mm radius, thus 3 voxels in every direction plus its centroid was used). This spherical selection was moved across the gray matter ribbon of the cortex.
Classification was performed using linear discriminant analysis (LDA) 40 , which allows massive parallel classifications in a short period of time, enabling the statistical validation of the method using label permutations (100 permutations). LDA and SVM have similar classification accuracies when the number of features is relatively low, as it is normally the case in the searchlight method 41 .
Classification validation was based on a leave-run-out cross-validation procedure. Group-level statistics of averaged classification accuracies (across cross-validation splits) were performed against permutation chance-level (theoretical chance-level is 0.5 since all classifications were binary) using two-tailed t-tests. Multiple comparisons correction (i.e., multiple searchlight locations) was done using FDR (q < 0.05). A possible pitfall of volumetric searchlight is that the set of voxels selected in the same searchlight sphere may be close to each other in volumetric distance but far from each other in topographical distance 42 . This issue is particularly problematic when voxels from the frontal lobe and the temporal lobe are considered within the same searchlight sphere. To overcome this possible lack of spatial specificity of the volumetric searchlight analysis, we employed a voxel selection method based on cluster contiguity in Matlab: first, each searchlight sphere was masked by the gray-matter mask; then a 3D clustering analysis was computed ( bwconncomp, with connectivity parameter = 26); finally, when more than one cluster was found in the masked searchlight selection, voxels from clusters not belonging to the respective centroid cluster were removed from the current searchlight sphere. This assured that voxels from topographically distant portions of the cortical mesh were not mixed.
Beta time-series functional connectivity
Finally, we explored functional connectivity from seed regions involved in speech articulation. Functional clusters obtained for lip and tongue control in M1 were used because these somatotopic representations were expected to enable localization at the individual subject level. Functional connectivity was assessed using beta time-series correlations 43 . This measure of functional connectivity focuses on the level of fMRI activation summarized per trial and voxel, while neglecting temporal oscillations in the fMRI time-series. Given our relatively slow sampling rate (TR = 2 seconds), this method was chosen over other functional connectivity methods that depend on the fMRI time-series. Pearson correlations were employed to assess the level of synchrony between the average beta time-series of the voxels within each seed region and each brain voxel. This method produces a correlation map (−1 to 1) per seed and participant, converted to z-scores with Fisher’s transformation. Group level statistics were assessed using a two-sided t-test against the null hypothesis of no correlation between the seed regions and brain voxels. Exploring beta time-series correlations in a sub-set of trials from a particular experimental condition relates to the specificity of the functional connectivity measure for that condition independently 43 . Finally, articulatory-specific and phonatory-specific connections were studied using statistical contrasts between the z-scores of different conditions. Hence, articulatory-specific connections of the tongue articulator are those for which the z-scores obtained from tongue-gesture conditions are significantly higher than from lip-gesture conditions, and vice-versa. Phonatory-specific connections of the tongue seed are those for which the z-scores obtained from tongue-voiced conditions are significantly higher than tongue-whispered conditions, and the same for the lip seed.
Behavioral and physiological measures
Chest volume was predictive of speech onset, regardless of the task (i.e., voiced or whispered speech). Measurement of articulatory movements using a pressure sensor placed under the chin of participants was also predictive of speech onset regardless of the speech task (Fig. 2 ). No significant differences were found between voiced and whispered speech at the group level (FDR q > 0.05) at any point of the averaged time-course of the trials, although in a few time points uncorrected p < 0.05 was found (Fig. 2C , gray shading horizontal bar). Overall, breathing and articulatory patterns were very similar across the production tasks and items. Both at the individual participant level and at the group level, lung volume peak preceded articulation onset. Speech sound recordings obtained synchronously with physiological changes matched the measures of articulatory movements. Speech was successfully synchronized in all participants with our fMRI protocol, i.e., speech was produced within the desired silent periods (900 ms) between consecutive TRs. As expected, voiced speech was significantly louder than whispered speech (p = 8.58 × 10 –10 , Fig. 2A upper panel). The three production events composing a single trial were consistent in loudness, hence variation was small across voiced events (3-way anova, p = 0.99, Fig. 2A lower panel) and the whispered task (p = 0.97). In most participants, the formant F1 extracted from the vowel segments was higher for whispered compared to voiced speech (Fig. 1C ) but not for F2. Overall and importantly, we confirmed that the voiced and whispered speech tasks were well-matched for respiration and articulation (Fig. 2C ).

Behavioral results. ( A ) Upper: Loudness per task across all participants. Red is voiced and blue is whispered speech. Bottom: Loudness per item repetition (3 items are produced per trial) across all participants for the voiced speech task. ( B ) Respiratory impulse response function (resp-IRF) using the average BOLD fluctuation within all cortical voxels. ( C ) Group results of the respiratory and articulatory recordings, red is voiced and blue is whispered speech: upper: voiced and whispered respiratory fluctuations (standard errors from the mean is shaded); gray horizontal bars refer to t-test differences (p < 0.05); ‘in’ and ‘ex’ depict inhale and exhale periods, respectively; middle: voiced and whispered articulatory fluctuations; bottom: combined respiratory and articulatory fluctuations.
We computed an impulse response function (IRF) for the voiced and whispered tasks separately (Fig. 2B ). IRF was computed as the averaged fMRI response within all voxels of the cortical gray matter relatively to the onset of trials (hence respiration). It provides a proxy of the respiration impulse response function (resp-IRF) affecting the fMRI signal in the cortex. Due to our experimental design (in particular the stimuli repetition every 16 seconds), the resp-IRF is qualitatively different from the expected respiratory response function in the literature at rest conditions 19 , which commonly shows a long-lasting post-stimulus dip up to around 30 seconds after deep breathing. Here, our post-stimulus dip is interrupted by the onset of the following trial. Despite this qualitative and expected difference, the resp-IRF in this study is marked by an expected peak around 8 seconds after inhalation. Importantly, no differences in the shape of the resp-IRF were found between the voiced and whispered tasks, making our design proof to variation in brain oxygenation related with respiratory behavior.
Producing speech relied on the typical brain network for reading and speaking, regardless of task (speech > baseline, Fig. 3A ). This network was observed bilaterally, and included areas of the occipital cortex, the intra-parietal-sulcus (IPS), the auditory cortex and posterior medial temporal gyrus (MTG), the ventral motor cortex and ventral pre-motor cortex, the superior medial frontal cortex (including the supplementary motor area, SMA, and pre-SMA), the inferior frontal gyrus, a superior portion of the lateral motor-cortex (central-sulcus), the supramarginal gyrus, the anterior insula, the posterior cingulate, and also extended to areas of the cerebellum (including the lobule HVI, Crus I, lobule HVIIb and HVIIIa) and basal ganglia. It is important to note that occipital cortex effects were expected given that the cues for the utterances were visually presented (in orthographic form) (Fig. 3A ). These visually-based fMRI activations may be also present for the voiced vs. whispered speech contrast due to differences in the color of the stimuli and attention therein (Fig. 3B ). Other contrasts within the speech task conditions may also elicit occipital effects due to potential differences in brain orthographic representations, including the ventral occipitotemporal cortex.

Univariate fMRI results (uncorrected statistics). ( A ) Speech versus baseline. The central sulcus (CS), inferior parietal sulcus (IPS), supramarginal gyrus (SMG), Heschl’s gyrus (HG) and inferior frontal gyrus (IFG) are outlined to provide landmark references. Bottom: flat cerebellum map; black lines represent borders between cerebellar lobules. ( B ) Voiced versus whispered speech. Top arrows indicate the trunk motor area (TMA) and the bottom arrows indicate the dorsal laryngeal motor area (dLMA) found by this contrast. ( C ) Bilabial versus Alveolar conditions. Top arrows indicate the lip and the bottom arrows the tongue motor regions. Bottom cerebellum representation includes labels of the parcelated cerebellar lobules according to the SUIT atlas 42 .
In comparison to whispered speech, voiced speech yielded stronger univariate responses in the auditory regions, the dorsal central sulci (dorsal-M1), some portions of middle central sulci (mid-M1), and the lobule HVI of the cerebellum (Fig. 3B ). Conversely, whispered speech showed stronger fMRI responses within the posterior bank of the post-central gyrus (somatosensory cortex) bilaterally and distributed portions of the frontal lobes (Fig. 3B ). Compatible to our expectations, ventral M1 showed a somatotopic organization for lip and tongue items along the superior-inferior direction, respectively (Fig. 3C ). This organization was marked (p < 0.05) in 11 out of the 18 participants, as well as, at the group level. No significant differences were found between oral and nasal utterances in the univariate analysis.
Decoding was independently conducted per ROI to unravel fMRI representations of articulatory and phonatory processes during speech production (Fig. 4 ). This strategy revealed decoding classifications significantly above permutation chance level in multiple ROIs, cortically and sub-cortically, across the experimental contrasts. Specifically, in voiced versus whispered speech conditions, we found significantly higher classification (q < 0.05) on most of the cortical ROIs except the right pars opercularis (PrOr), and in subcortical ROIs, including the cerebellum bilaterally, left thalamus (Thl) and left putamen (Put). Classification of articulatory differences based on lip versus tongue gestures (‘bb’ + ‘mm’ versus ‘dd’ + ‘nn’) regardless of task was significant (q < 0.05) in the pre-central (prCG) and post-central gyri (ptCG), cerebellum bilaterally, right superior frontal (SF), right superior temporal (ST), and left hippocampus (Hip). Classification of oral versus nasal gestures in the voiced speech task revealed the exclusive involvement of the prCG bilaterally (q < 0.05), but of no other ROI. Nasality was investigated strictly in the voiced speech task due to possible uninterpretable differences of velum control during the whispered speech task 32 . Importantly, the left putamen showed significant (q < 0.05) classification of bilabial versus the schwa vowel in the voiced speech tasks. Maps of RFE voxel selection (Fig. 4 ) for all ROIs are depicted conjointly in the cortical surfaces. The sign of the RFE maps indicates preference towards the first class (positive values) versus second class (negative values). RFE maps correspond with the uncorrected univariate statistics depicted in Fig. 3 . Furthermore, additional classification contrasts targeted the schwa vowel conditions (see Fig. 5 for a complete set of classification contrasts).

Multivariate fMRI group results. ( A ) MVPA ROI + RFE results for the three main contrasts: voiced versus whispered speech; bilabial versus alveolar; oral versus nasal. Classification is depicted by red bars and permutation chance-level by green bars. Black-colored asterisks (*) represent two-sided paired t-test of classification results against permutation chance-level (p < 0.05); red-colored asterisks represent FDR corrected statistics (q < 0.05) for multiple ROI tests. ( B ) Classification importance of the voxels within each ROI (using the RFE algorithm) projected onto the cortical and cerebellar maps. Multiple ROIs are projected simultaneously onto the maps for simplicity; the boundaries of the ROIs are indicated as colored lines and labelled in the top-left map. The sign of the voxel’s importance (positive or negative) represent their preference towards the first condition (positive values, warm colors) or second condition (negative values, cold colors). Bottom: maps of voxel’s importance in the cerebellum.

Summary of MVPA ROI + RFE results. Matrix reporting the accuracy difference between classification and permutation chance-level. Asterisks (*) indicate significant FDR q < 0.05. ROI results are shown for the brainstem, left ROIs and right ROIs. ROI labels are: BS (brain stem); Cer (cerebellum); Thl (thalamus); Cau (caudate); Put (putamen); Pal (pallidum); Hip (hippocampus); PrOr (pars orbitalis); PrOp (pars opercularis); PrTr (pars triangularis); ptCG (post-central gyrus); prCG (pre-central gyrus); SMG (supramarginal gyrus); Ins (insula); ST (superior temporal); SF (superior frontal).
The searchlight analysis (Fig. 6 ), which is not restricted to pre-defined anatomical boundaries (i.e., anatomical ROIs), was used as a complementary method for cortical classification output. This additional classification strategy allows disentangling whether representational fMRI patterns are distributed within the cortical ROIs or instead focal, as investigated using the searchlight approach. The searchlight results were consistent with the ROI-based MVPA results, with the exception of the contrast for oral versus nasal gestures. Oral vs. nasal gestures were successfully discriminated with the ROI-based method but not with the searchlight-based method. All searchlight maps were corrected for multiple searchlight comparisons using FDR (q < 0.05). The effect of phonation (voiced versus whispered speech) across multiple speech items (i.e., schwa, bilabial and alveolar, see Fig. 6 ) validated the role of middle and dorsal M1 regions (see black arrows), in addition to the involvement of the temporal lobe (superior temporal gyrus, STG) during voiced speech.

Cortical searchlight results. ( A–C ) the main contrasts (voiced versus whispered, bilabial versus alveolar, oral versus nasal). ( D–F ) task-based contrasts (voiced versus whispered speech) done separately by stimuli type (schwa, bilabial and alveolar). Top arrows indicate the consistency of TMA location; Bottom arrows indicate the consistency of LMA location. Arrows are placed equally on every map. ( G–J ) contrasts of each place of articulatory condition (bilabial and alveolar) versus the schwa condition for each task separately (voiced and whispered speech).
Functional connectivity
Beta time-series correlations (Fig. 7 ) were performed to explore functional connectivity using M1 seed regions individually identified (i.e., lip and tongue somatotopy during our task). Overall, correlations were similar across the seed regions, despite the different speech conditions (i.e., different items and tasks). Beyond voxels contiguous to the seed regions, we found that the dorsal M1 region (suggested to be involved in respiration and therefore phonation) is significantly correlated with the ventral articulatory seed regions for all speech conditions (p < 0.005). Furthermore, the cerebellum also showed correlations with the seed regions, albeit less pronounced (p < 0.05), especially in regions within the lobule HVI, bilaterally. Together, dorsal M1 and the cerebellum were the only brain regions non-contiguous to the seed regions that showed consistent clustered correlations. Because correlations were also performed within each speech task and articulatory gesture type, separately, they are immune to fMRI signal modulations across these conditions. Finally, we did not find articulatory-specific nor phonatory-specific connectivity. We tested whether a preference of task (voiced or whispered speech) or place of articulation (bilabial and alveolar) existed in the connectivity maps for the lip and tongue regions separately. None was found. Furthermore, we tested whether a preference of left versus right seed regions existed in connectivity maps, but this was not the case (all subjects were right-handed).

Functional connectivity results using beta-time-series correlations based on individually localized lip and tongue motor regions. Circles indicate an approximate localization of the seed region in the group-inflated surface (seed regions were identified at the individual subject level using a p < 0.05 threshold). Black arrows highlight the location of the trunk motor area (TMA). ( A ) Seed is the left lip motor region. ( B ) Seed is the left tongue motor region.
Speech production involves the concerted control of multiple neuromotor systems, including articulation, phonation and respiration (Fig. 8 ). The current study contributes to the existing literature by capitalizing on MVPA methods with high-spatial resolution fMRI, providing a non-invasive tool, sensitive enough to uncover articulatory-specific representations within and beyond M1. These findings are promising for investigating the speech production circuitry in humans and in-vivo , and to investigate the dysfunctions that can be potentially present in neuromotor speech disorders.

Summary diagram of the cooperation required for voiced speech and possible experimental conditions used to isolate the sub-components of speech production (Respiration, Phonation and Articulation).
Although primary motor regions (M1) hold somatotopically-organized neural connections to the human musculature, including those required for speaking, a number of other cortical and subcortical regions are also suggested to be of critical importance 26 , 29 , 44 . Mapping articulatory speech gestures, involving the lips, tongue and velum, only solves one piece of the complex articulatory control puzzle. Another important piece of the puzzle is how these gestures occur in concert with phonation, and consequently respiration. The orchestration of these three systems is unique and central to verbal communication in humans and must be studied in such a way that preserves important ecological features of intelligible speech, including the sustained and partial adduction of the glottis, and the synchronization of phonation, respiration and articulation. To this end, the current fMRI study investigated the representations involved in the production of lip, tongue and velum gestures, as well as the larynx (phonation). In addition to univariate analyses, MVPA decoding strategies 22 , 23 , 24 , 25 were employed. These methods proved essential in revealing the subtle articulatory-specific fMRI response patterns in a group of fluent adults, namely in subcortical regions, and between oral and nasal items. In addition, this study took advantage of simultaneous multi-slice acquisition in order to sample the signal every 2 seconds, including a necessary 900 ms gap for speaking in absence of MR acquisition that has been shown to mitigate the confounding effects of head motion 18 . Nevertheless, despite the silent acquisition paradigm, occasionally participants’ productions overlapped with the scanner noise of the subsequent TR. This unexpected occasional overlap can affect the online monitoring of re-afferent speech 45 , concerning the vowel segment but not the consonant segment, which is most critical in our analyses of articulatory (place of articulation of the consonants) and phonatory mechanisms of speech production.
The results implicate several brain regions in the neuromotor control of articulation (i.e., bilabial versus alveolar and oral versus nasal) and phonation (i.e., voiced versus whispered speech). Specifically, we observed distinct superior and middle subregions of M1 that showed significantly greater fMRI responses for voiced compared to whispered speech. The finding in the mid M1 region is consistent with prior work showing its involvement in controlling intrinsic laryngeal muscles during glottal stops, in humans (a.k.a., dLMA) 7 , 8 , 46 . For the superior M1 region, which is thought to be responsible for the voluntary control of breathing (a.k.a., trunk motor area, TMA) 4 , 8 , 10 , 14 , our results suggest that beyond managing air-flow, it is particularly involved in phonation. Although the use of whispered speech have previously been studied using positron emission tomography (PET) 47 and lower spatial resolution fMRI 14 , the high spatial resolution fMRI, in combination with sparse-sampling, well-matched respiratory conditions and MVPA employed here allowed us to further specify differences between these conditions. Beyond cerebral cortex, we identified phonatory and articulatory representations in superior portions of the cerebellum (lobule HVI), whose predicted involvement in the timely management of motor execution and integration of online somatosensory and auditory feedback 48 make it a key contributor to the production of speech 39 , 49 .
Despite the advantage of using whispered speech as a baseline condition for isolating phonation, while controlling for respiratory behavior, it may involve compensatory gestures needed for producing intelligible whispered speech. In fact, the sound effect present in whispering results from supra-glottal laryngeal muscles (i.e., tyropharyngeus) that constrain the passage of air downstream from the glottis 32 . To minimize potential effects related to compensatory supra-glottal muscles in our study, we trained participants to produce ‘soft’ whispered speech, which has been shown to significantly eliminate electrophysiological activations in these muscles 32 . Furthermore, both voiced and whispered speech depend on expiratory air-pressure. Importantly, our chest volume recordings did not show differences between voiced and whispered speech, suggesting that our voicing contrast was not confounded by respiration 20 , 47 .
Ventral M1, the cortical primary motor area for the control of articulated speech, has received increased attention in the past decades by fMRI 9 , 12 and intracranical EEG 5 , 50 , 51 research. Within ventral M1, we found dissociation for place of articulation (lip versus tongue) and nasality (nasals versus orals), confirming distinct somatotopic evidence 4 , 5 , 7 , 10 . Beyond M1, representation of place of articulation was found in multivoxel patterns of the left and right cerebellum and the right superior temporal lobe (Fig. 4 ). We also found articulatory representations in the left putamen in the basal ganglia, although these were restricted to the comparison of bilabial gestures versus the ‘schwa’ vowel (Fig. 5 ). Cortico-striatum-cortical loops are critical for neuromotor control. However, detailed representations and connections in the basal ganglia during speech tasks remain unclear. It is unknown whether communication between M1 and the basal ganglia depend on parallel connections (i.e., somatotopically preserved connections), or whether neural convergence occurs in the circuit. Recent animal electrophysiology 26 suggests that a certain level of convergence takes place in the cortico-striatum-cortical loop, which explains lack of articulatory-specific representations found at the basal ganglia in this study. Alternatively, identifying articulatory-specific representations in specific basal ganglia nuclei may require higher spatial resolution. Here, 2 mm isotropic voxels in 3-tesla MRI were used. In the future, imaging the basal ganglia at higher magnetic field strengths (e.g., 7-tesla MRI) may render the necessary resolution to study speech representations within these brain structures typically suffering from reduced fMRI signal 52 .
With respect to the findings in the cerebellum, several recent neuro-anatomical accounts of speech production incorporate cortico-cerebellar-cortical interactions for the coordination of time-dependent motor planning, monitoring and execution 48 , 53 , 54 . Indeed, we found both articulatory and phonatory representations in the cerebellum, in particular within lobule HVI, bilaterally. Importantly, the identified cerebellar regions were functionally connected to ventral M1 (Fig. 7 ). Previous research has shown somatotopic representations of tongue movements in Lobule HVI in the absence of speech 38 , 55 . Here, we were able to specify the spatial location of lip and tongue representations, as well as a separate locus for the control of the larynx, in lobule HVI; laryngeal representations were more medial compared to lips and tongue (Fig. 4B ).
To our knowledge, no fMRI studies have examined the representation of velum control. Velum control includes the action of several/distributed muscles 56 , which limits its topographical localization. The results of the current study show that the classification of oral versus nasal sounds (i.e., velum control) using MVPA was significant within the pre-central gyri, bilaterally (Figs. 4 and 5 ). Interestingly, focal brain regions representing velum control were not found in our searchlight analysis. Taken together, our results suggest a more distributed representation of the velum control across M1. In future, a more deterministic understanding of the somatotopy of the velum may require investigating velar movements separately, for example by using continuous oral to nasal (and nasal to oral) vowel transitions, or by simultaneously obtaining the velum’s position using real-time MRI 57 , 58 or non-invasive electromyogram recordings 56 .
We also probed the potential specificity of functional connections for lip vs. tongue articulatory and voiced vs. whispered speech to better characterize the coordination of the neural circuitry involved in speech. Somatotopically-based connections have been unveiled for left- and right-hand movements between M1 and the cerebellum in human fMRI 55 and to some extent between M1 and the basal ganglia in animal electrophysiology 26 . Notwithstanding, it remains unclear whether the specificity of connections are preserved across brain regions involved in their motor control (i.e., parallel connections) or instead show convergence 26 . In this study, articulatory-specific or phonatory-specific functional connections were not found, supporting convergence of functional connectivity for the speech gestures here studied and during online speech production. It is however possible that faster fMRI acquisition rates (e.g., below 1 second) in combination with functional connectivity methods that rely on fMRI time-series (e.g., psychophysiological interactions or dynamic causal modelling) would allow us to unravel specificity of neural connections during speech production.
In conclusion, we investigated the brain’s representation for speech production using whole-brain fMRI coverage. We applied univariate and multivariate decoding analyses to define articulatory representations involving the lips, tongue and velum, as well as representations of phonation using voiced and whispered speech. Our results confirmed the role of a region within the mid portion of the central sulcus (dLMA) for voiced speech 12 , 14 , 46 . Importantly, we found that voiced speech additionally recruits a superior motor area, previously implicated in controlling trunk respiratory muscles 4 . Since our task had matched respiratory behavior, this trunk motor region does not seem to reflect differences in respiratory control, but instead to subserve the coordination between articulation, respiration and phonation. This interpretation is further supported by the fact that this region was functionally connected to tongue and lip M1 subregions. Our results also indicate that the cerebellum spatially dissociates articulatory and phonatory gestures, supporting an extensive literature on the role of the cerebellum, both as a motor mediator and a processing unit for sensory feedback 48 . Moreover, multivariate decoding showed evidence for the active role of the putamen in phonation and articulation. It is assumed that somatotopically-preserved connections are part of cortico-striatum-cortical loops 26 , and debate remains on whether these circuits are recruited in the linguistically-matured brain, or specific to the development of the motor skills involved in speaking 59 . Taken together, the results of the current study suggest that MVPA provide an effective method for investigating speech representations during naturalistic conditions using non-invasive brain imaging technology. Thus, they can be used to better understand the neurobiology of speech production both in fluent and disordered populations, conduct longitudinal studies reflecting speech development, as well as assess the benefits of clinical interventions.
Story, B. H. An overview of the physiology, physics and modeling of the sound source for vowels. Acoust. Sci. Technol. 23 , 195–206 (2002).
Article Google Scholar
Rathelot, J.-A. & Strick, P. L. Subdivisions of primary motor cortex based on cortico-motoneuronal cells. Proc. Natl. Acad. Sci. 106 , 918–923 (2009).
Article ADS CAS PubMed PubMed Central Google Scholar
Tremblay, P., Deschamps, I. & Gracco, V. L. Neurobiology of Speech Production. in Neurobiology of Language (eds. Hickok, G. & Small, S. L.) 741–750, https://doi.org/10.1016/B978-0-12-407794-2.00059-6 (Academic Press, 2016).
Chapter Google Scholar
Foerster, O. The cerebral cortex in man. Lancet August, 309–312 (1931).
Bouchard, K. E., Mesgarani, N., Johnson, K. & Chang, E. F. Functional organization of human sensorimotor cortex for speech articulation. Nature 495 , 327–332 (2013).
Mugler, E. M. et al . Direct classification of all American English phonemes using signals from functional speech motor cortex. J. Neural Eng. 11 , 035015 (2014).
Article ADS PubMed PubMed Central Google Scholar
Brown, S. et al . The somatotopy of speech: Phonation and articulation in the human motor cortex. Brain Cogn. 70 , 31–41 (2009).
Article PubMed PubMed Central Google Scholar
Simonyan, K. The laryngeal motor cortex: Its organization and connectivity. Curr. Opin. Neurobiol. 28 , 15–21 (2014).
Article CAS PubMed Google Scholar
Carey, D., Krishnan, S., Callaghan, M. F., Sereno, M. I. & Dick, F. Functional and Quantitative MRI Mapping of Somatomotor Representations of Human Supralaryngeal Vocal Tract. Cereb. Cortex 27 , 265–278 (2017).
Catani, M. A little man of some importance. Brain 140 , 3055–3061 (2017).
Rampinini, A. C. et al . Functional and spatial segregation within the inferior frontal and superior temporal cortices during listening, articulation imagery, and production of vowels. Sci. Rep . 7, 1–13 (2017).
Brown, S., Ngan, E. & Liotti, M. A larynx area in the human motor cortex. Cereb. Cortex 18 , 837–845 (2008).
Article PubMed Google Scholar
Shuster, L. I. & Lemieux, S. K. An fMRI investigation of covertly and overtly produced mono- and multisyllabic words. Brain Lang. 93 , 20–31 (2005).
Loucks, T. M. J., Poletto, C. J., Simonyan, K., Reynolds, C. L. & Ludlow, C. L. Human brain activation during phonation and exhalation: Common volitional control for two upper airway functions. Neuroimage 36 , 131–143 (2007).
Moeller, S. et al . Multiband multislice GE-EPI at 7 tesla, with 16-fold acceleration using partial parallel imaging with application to high spatial and temporal whole-brain fMRI. Magn. Reson. Med. 63 , 1144–53 (2010).
Feinberg, D. A. et al . Multiplexed echo planar imaging for sub-second whole brain fmri and fast diffusion imaging. PLoS One 5 (2010).
Caballero-Gaudes, C. & Reynolds, R. C. Methods for cleaning the BOLD fMRI signal. Neuroimage 154 , 128–149 (2017).
Gracco, V. L., Tremblay, P. & Pike, B. Imaging speech production using fMRI. Neuroimage 26 , 294–301 (2005).
Chang, C. & Glover, G. H. Relationship between respiration, end-tidal CO2, and BOLD signals in resting-state fMRI. Neuroimage 47 , 1381–1393 (2009).
Power, J. D. A simple but useful way to assess fMRI scan qualities. Neuroimage 154 , 150–158 (2017).
Wise, R. G., Ide, K., Poulin, M. J. & Tracey, I. Resting fluctuations in arterial carbon dioxide induce significant low frequency variations in BOLD signal. Neuroimage 21 , 1652–1664 (2004).
De Martino, F. et al . Combining multivariate voxel selection and support vector machines for mapping and classification of fMRI spatial patterns. Neuroimage 43 , 44–58 (2008).
Formisano, E., De Martino, F., Bonte, M. & Goebel, R. ‘Who’ is saying ‘what’? Brain-based decoding of human voice and speech. Science (80-.). 322 , 970–973 (2008).
Article ADS CAS Google Scholar
Bonte, M., Correia, J. M., Keetels, M., Vroomen, J. & Formisano, E. Reading-induced shifts of perceptual speech representations in auditory cortex. Sci. Rep. 7 , 1–11 (2017).
Article CAS Google Scholar
Kriegeskorte, N., Goebel, R. & Bandettini, P. Information-based functional brain mapping. Proc. Natl. Acad. Sci. 103 , 3863–3868 (2006).
Nambu, A. Somatotopic organization of the primate basal ganglia. Front. Neuroanat. 5 , 1–9 (2011).
Zeharia, N., Hertz, U., Flash, T. & Amedi, A. Negative blood oxygenation level dependent homunculus and somatotopic information in primary motor cortex and supplementary motor area. Proc. Natl. Acad. Sci. 109 , 18565–18570 (2012).
Zeharia, N., Hertz, U., Flash, T. & Amedi, A. New Whole-Body Sensory-Motor Gradients Revealed Using Phase-Locked Analysis and Verified Using Multivoxel Pattern Analysis and Functional Connectivity. J. Neurosci. 35 , 2845–2859 (2015).
Article CAS PubMed PubMed Central Google Scholar
Hickok, G., Houde, J. & Rong, F. Sensorimotor Integration in Speech Processing: Computational Basis and Neural Organization. Neuron 69 , 407–422 (2011).
Yairi, E. & Ambrose, N. Epidemiology of stuttering: 21st century advances. J. Fluency Disord. 38 , 66–87 (2013).
Corey, D. M. & Cuddapah, V. A. Delayed auditory feedback effects during reading and conversation tasks: Gender differences in fluent adults. J. Fluency Disord. 33 , 291–305 (2008).
Tsunoda, K., Niimi, S. & Hirose, H. The Roles of the Posterior Cricoarytenoid and Thyropharyngeus Muscles in Whispered Speech. Folia Phoniatr. Logop. 46 , 139–151 (1994).
Therrien, A. S., Lyons, J. & Balasubramaniam, R. Sensory Attenuation of Self-Produced Feedback: The Lombard Effect Revisited. PLoS One 7, (2012).
Liu, T. T. Efficiency, power, and entropy in event-related fMRI with multiple trial types. Part II: Design of experiments. Neuroimage 21 , 401–413 (2004).
Liu, T. T. & Frank, L. R. Efficiency, power, and entropy in event-related fMRI with multiple trial types. Part I: Theory. Neuroimage 21 , 387–400 (2004).
Cox, R. W. AFNI: software for analysis and visualization of functional magnetic resonance neuroimages. Comput. Biomed. Res. 29 , 162–73 (1996).
Article ADS CAS PubMed Google Scholar
Andersson, J. L. R., Skare, S. & Ashburner, J. How to correct susceptibility distortions in spin-echo echo-planar images: Application to diffusion tensor imaging. Neuroimage 20 , 870–888 (2003).
Diedrichsen, J. & Zotow, E. Surface-based display of volume-averaged cerebellar imaging data. PLoS One 10 , 1–18 (2015).
Ackermann, H., Hage, S. R. & Ziegler, W. Brain mechanisms of acoustic communication in humans and nonhuman primates: An evolutionary perspective. Behav. Brain Sci. 37 , 529–546 (2014).
Cox, D. D. & Savoy, R. L. Functional magnetic resonance imaging (fMRI) ‘brain reading’: Detecting and classifying distributed patterns of fMRI activity in human visual cortex. Neuroimage 19 , 261–270 (2003).
Ontivero-Ortega, M., Lage-Castellanos, A., Valente, G., Goebel, R. & Valdes-Sosa, M. Fast Gaussian Naïve Bayes for searchlight classification analysis. Neuroimage 163 , 471–479 (2017).
Chen, Y. et al . Cortical surface-based searchlight decoding. Neuroimage 56 , 582–592 (2011).
Rissman, J., Gazzaley, A. & D’Esposito, M. Measuring functional connectivity during distinct stages of a cognitive task. Neuroimage 23 , 752–763 (2004).
Ackermann, H., Wildgruber, D., Daum, I. & Grodd, W. Does the cerebellum contribute to cognitive aspects of speech production? A functional magnetic resonance imaging (fMRI) study in humans. Neurosci. Lett. 247 , 187–190 (1998).
Niziolek, C. A., Nagarajan, S. S. & Houde, J. F. What does motor efference copy represent? evidence from speech production. J. Neurosci. 33 , 16110–16116 (2013).
Belyk, M. & Brown, S. The origins of the vocal brain in humans. Neurosci. Biobehav. Rev. 77 , 177–193 (2017).
Schulz, G. M., Varga, M., Jeffires, K., Ludlow, C. L. & Braun, A. R. Functional neuroanatomy of human vocalization: An H215O PET study. Cereb. Cortex 15 , 1835–1847 (2005).
Hickok, G. Computational neuroanatomy of speech production. Nat. Rev. Neurosci. 13 , 135–145 (2012).
Ackermann, H., Mathiak, K. & Riecker, A. The contribution of the cerebellum to speech production and speech perception: Clinical and functional imaging data. Cerebellum 6 , 202–213 (2007).
Chartier, J., Anumanchipalli, G. K., Johnson, K. & Chang, E. F. Encoding of Articulatory Kinematic Trajectories in Human Speech Sensorimotor Cortex. Neuron 98 , 1042–1054.e4 (2018).
Mugler, E. M. et al . Differential Representation of Articulatory Gestures and Phonemes in Precentral and Inferior Frontal Gyri. J. Neurosci . 1206–18, https://doi.org/10.1523/JNEUROSCI.1206-18.2018 (2018).
Lenglet, C. et al . Comprehensive in vivo mapping of the human basal ganglia and thalamic connectome in individuals using 7T MRI. PLoS One 7, (2012).
Guenther, F. H., Ghosh, S. S. & Tourville, J. A. Neural modeling and imaging of the cortical interactions underlying syllable production. Brain Lang. 96 , 280–301 (2006).
Schwartze, M. & Kotz, S. A. Contributions of cerebellar event-based temporal processing and preparatory function to speech perception. Brain Lang. 161 , 28–32 (2016).
Buckner, R. L., Krienen, F. M., Castellanos, A., Diaz, J. C. & Yeo, B. T. T. The organization of the human cerebellum estimated by intrinsic functional connectivity. J. Neurophysiol. 106 , 2322–2345 (2011).
Freitas, J., Teixeira, A., Silva, S., Oliveira, C. & Dias, M. S. Detecting nasal vowels in speech interfaces based on surface electromyography. PLoS One 10 , 1–26 (2015).
Google Scholar
Lingala, S. G., Sutton, B. P., Miquel, M. E. & Nayak, K. S. Recommendations for real-time speech MRI. J. Magn. Reson. Imaging 43 , 28–44 (2016).
Paine, T. L., Conway, C. A., Malandraki, G. A. & Sutton, B. P. Simultaneous dynamic and functional MRI scanning (SimulScan) of natural swallows. Magn. Reson. Med. 65 , 1247–1252 (2011).
Doya, K. Complementary roles of basal ganglia and cerebellum in learning and motor control. Curr. Opin. Neurobiol. 10 , 732–739 (2000).
Download references
Acknowledgements
This work was supported by the Spanish Ministry of Economy and Competitiveness through the Juan de la Cierva Fellowship (FJCI-2015-26814), and the Ramon y Cajal Fellowship (RYC-2017- 21845), the Spanish State Research Agency through the BCBL “Severo Ochoa” excellence accreditation (SEV-2015-490), the Basque Government (BERC 2018- 2021) and the European Union’s Horizon 2020 research and innovation program under the Marie Sklodowska-Curie grant (No 799554). We are grateful for the provision of simultaneous multi-slice (multiband) pulse sequence and reconstruction algorithms from the Center for Magnetic, Resonance Research (CMRR), University of Minnesota.
Author information
Authors and affiliations.
BCBL, Basque Center on Cognition Brain and Language, San Sebastian, Spain
Joao M. Correia, César Caballero-Gaudes, Sara Guediche & Manuel Carreiras
Centre for Biomedical Research (CBMR)/Department of Psychology, University of Algarve, Faro, Portugal
Joao M. Correia
Ikerbasque. Basque Foundation for Science, Bilbao, Spain
Manuel Carreiras
University of the Basque Country. UPV/EHU, Bilbao, Spain
You can also search for this author in PubMed Google Scholar
Contributions
J.M.C., C.C.G. and M.C. planed and designed the experiment. J.M.C. executed the study, analyzed the data and wrote the manuscript. C.C.G. provided methodological input. S.G. helped with interpretation of results. All authors contributed to writing and revising the manuscript.
Corresponding author
Correspondence to Joao M. Correia .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Correia, J.M., Caballero-Gaudes, C., Guediche, S. et al. Phonatory and articulatory representations of speech production in cortical and subcortical fMRI responses. Sci Rep 10 , 4529 (2020). https://doi.org/10.1038/s41598-020-61435-y
Download citation
Received : 01 March 2019
Accepted : 24 February 2020
Published : 11 March 2020
DOI : https://doi.org/10.1038/s41598-020-61435-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Decoding single and paired phonemes using 7t functional mri.
- Maria Araújo Vitória
- Francisco Guerreiro Fernandes
- Mathijs Raemaekers
Brain Topography (2024)
A somato-cognitive action network alternates with effector regions in motor cortex
- Evan M. Gordon
- Roselyne J. Chauvin
- Nico U. F. Dosenbach
Nature (2023)
The importance of deep speech phenotyping for neurodevelopmental and genetic disorders: a conceptual review
- Karen V. Chenausky
- Helen Tager-Flusberg
Journal of Neurodevelopmental Disorders (2022)
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
2.2 The Articulatory System
We speak by moving parts of our vocal tract (See Figure 2.1). These include the lips, teeth, mouth, tongue and larynx. The larynx or voice box is the basis for all the sounds we produce. It modified the airflow to produce different frequencies of sound. By changing the shape of the vocal tract and airflow, we are able to produce all the phonemes of spoken language. There are two basic categories of sound that can be classified in terms of the way in which the flow of air through the vocal tract is modified. Phonemes that are produced without any obstruction to the flow of air are called vowels . Phonemes that are produced with some kind of modification to the airflow are called consonants . Of course, nature is not as clear-cut as all that and we do make some sounds that are somewhere in between these two categories. These are called semivowels and are usually classified alongside consonants as they behave similar to them.

While vowels do not require any modifications to the airflow, the production of consonants requires it. This obstruction is produced by bringing some parts of the vocal tract into contact. These places of contact are known as places of articulation . As seen in Figure 2.2, there are a number of places of articulation for the lips, teeth, and tongue. Sometimes the articulators touch each other as in the case of the two lips coming together to produce [b]. At other times, two articulators come into contact as when the lower lip folds back into the upper teeth to produce [f]. The tongue can touch different parts of the vocal tract to produce a variety of consonants by touching the teeth, the alveolar ridge, hard palate or soft palate (or velum).

While these places of articulation are sufficient for describing how English phonemes are produced, other languages also make use of the glottis and epiglottis among other parts of the vocal tract. We will explore these in more detail later.
The Vocal Tract
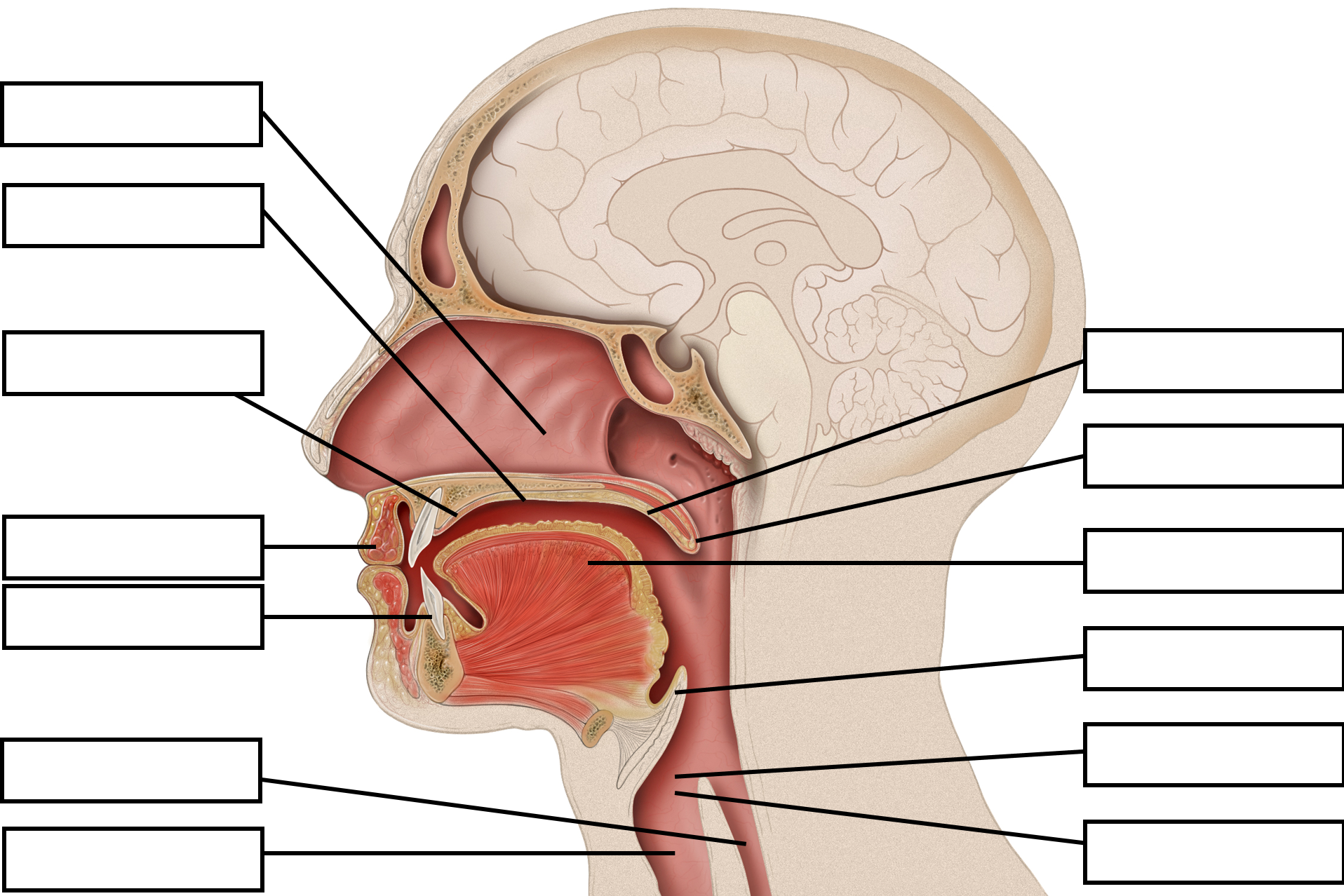
Fill in the blanks with parts of vocal tract:
- Hard palate
- Soft palate
- Nasal cavity
- Alveolar ridge
- Vocal cords
To check your answers, navigate to the above link to view the interactive version of this activity.
Places of Articulation
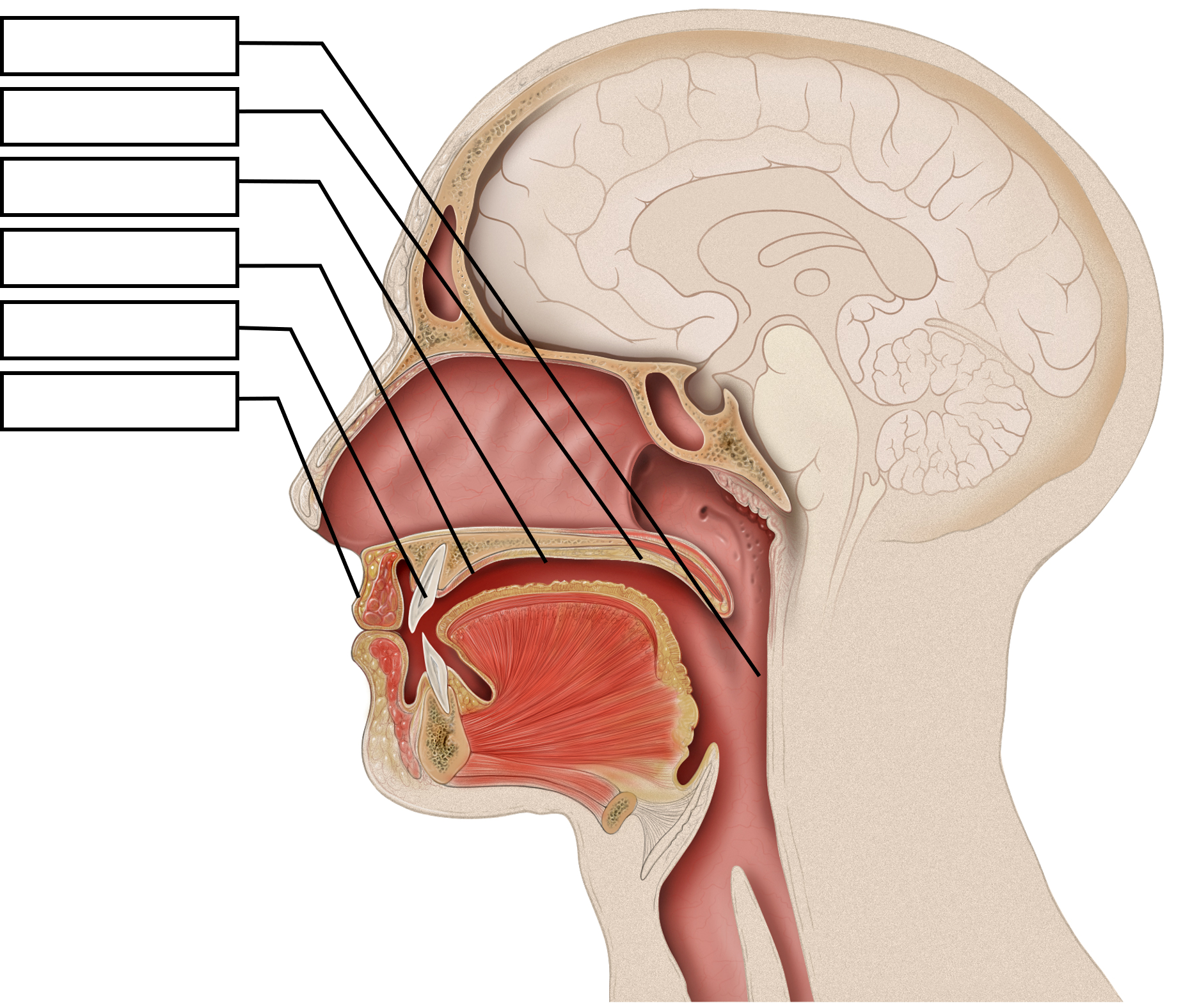
Image description
Figure 2.1 Parts of the Human Vocal Tract
A labeled image of the anatomical components of the human vocal tract, including the nasal cavity, hard palate, soft palate or velum, alveolar ridge, lips, teeth, tongue, uvula, esophagus, trachea, and the parts of the larynx, which include the epiglottis, vocal cords, and glottis.
[Return to place in the text (Figure 2.1)]
Figure 2.2 Places of Articulation
A labeled image illustrating the anatomical components of the human vocal tract that are involved in English phonemes. These include the glottal, velar, palatal, dental, and labial structures.
[Return to place in the text (Figure 2.2)]
Media Attributions
- Figure 2.1 Parts of the Human Vocal Tract is an edited version of Mouth Anatomy by Patrick J. Lynch, medical illustrator, is licensed under a CC BY 2.5 licence .
- Figure 2.2 Places of Articulation is an edited version of Mouth Anatomy by Patrick J. Lynch, medical illustrator, is licensed under a CC BY 2.5 licence .
A speech sound that is produced without complete or partial closure of the vocal tract.
A speech sound that is produced with complete or partial closure of the vocal tract.
A consonant that is phonetically similar to a vowel but functions as a consonant. Also known as a glide.
The point of contact between the articulators.
Psychology of Language Copyright © 2021 by Dinesh Ramoo is licensed under a Creative Commons Attribution 4.0 International License , except where otherwise noted.
Share This Book
Understanding How Voice is Produced | Learning About the Voice Mechanism | How Breakdowns Result in Voice Disorders
Learning About the Voice Mechanism
Speaking and singing involve a voice mechanism that is composed of three subsystems. Each subsystem is composed of different parts of the body and has specific roles in voice production.
Three Voice Subsystems
| Subsystem | Voice Organs | Role in Sound Production |
|---|---|---|
| Air pressure system | Diaphragm, chest muscles, ribs, abdominal musclesLungs | Provides and regulates air pressure to cause vocal folds to vibrate |
| Vibratory system | Voice box (larynx)Vocal folds | Vocal folds vibrate, changing air pressure to sound waves producing “voiced sound,” frequently described as a “buzzy sound”Varies pitch of sound |
| Resonating system | Vocal tract: throat (pharynx), oral cavity, nasal cavities | Changes the “buzzy sound” into a person’s recognizable voice |
| ) |
Air Pressure System
The ability to produce voice starts with airflow from the lungs, which is coordinated by the action of the diaphragm and abdominal and chest muscles.
Vibratory System
- The voice box (larynx) and vocal folds (sometimes called vocal cords) comprise the vibratory system of the voice mechanism.
- Resonating System
- The vocal tract is comprised of resonators which give a personal quality to the voice, and the modifiers or articulators which form sound into voiced sounds.
Key Function of the Voice Box
The key function of the voice box is to open and close the glottis (the space between the two vocal folds).
- Voice box brings both vocal folds apart during breathing.
- Voice box closes the glottis to build up pressure, then opens it for the forceful expelling of air during cough.
- Voice box coordinates closing the glottis by bringing both vocal folds to the midline to prevent choking during swallowing.
- Voice box brings both vocal folds to the midline to allow vocal fold vibration during speaking and singing.
- Voice box adjusts vocal fold tension to vary pitch (how high or low the voice is) and changes in volume (such as loud voice production).
Key Components of the Voice Box
Vocal Folds
Voice Box Cartilages
There are three cartilages within the larynx.
- Thyroid Cartilage
- Forms the front portion of the larynx
- Most forward part comprises the “Adam’s apple”
- Houses the vocal folds
- Vocal folds attach just below the Adam’s apple
- Cricoid Cartilage
- Below the thyroid cartilage
- Ring-like: front to back
- Becomes taller in the back of the voice box
- Platform for the arytenoid cartilages
- Arytenoid Cartilages (left and right)
- Pair of small pyramid-shaped cartilages
- Connect with the cricoid cartilage at the back of the vocal folds
- With the cricoid cartilage, forms the cricoarytenoid joint
Voice Box Muscles
Voice box muscles are named according to the cartilages to which they are attached.
Voice Box Muscles – Cartilage Attachments, Role, Nerve Input
| Muscles, Cartilage Attachments, and their Main Roles | Nerve Input |
|---|---|
| These muscles work coordinately to position both vocal folds in the midline for vocal fold vibration during sound production. | Recurrent laryngeal nerve (RLN) |
| Recurrent laryngeal nerve (RLN) | |
| Vocalis muscle (derived from inner and deeper fibers of thyroarytenoid msucle] | Recurrent laryngeal nerve (RLN) |
| Cricothyroid muscle | Superior laryngeal nerve (SLN) |

Nerve Input to the Voice Box
The brain coordinates voice production through specific nerve connections and signals
Signals to the voice box for moving voice box muscles (motor nerves) come from:
- Signals from the voice box structures for feeling (sensory nerves) travel through sensory branches of the RLN and SLN
- Motor branches of recurrent laryngeal nerve (RLN)
- Superior laryngeal nerve (SLN)
“Recurrent” laryngeal nerve: The recurrent laryngeal nerve is so named because on the left side of the body it travels down into the chest and comes back (recurs) up into the neck to end at the larynx. [see figure below] Long path of left RLN: The circuitous path of the left RLN throughout the chest is one reason why any type of open-chest surgery places patients at risk for a recurrent laryngeal nerve injury, which would result in vocal fold paresis or paralysis. [see figure below] (For more information, see Vocal Fold Scarring and Vocal Fold Paresis / Paralysis .) Shorter path of right RLN: The right recurrent laryngeal nerve continues in the upper chest and loops around the right subclavian artery, just behind the clavicle (collarbone), then travels the short distance in the neck to the larynx.
Diagram of Key Nerves for Voice Production
| This diagram shows the “long path” of the left recurrent laryngeal nerve (left RLN). After it branches off the vagus nerve, the left RLN loops around the aortic arch in the chest cavity and then courses back into the neck.This long course makes it at higher risk for injury compared with the shorter course of the right RLN which does not run through the chest cavity. |
The left and right vocal folds are housed within the larynx. The vocal folds include three distinct layers that work together to promote vocal fold vibration.
- Basement membrane
- Superficial lamina propria (SLP)
- Intermediate lamina propria
- Deep lamina propria (contains collagen fibers that are stronger and more rigid than the superficial lamina propria)

“Wiper-Like” Movement of Vocal Folds
The vocal folds move similar to a car’s windshield wipers that are attached to the middle of the windshield and open outwards. (See figure below.)
- The front ends of both vocal folds are anchored to the front-middle ( anterior commissure ).
- The back ends of both vocal folds are anchored to the arytenoid cartilages .
- When arytenoids are moved to the open position by the posterior cricoarytenoid muscle, vocal folds open, resulting in glottal opening.
- When arytenoids are closed by the lateral cricoarytenoid and inter arytenoid muscles, vocal folds are brought to the midline resulting in glottal closure.
Vocal Folds (vf) Opening and Closing

( click for larger image )
| Patient education material presented here does not substitute for medical consultation or examination, nor is this material intended to provide advice on the medical treatment appropriate to any specific circumstances. All use of this site indicates acceptance of our  An official website of the United States government The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site. The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
The PMC website is updating on October 15, 2024. Learn More or Try it out now .
The brain’s conversation with itself: neural substrates of dialogic inner speechBen alderson-day. 1 Department of Psychology, Durham University, Durham, UK, Susanne WeisSimon mccarthy-jones. 2 Department of Cognitive Science, Macquarie University, Australia, 3 Department of Psychiatry, Trinity College Dublin, Ireland, and Peter Moseley4 School of Psychology, University of Central Lancashire, Preston, UK. David SmailesCharles fernyhough, associated data. Inner speech has been implicated in important aspects of normal and atypical cognition, including the development of auditory hallucinations. Studies to date have focused on covert speech elicited by simple word or sentence repetition, while ignoring richer and arguably more psychologically significant varieties of inner speech. This study compared neural activation for inner speech involving conversations (‘dialogic inner speech’) with single-speaker scenarios (‘monologic inner speech’). Inner speech-related activation differences were then compared with activations relating to Theory-of-Mind (ToM) reasoning and visual perspective-taking in a conjunction design. Generation of dialogic (compared with monologic) scenarios was associated with a widespread bilateral network including left and right superior temporal gyri, precuneus, posterior cingulate and left inferior and medial frontal gyri. Activation associated with dialogic scenarios and ToM reasoning overlapped in areas of right posterior temporal cortex previously linked to mental state representation. Implications for understanding verbal cognition in typical and atypical populations are discussed. IntroductionInner speech—the experience of silent, verbal thinking—has been implicated in many cognitive functions, including problem-solving, creativity and self-regulation ( Morin, 2009 ; Fernyhough, 2013 ; Alderson-Day and Fernyhough, 2015a ), and disruptions to the ‘internal monologue’ have been linked to varieties of pathology, including hallucinations and depression ( Frith, 1992 ; Nolen-Hoeksema, 2004 ). Enhanced understanding of inner speech hence has implications for understanding of both typical and atypical cognition. Although interest in inner speech has grown in recent years ( Morin et al ., 2011 ; Williams et al ., 2012 ; Fernyhough, 2013 ), conceptual and methodological challenges have limited what is known about the neural processes underpinning this common experience. Most neuroimaging studies to date have operationalized inner speech as a unitary phenomenon equivalent to a first-person monologue ( Hinke et al ., 1993 ; Simons et al ., 2010 ). Methods of eliciting inner speech have typically involved either subvocal recitation (e.g. covertly repeating ‘You are a x ’ in response to a cue; McGuire et al ., 1995 ) or prompting participants to make phonological judgements about words using inner speech (such as which syllable to stress in pronunciation; Aleman et al ., 2005 ). Such studies have shown recruitment during inner speech of areas associated with overt speech production and comprehension, such as left inferior frontal gyrus (IFG), supplementary motor area (SMA) and the superior and middle temporal gyri ( McGuire et al ., 1996 ; Shergill et al ., 2002 ; Aleman et al ., 2005 ). However, inner speech is a complex and varied phenomenon. In behavioural studies, everyday inner speech is often reported to be involved in self-awareness, past and future thinking and emotional reflection ( D’Argembeau et al ., 2011 ; Morin et al ., 2011 ), while in cognitive research, inner speech appears to fulfill a variety of mnemonic and regulatory functions (e.g. Emerson and Miyake, 2003 ; see Alderson-Day and Fernyhough, 2015a , for a review). Vygotsky (1987) posited that inner speech reflects the endpoint of a developmental process in which social dialogues, mediated by language, are internalized as verbal thought. Following from this view, the subjective experience of inner speech will mirror the external experience of communication and often have a dialogic structure ( Fernyhough, 1996 , 2004 ), involving the co-articulation of differing perspectives on reality and, in some cases, representation of others’ voices. Evidence for the validity of these distinctions is provided by findings from a self-report instrument, the varieties of inner speech questionnaire (VISQ: McCarthy-Jones and Fernyhough, 2011 ). Studies with student samples have documented high rates of endorsement (>75%) for inner speech involving dialogue rather than monologue, alongside a number of other phenomenological variations ( Alderson-Day et al ., 2014 ; Alderson-Day and Fernyhough, 2015b ). Recognizing this complexity of inner speech, particularly its conversational and social features, is important both for ecological validity ( Fernyhough, 2013 ) and for understanding atypical cognition ( Fernyhough, 2004 ). Auditory verbal hallucinations (AVH) have been proposed to reflect misattributed instances of inner speech ( Bentall, 1990 ; Frith, 1992 ), but studies inspired by this view have arguably relied on a relatively impoverished, ‘monologic’ view of inner speech. In the context of a growing recognition of social and conversational dimensions of AVH ( Bell, 2013 ; Ford et al ., 2014 ), knowing more about the heterogeneity of inner speech could enhance AVH models ( Jones and Fernyhough, 2007 ). Almost no data exist on the neural basis of dialogic or conversational inner speech, and what there is has largely focused on imagining words or sentences spoken in other voices (often referred to as ‘auditory verbal imagery’). For example, Shergill et al . (2001) asked participants either to silently rehearse sentences of the form ‘I like x …’ in their own voice (inner speech) or to imagine sentences spoken in another voice in the second or third person (auditory verbal imagery). While sentence repetition was associated with activation of left IFG, superior temporal gyrus (STG), insula and the SMA, imagined speech in another person’s voice recruited a bilateral frontotemporal network, including right IFG, left pre-central gyrus and right STG. Similarly, in an AVH study by Linden et al . (2011) , auditory imagery for familiar voices, such as conversations with family members, was associated with bilateral activation in IFG, superior temporal sulcus (STS), SMA and anterior cingulate cortex in healthy participants. Research on overt conversational processing has also implicated a bilateral network including right frontal and temporal homologues of left-sided language regions. For example, Caplan and Dapretto (2001) compared judgements for logical and contextual violations of conversations in an functional magnetic resonance imaging (fMRI) task. Whereas logic judgements were associated with a left-sided Broca–Wernicke network, judgements about pragmatic context recruited right inferior frontal and middle temporal gyri, along with right prefrontal cortex (PFC). The involvement of right frontotemporal regions in pragmatic language processing is supported by evidence of selective impairments in prosody, humour and figurative language in cases of right-hemisphere damage ( Mildner, 2007 ). Finally, two recent studies by Yao et al . ( 2011 ; 2012 ) have indicated a specific role for right auditory cortex in the internal representation of other voices. In a study of silent reading, Yao et al . (2011) examined activation of left and right auditory cortex when participants read examples of direct and indirect speech (e.g. ‘The man said ‘I like cricket’’ vs ‘The man said that he likes cricket’). Reading of direct speech was specifically associated with activation in middle and posterior right STS compared with indirect speech. The same areas were also active in a second study ( Yao et al ., 2012 ) when participants listened to examples of direct speech read in a monotonous voice, but that was not the case during listening to indirect speech. Yao et al . argued that the activation of these regions during silent reading and listening to monotonous direct speech might reflect an internal simulation of the suprasegmental features of speech, such as tone and prosody. Taken together, these findings suggest that dialogic forms of inner speech are likely to draw on a range of regions beyond a typical left-sided perisylvian language network, including the right IFG, right middle temporal gyrus (MTG) and the right STG/STS. Following Shergill et al . (2001) and, to a lesser degree, Yao et al . (2011) , it could be hypothesized that the involvement of these regions is required for the simulation of other people’s voices to complement one’s own inner speech. On such a view, dialogic inner speech could be conceptualized simply as monologic inner speech plus the phonological representation of other voices, leading to recruitment of voice-selective regions of right temporal cortex. However, generating an internal conversation requires more than simply mimicking the auditory qualities of the voices involved. First, dialogic inner speech could draw on theory-of-mind (ToM) capacities, requiring not only just the representation of a voice but also the sense and intention of a plausible and realistic interlocutor. If dialogic inner speech utilized such processes, then it should be possible to identify recruitment of typical ToM regions, including medial PFC (mPFC), posterior cingulate/precuneus and the temporoparietal junction (TPJ) area, encompassing posterior STG, angular gyrus and inferior parietal lobule ( Spreng et al ., 2009 ). Right TPJ has been associated with ToM in a number of fMRI and positron emission tomography (PET) studies, mostly based on false-belief tasks ( Saxe and Powell, 2006 ), while left TPJ has been linked to mental state representation ( Saxe and Kanwisher, 2003 ) and understanding of communicative intentions ( Ciaramidaro et al ., 2007 ). A view of dialogic inner speech as drawing on ToM capacities would suggest that it should be associated with established ToM networks and posterior temporoparietal cortex, in addition to frontotemporal regions associated with voice representation. A second key difference between dialogue and monologue concerns their structure and complexity. Generating an internal dialogue involves representational demands that are absent from sentence repetition or subvocal rehearsal. Whereas, in monologue, a single speaker’s voice or perspective is sufficient, in dialogue more than one perspective must be generated, maintained and adopted on an alternating basis ( Fernyhough, 2009 ). Internally simulating a conversation could also involve imagination of setting, spatial position and other details that distinguish interlocutors. Therefore, any differences observed between dialogic and monologic inner speech may not reflect representation of other voices or agents, so much as indexing the requirement to generate and flexibly switch between conversational positions and situations ‘in the mind’s eye’. If dialogic inner speech depended on such skills, it might be expected to recruit areas more typically associated with the generation and control of mental imagery, such as middle frontal gyrus (MFG), precuneus and superior parietal cortex ( Zacks, 2007 ; McNorgan, 2012 ). There are therefore reasons to believe that the production of dialogic inner speech will differ from monologic examples of the same process in three ways: recruitment of regions involved in representing other voices, involvement of ToM resources to represent other agents and the activation of brain networks involved in the generation and control of mental imagery. To test these predictions, we employed a new fMRI paradigm for eliciting monologic (i.e. verbal thinking from a single perspective) and dialogic inner speech, so that the neural correlates of the two can be compared. To investigate the cognitive processes involved in dialogic inner speech, we used a conjunction analysis ( Price and Friston, 1997 ) to compare dialogue-specific activation with two other tasks: a ToM task ( Walter et al ., 2004 ) and a novel perspective-switching task. The ToM task was chosen because it included non-verbal scenarios requiring inferences about communication and the representation of other agents’ intentions; in this way, any conjunction between dialogue and ToM should not reflect overlaps in the processing of verbalized language. The perspective-switching task was developed to match the switching and imagery-generation demands of the dialogic task, while avoiding the inclusion of social agents, which feature in many existing perspective-switching tasks. Conjunctions observed between the perspective-switching and dialogic tasks should therefore reflect similarities in structure and task demands, rather than representations of agents and mental states tapped in the ToM task. We predicted that (i) dialogic inner speech—in contrast to a monologic control condition—would activate not only right-hemisphere language homologue regions such as right IFG, MTG and STG but also areas typically associated with ToM processing, such as the TPJ and (ii) any further differences between dialogic and monologic scenarios would overlap with networks associated with perspective switching and mental imagery, such as the MFG or the superior parietal lobule. Materials and methodsParticipants. Twenty-one individuals [6 male; age m (s.d.) = 24.38 (6.73) years] were recruited from university settings. All participants were right-handed, native English speakers with normal or corrected-to-normal vision. No participants reported any history of cardiovascular disease, neurological conditions or head injury. Participants received either course credit or a gift voucher. All procedures were approved by the local university ethics committee. Scanning materials and procedureParticipants completed three tasks in the scanner: inner speech, ToM and perspective-switching (followed by an anatomical scan). Each task was preceded by a single practice trial. All stimuli were presented using E-Prime 2.0 ( Schneider et al ., 2002 ). Participants viewed stimuli by looking upwards at a mirror directed at a monitor (Cambridge Research Systems Ltd. BOLDscreen MR Safe display; 1920 × 1200 resolution, refresh rate 60 Hz) placed behind the scanner bore. Button press responses (all right-handed) were collected using a fiber-optic response button box (Psychology Software Tools). Inner speechParticipants were presented with a written description of a scenario involving either dialogue or monologue and were asked to generate inner speech in that scenario until they saw a cue to stop. Dialogic scenarios involved conversations and interviews with familiar people ( Table 1 ). Monologic scenarios were matched to dialogic scenarios for their content and setting, but only included a single speaker. Instructions were presented for 10 s, followed by a fixation cross (the cue for inner speech) for 45 s and an intertrial interval of 3–5 s (including a stop signal for 2 s). In total, five dialogic and five monologic scenarios were presented. At the end of the scanning session, participants were asked to rate out of 100 (i) how vividly they imagined the scenarios, (ii) the vividness of any visual imagery they used during the task and (iii) the everyday characteristics of their own inner speech, using the VISQ ( McCarthy-Jones and Fernyhough, 2011 ). The imagery self-ratings were included to check task compliance and to provide a control indicator of how much participants drew on visual (rather than verbal) imagery during the task. The VISQ was included for exploratory analysis of how individual differences in everyday inner speech may have affected task performance and related brain activations. It includes four subscales: dialogic inner speech (items include, e.g. ‘I talk back and forward to myself in my mind about things’), evaluative/motivational inner speech (e.g. ‘I think in inner speech about what I have done, and whether it was right or not’), other people in inner speech (e.g. ‘I experience the voices of other people asking me questions in my head’) and condensed inner speech (e.g. ‘I think to myself in words using brief phrases and single words rather than full sentences’). The VISQ has been shown to have good internal and test–retest reliability ( McCarthy-Jones and Fernyhough, 2011 ; Alderson-Day et al ., 2014 ). Dialogic and monologic scenarios in the inner-speech task
Theory-of-mindUsing a cartoon-based ToM task from Walter et al . (2004) , participants viewed a sequence of three cartoons depicting a simple story (‘Story’ phase) and were then prompted to choose the logical end of the story from three options (‘Choice’ phase). Stories either required deciphering of actors’ intentions (e.g. pointing to see if a seat was free) or reasoning about physical causality (e.g. a football breaking some bottles). To examine ToM skills relevant to inner speech, the ‘communicative intention’ condition from Walter et al . (2004) was used, as compared with the physical reasoning control condition. ‘Story’ phase images were presented sequentially for 3 s each, followed by the ‘Choice’ phase for 7 s and a jittered intertrial interval of 7–11 s. A total of 10 ToM stories and 10 physical reasoning stories were presented in a random order. Participants indicated which image completed the story (A, B or C) using a button box, and their percentage accuracy was recorded. Visual perspective switchingThe timing and structure of the perspective-switching task was designed to match the inner-speech task. Participants first viewed an instruction page (10 s) describing a visual scene or object and asking them to imagine it from a particular perspective, e.g. ‘Imagine a train viewed from the outside. Try to picture what it looks like in your mind.’ Underneath, this was followed by an instruction to either switch perspective when prompted by a cue (the ‘Switch’ condition) or to maintain the image from single perspective until prompted to stop (the ‘Stick’ condition). In the Switch condition, the instruction page was followed by a 45 s imagery phase, in which every 7 s a cue appeared (either ‘OUTSIDE’ or ‘INSIDE’, 2 s presentation). In the Stick condition, cues appeared with the same regularity but only from one perspective (i.e. only ‘INSIDE’). After scanning, participants rated how vividly they had imagined each scene/object, and how easy they found switching between different viewpoints (rated out of 100). Mock scanner behavioural taskProduction of inner speech is difficult to verify objectively, leaving open the possibility that any differences observed between dialogic and monologic scenarios might not reflect underlying inner speech processes. To explore this further, we ran a post hoc behavioural study in a mock MRI scanner that replicated the layout, conditions and stimulus setup of the 3T scanner used for imaging. A separate set of 20 participants [2 male; age m (s.d.) = 19.65 (1.31) years] attempted the original inner-speech task and then rated a variety of phenomenological characteristics for each dialogic and monologic scenario (see Supplementary Materials for an example response sheet). Specifically, participants rated each scenario for its (i) overall vividness, (ii) presence of inner speech, (iii) presence of visual imagery, (iv) vividness of one’s own voice, (v) vividness of other voices, and (vi) the number of times there was a ‘switch’ in perspective, voice or role (items 1–5 were rated as percentages). Following this, participants also attempted a novel version of the inner-speech task that included articulatory suppression, a commonly used secondary task that is thought to interfere with inner speech use (e.g. Baddeley et al. , 1984 ; Williams et al ., 2012 ). Specifically participants were asked to attempt the inner-speech task again but while repeating a different day of the week, out loud, for the duration of each scenario. The idea of this was to test whether engaging with the inner-speech task really did require use of inner speech to be performed successfully. To minimize effects of repeating the same scenarios, participants were encouraged to modify each situation (i.e. imagine speaking to a different relative) and only had to imagine scenarios for half the original time (22.5 s). fMRI acquisitionAll data were acquired at Durham University Neuroimaging Centre using a 3T Magnetom Trio MRI system (Siemens Medical Systems, Erlangen, Germany) with standard gradients and a 32-channel head coil. T2*-weighted axial echo planar imaging (EPI) scans were acquired parallel to the anterior/posterior commissure line with the following parameters: field of view (FOV) = 212 × 212 mm, flip angle (FA) = 90°, repetition time (TR) = 2160 ms, echo time (TE) = 30 ms, number of slices (NS) = 35, slice thickness (ST) = 3.0 mm, interslice gap = 0.3 mm, matrix size (MS) = 64 × 64. Images for each task were collected as separate runs (280 volumes each per run). For each participant, an anatomical scan was acquired using a high-resolution T1-weighted 3D-sequence (NS: 192; ST: 1 mm; MS: 512 × 512; FOV: 256 × 256 mm; TE: 2.52 ms; TR: 2250 ms; FA 9°). Data analysisAll analyses were conducted using Statistical Parametric Mapping (SPM), version 8 (Wellcome Department of Cognitive Neurology, London, UK) implemented in MATLAB (2012b) (The Mathworks Inc). Images were realigned to the first image to correct for head movement. After realignment, the signal measured in each slice was shifted in time relative to the acquisition time of the middle slice using a sinc interpolation to correct for different acquisition times. Volumes were then normalized into standard stereotaxic anatomical MNI-space using the transformation matrix calculated from the first EPI-scan of each subject and the EPI-template. The default settings for normalization in SPM8 with 16 non-linear iterations and the standard EPI-template supplied with SPM8 were used. The normalized data with a resliced voxel size of 3 × 3 × 3mm were smoothed with a 6 mm full width half maximum (FHWM) isotropic Gaussian kernel to accommodate intersubject variation in brain anatomy. The time-series data were high-pass filtered with a high-pass cutoff of 1/128 Hz and first-order autocorrelations of the data were estimated and corrected for. The first four volumes of each run were discarded to allow for equilibrium of the T2 response. Movement parameters from the realignment phase were visually inspected for outliers and included as regressors for single-subject (first level) analyses. Single-subject analyses were conducted using a general linear model. The inner-speech and perspective-switching tasks were modelled as a block design with an instruction phase (4 volumes) and imagery phase (17 volumes). For the inner-speech task, three conditions were modelled in the analyses: monologic inner speech (17v), dialogic inner speech (17v) and the instruction phase (4v). The perspective-switching task was modelled in an identical way, but with Switch and Stick conditions instead of dialogic and monologic. The expected hemodynamic response at stimulus onset was modelled as a block design, convolved with a canonical hemodynamic response function. Following Walter et al . (2004) , the ToM task was modelled as an event-related design with four regressors: ToM-Story, ToM-Choice, Physical-Story and Physical-Choice. Subsequently, parameter estimates of the regressor for each of the different conditions were calculated from the least mean squares fit of the model to the time-series. ‘Story’ and ‘Choice’ regressors on the ToM task were combined within each condition for the generation of contrast images ( Walter et al ., 2004 ). For the inner-speech task, differences between parameter estimates for dialogic and monologic inner speech were tested within-subjects at the individual level, then tested at the group level with a one sample t -test. Comparisons of dialogic and monologic conditions with baseline were also made to provide further information on each condition’s neural correlates. The same procedure was applied for key comparisons on the ToM task and perspective-switching task (ToM Reasoning > Physical Reasoning and Switch > Stick, respectively). The contrasts between dialogic and monologic inner speech, ToM Reasoning and Physical Reasoning and Switch and Stick conditions were then used in a conjunction analysis to assess shared components of each task. Because differences between dialogic and monologic inner speech were expected to be relatively small, we chose a cluster correction with a higher sensitivity to small sample sizes in comparison to the SPM cluster correction. A cluster extent threshold method ( Slotnick et al ., 2003 ; Slotnick and Schacter, 2004 ) was used to identify groups of contiguous voxels that were active at a value of P < 0.05, corrected for multiple comparisons. A Monte Carlo simulation with 10 000 iterations was used to estimate cluster thresholds based on the voxel-wise probability of a Type 1 error. For a voxel-wise error of P < 0. 01, a cluster of 11 or more voxels was required for P < 0.05, corrected for multiple comparisons. For a voxel-wise error of P < 0.001, clusters of 6 or more voxels were required for P < 0.05, corrected. As the latter criterion has been recommended to avoid false positives ( Woo et al ., 2014 ), the results reported later are all significant at P < 0.05 (corrected) based on a voxel-wise error of P < 0.001, unless otherwise stated. MNI voxel positions were converted into equivalent Talairach and Tournoux (1988) co-ordinates in MATLAB for anatomical labelling. All structure and Brodmann areas (BA) were labelled using the Talairach Daemon applet ( Lancaster et al ., 2000 ). Brain images were generated using SPM and MRICron ( Rorden et al ., 2007 ). Two participants were excluded from the analyses due to movement during the inner-speech task. Thus, the results later display data from a sample of 19 participants (5 male, age m (s.d.) = 24.63 (7.01) years). Table 2 displays the contrast between dialogic and monologic inner speech (all clusters at P < 0.05, corr.). Significantly increased activation for dialogic compared with monologic inner speech was evident in STG bilaterally, left inferior and medial frontal gyri and a collection of posterior midline structures, including the left precuneus and right posterior cingulate. The opposite contrast, Monologic > Dialogic inner speech, did not identify any significant activations. Compared with baseline, dialogic inner speech was associated with significantly increased activation in left posterior insula ( x = −39; y = −18, z = 7; t = 4.38, P < 0.05, corr.) only. At more liberal threshold levels (when the cluster extent was thresholded based on a voxel-wise error of P < 0.01), both dialogic and monologic inner speech were associated with left-hemisphere activation compared with baseline, including the left IFG, medial frontal gyrus, insula and caudate. Regions activated significantly more during dialogic inner speech as compared with monologic inner speech (all P < 0.05, corrected, minimal cluster size 6 voxels.)
Self-ratings for vividness of inner speech scenarios were high ( m = 73.42, s.d. = 13.13). Vivid visual imagery was also reported, although this tended to vary considerably across participants ( m = 58.68, s.d. = 27.73, range = 0–100). The contrast between ToM and physical reasoning was associated with significant activation in anterior and posterior STG bilaterally, along with midline activation centring on left precuneus ( Table 3 ). Although left STG activity separated into anterior and posterior clusters, right STG activation was centred on posterior areas close to the TPJ but evident all along the gyrus. In contrast, physical reasoning compared with ToM reasoning showed significantly greater recruitment of the left anterior lobe of the cerebellum (−27, −48, −12, t = 5.97), right cuneus (15, −82, 5; t = 5.73), right caudate (27, −41, 18; t = 3.88), left post-central gyrus (−45, −28, 36; t = 4.60) and left lingual gyrus (−21, −80, −8; t = 4.10). Performance on the ToM task was acceptable (Accuracy m = 84.21%, s.d. = 10.03%, range = 65–100%). Regions activated significantly more during theory-of-mind (ToM) reasoning as compared with physical reasoning (all P < 0.05, corr.)
Compared with baseline, both the Switch and Stick conditions of the perspective-switching task showed significant activation: the Switch condition was associated with activation of left posterior insula (−45, −7, 1; t = 4.16) and left STG (−31, 1, −14; t = 4.78), while the Stick condition indicated activation of right posterior insula (42, −4, 2, t = 5.14), left MFG (−21, −7, 46; t = 4.77), left IFG (−45, 25, −5, t = 4.25) and right transverse temporal gyrus (33, −27, 13, t = 4.08, all P < 0.05, corr.). However, no significant differences were evident in the direct contrast between the two conditions. Self-ratings for vividness of mental images were again high ( m = 76.68, s.d. = 18.00), as were ratings of ease in making shifts in perspective ( m = 75.53, s.d. = 21.85). Conjunctions of inner speech, theory-of-mind and perspective-switchingThe contrasts between (i) dialogic and monologic inner speech and (ii) ToM and physical reasoning were incorporated into a conjunction analysis. As Figure 1 shows, only one cluster showed significant activation differences for both contrasts, centring on right posterior STG (48, −41, 20, t = 4.59, cluster size = 15, P < 0.05, corr.). Using a voxel-wise error of P < 0.01 for exploratory purposes, overlaps between the two tasks were also evident in right anterior STG, precuneus, right MTG, left paracentral lobule and right fusiform gyrus (all P < 0.05, corr.). When a conjunction analysis was run comparing the Dialogic > Monologic contrast and the Switch > Stick contrast, no significant clusters were observed (all P > 0.05, corr.). Overlaps at the lower significance threshold (voxel-wise P < 0.01) were evident in a ventral cluster encompassing the right posterior cingulate (3, −65, 10), the left cuneus (−12, −68, 7) and smaller clusters in right IFG (33, 31, 5) and left precuneus (−9, −60, 40).  Conjunction of dialogic inner speech and theory-of-mind. A cluster in right STG ( Fig.1 a) was evident for both dialogic inner speech > monologic inner speech and ToM > physical reasoning, rendered here on the standard MNI brain supplied by SPM. Dialogic inner speech ( Fig 1 b; blue) was evident in right STG, cingulate and frontal gyrus, while ToM (yellow) was associated with extensive right STG activation running posterior to anterior. Their conjunction (green) was at the posterior end of right STG, in the TPJ area. ToM, Theory-of-mind; STG, superior temporal gyrus, all P < 0.05, corr., clusters > 6 voxels. Individual differences in inner speechWe examined correlations between (i) Dialogic > Monologic inner speech activations and self-report scores for vividness during the task and (ii) Dialogic > Monologic inner speech activations and self-report scores on the VISQ. These analyses revealed very similar activation areas to the group analysis. Self-report scores for vividness of the inner speech scenarios were significantly associated with clusters in right posterior MTG (36, −58, 15; t = 5.47, cluster size = 37) and right cingulate gyrus (6, −23, 35; t = 4.93, cluster size = 9; P < 0.05, corr.). Scores on the Dialogic Inner Speech subscale of the VISQ were associated with a cluster in the same area of right MTG (39, −58, 15; t = 6.57, cluster size = 10), along with two areas of the right precuneus ((i) 15, −67, 26; t = 4.89, cluster size = 11; (ii) 15, −49, 31; t = 4.66, cluster size = 13; all P < 0.05, corr.). No significant associations were observed for self-reported use of visual imagery nor for the other components of the VISQ (evaluative, other people and condensed inner speech). Generating dialogic and monologic scenarios: the roles of inner speech and imagery processesPhenomenological ratings from the mock scanner version of the task were used to examine use of inner speech and visual imagery across dialogic and monologic scenarios. As Table 4 indicates, dialogic and monologic scenarios were equivalent in all respects bar vividness of other voices ( t = 7.47, df = 19, P < 0.001) and mean number of switches per scenario ( t = 5.35, df = 19, P < 0.001), both of which were more common for dialogic inner speech (all P values are Bonferroni corrected). For both dialogic and monologic scenarios, inner speech was present to a significantly greater degree than visual imagery (dialogic: t = 3.21, df = 19, P = 0.036; monologic: t = 3.79, df = 19, P =0.010). As may be expected, vividness for one’s own voice was also stronger on average than vividness of other voices (dialogic: t = 5.95, df = 19, P < 0.001; monologic: t = 11.00, df = 19, P < 0.001). Self-reported vividness ratings for dialogic and monologic scenarios in mock scanner conditions
*** P < 0.001 (Bonferroni-corrected P values used). Finally, Table 5 shows mean ratings for dialogic and monologic scenarios combined, compared across the normal and articulatory suppression versions of the task. Articulatory suppression had the effect of lowering vividness ratings for inner speech, one’s own voice and other voices but had no effect on levels of visual imagery ( P = 0.999) and number of switches ( P = 0.148). Self-reported vividness ratings for inner speech scenarios in mock scanner under normal conditions and during articulatory suppression
** P < 0.01, *** P < 0.001 (Bonferroni-corrected P values used). This study attempted to examine neural differences between two varieties of internal self-talk: dialogic and monologic inner speech. In line with the hypothesis that generating dialogic scenarios would be associated with recruitment of a network extending beyond the left frontotemporal language regions, dialogue was associated with significantly greater activation, compared with monologue, in the precuneus, posterior cingulate and the right STG (BA13 and BA41), alongside activation in left insula, IFG, STG and cerebellum. Conjunction analysis identified an overlap with ToM reasoning specifically in right posterior STG, although shared substrates with visual perspective-switching could not be fully assessed due to null results in the contrast between switching and single-perspective imagery on that particular task. The involvement of a left-hemisphere network including IFG, STG and the cerebellum during generation of dialogic scenarios is consistent with prior inner speech studies ( Shergill et al ., 2001 ; Simons et al ., 2010 ; Geva et al ., 2011 ) and implies a greater demand on these areas when a dialogue must be produced (in contrast to a monologue). Although the IFG and insula are often implicated in inner-speech tasks (although see Jones, 2009 ), activations of posterior STG and lateral regions of temporal cortex are observed depending on specific task demands, such as self-monitoring of inner speech rate ( Shergill et al ., 2002 ) and phonology ( Aleman et al ., 2005 ). The cerebellum, in contrast, has been proposed to support maintenance of verbal working memory (i.e. articulatory rehearsal) via its connections with motor cortex ( Marvel and Desmond, 2010 ). Although a number of right-hemisphere regions were active during the dialogic condition, there was less evidence to suggest that this involved the specific recruitment of either language region homologues or voice-selective areas. For example, although activation in the right STG was more anterior than in the left STG, and was close to regions that have been previously related to listening to familiar voices ( Shah et al ., 2001 ), it actually overlapped more with areas previously associated with spatial rather than auditory processing ( Ellison et al ., 2004 ). This suggests that the right-hemisphere differences between the dialogic and monologic conditions were not simply picking out additional voice representation demands (cf. Shergill et al ., 2001 ) but relate instead to other cognitive factors. The results of conjunction analysis indicated the involvement of social-cognitive processes in dialogic scenarios. Activity in posterior right STG was evident during both dialogic scenarios and ToM reasoning, in a region previously linked to both ToM ( Fletcher et al ., 1995 ) and imagery for personal perspectives ( Ruby and Decety, 2001 ). It is also close to sections of right TPJ that have been implicated in representation of other people’s beliefs and states of knowledge ( Saxe and Powell, 2006 ; Sebastian et al ., 2012 ). Along with ToM, right TPJ has been proposed to play a role in managing divided attention and non–ToM-based perspective switching ( Mitchell, 2008 ; Aichhorn et al ., 2009 ), although there is debate as to whether these functions are subserved by the same or separable components of the TPJ ( Scholz et al ., 2009 ). Recent research on structural connectivity suggests that TPJ splits into three separate subregions: a dorsal component connecting to lateral anterior PFC, an anterior region connecting to the ventral attentional network and a posterior region connecting to social cognitive areas such as the precuneus and posterior cingulate ( Mars et al ., 2012 ). The cluster identified in this study would appear to be located between the latter two putative sub-regions of the TPJ, implicating both social-cognitive and attentional processes. Apart from right STG, there was evidence (at less conservative significance levels) of functional overlaps between dialogic inner speech and ToM in an area of right MTG that has been previously linked to retrieval of face-word associations ( Henke et al ., 2003 ) and reflection on third-person traits ( Kjaer et al ., 2002 ). There was also overlap in posterior midline structures, although generally the two processes appeared to involve separate parts of the precuneus and posterior cingulate cortex, with the ToM cluster much closer to the midline. Dialogic inner speech also prompted activation in anterior medial frontal gyrus but ToM reasoning did not (cf. Walter et al ., 2004 ). The involvement of anterior and posterior midline structures in the contrast between dialogic and monologic conditions may indicate that the default mode network (DMN) is involved in generating internal dialogue ( Buckner et al ., 2008 ). ToM, autobiographical memory and resting-state cognition have been proposed to draw on a shared ‘core’ network including mPFC, precuneus, posterior cingulate and TPJ ( Spreng et al ., 2009 ). If the dialogic quality of inner speech imbues it (compared with monologic inner speech) with qualities of open-endedness, flexibility and creativity ( Fernyhough, 1996 , 2009 ), then it would arguably draw on some of the same introspective processes that the DMN is thought to underpin. The remaining clusters identified in the contrast between dialogic and monologic inner speech also point to a range of processes associated with DMN functioning. Left precuneus has been associated with the simulation of third-person perspectives ( Ruby and Decety, 2001 ) and episodic memory retrieval ( Zysset et al ., 2002 ), while right posterior cingulate has been linked to retrieval of autobiographical memories ( Fink et al ., 1996 ; Ryan et al ., 2001 ). One possibility is that dialogic scenarios simply place a greater demand on memory processes, requiring the representation of specific events or people that would otherwise not be needed for generating one’s own voice. This seems unlikely, however, given that the monologic and dialogic scenario pairs were chosen to have the same general content (a school visit, a job interview, etc.), which should have minimized any differences between the conditions in terms of autobiographical memory demands. Alternatively, it may be that the scene construction processes thought to underpin autobiographical memory retrieval ( Hassabis and Maguire, 2009 ) are similar to those recruited in producing a realistic and immersive dialogue. A direct comparison of scene construction, autobiographical memory and inner speech would be required to parse out these possibilities. The results from the individual differences analysis highlighted a slightly different range of activation foci to the group contrast for dialogic > monologic inner speech: specifically, vividness ratings correlated with activation in the right MTG and cingulate gyrus, while dialogic inner speech (assessed as a general trait) correlated with the same MTG area, plus two sections of right precuneus. This contrasts with the involvement of ‘classic’ inner speech areas (left IFG, STG and cerebellum) and the focus on right STG seen in the group analysis of dialogic vs monologic inner speech. The lack of correlates in the individual differences analysis in left frontotemporal areas suggests that covert articulation, per se , may not be so important for generating particularly vivid or dialogic scenarios. Nevertheless, the other areas identified in this analysis implicate similar processes and networks to the group analysis. For instance, the right MTG and the two sections of the right precuneus that correlated with dialogic inner speech reports have previously been implicated in theory-of-mind ( Atique et al ., 2011 ; Brüne et al ., 2011 ). Other regions identified in this analysis are associated with processes that are also likely to be involved in generating dialogic scenarios. For example, right MTG has been associated with accurate and confident recall ( Chua et al ., 2006 , Giovanello et al ., 2010 ), while the right precuneus has been associated with retrieval of verbal episodic memory ( Fernandes et al ., 2005 ), context-rich autobiographical memories ( Gilboa et al ., 2004 ) and first-person perspectives memories (sometimes called ‘field’ memories; Nigro and Neisser, 1983 ; Eich et al ., 2009 ). The activation of cingulate gyrus for vividness ratings, though likely not specific to this process, has been linked previously to a right anterior insula network involved in affective engagement ( Touroutoglou et al ., 2012 ). When these results are taken together, it might suggest that the tendency to engage in dialogic inner speech in everyday life does not reflect a trait towards ‘more’ inner speech—understood simply as a greater frequency of covert articulation—but instead indicates a greater tendency to recall and re-engage in previous interactions with others, and perhaps even to use these episodic memories to plan future social interactions. LimitationsOne-key limitation in interpreting the present results is the extent to which the inner-speech task actually elicited inner speech. Participants were prompted to generate dialogic and monologic scenarios in inner speech, but they may have varied in their ability to do so, or may have drawn on other forms of simulation (such as visual imagery). Similar imagery-generation paradigms have been criticized in related fields (e.g. auditory imagery; Zatorre and Halpern, 2005 ) and in general it is preferable to include an objective test of inner speech use, such as paradigms that require participants to make rhyming judgements ( Geva et al ., 2011 ) or to assess metric stress ( Aleman et al ., 2005 ). To address this limitation, we gathered behavioural data from a mock scanner task in which a separate set of participants reported on their imagery processes for each scenario used during scanning. Scenario stimuli generally prompted high levels of inner speech compared with visual imagery across both dialogic and monologic scenarios, while both kinds of scenario proved difficult to generate (in the sense of leading to post-scan reports of vivid auditory imagery) when inner speech was blocked via articulatory suppression (repeating days of the week). Additional corroboration of the paradigm was provided by the individual differences analysis of inner speech scores, which implicated broadly similar brain regions (right posterior temporal and midline structures) and similar processes (Theory-of-Mind, autobiographical recall) to the main dialogic–monologic contrast. Taken together, these data at least partly address the concern that participants did not engage in inner speech in producing dialogic and monologic scenarios. Nevertheless, the results presented here need to be replicated alongside a battery of other inner speech measures that do not rely on participants’ self-reports ( Aleman et al ., 2005 ), to fully assess the extent to which our new paradigm elicits dialogic and monologic inner speech. The individual difference correlates in particular require replication in a much larger sample than tested here. A second limitation is that the perspective-switching task did not produce consistent activation maps that could be used in the conjunction analysis, thus limiting the assessment of whether the dialogicality of inner speech depends purely on demands associated with generating and coordinating mental imagery. A novel imagery task was deployed here to match the structure and timing of the inner-speech task but it is possible that a different task with similar demand characteristics would have provided a better control. For instance, mental rotation tasks involve demands to generate and flexibly manipulate mental images, and are consistently associated with activation in a network of frontoparietal regions ( McNorgan, 2012 ). Implications for psychopathologyNotwithstanding these caveats, the results presented here could have important implications for understanding inner speech in both typical and atypical populations. Although the involvement of ToM-related networks in internal dialogue is perhaps unsurprising, our conjunction analysis findings align with the view that articulating different perspectives may be an important feature of more complex forms of inner speech ( Fernyhough, 1996 ). Abnormalities in the interplay between inner speech and ToM networks may thus explain some important findings in atypical groups. As a first example, dominant models of AVH explain the phenomenon in terms of misattributed inner speech but struggle to explain why these hallucinations are distinctly experienced in another person’s voice ( Jones and Fernyhough, 2007 ). Previous work has already suggested that dialogic conceptions of inner speech may account for the presence of the voices of others in one’s head ( Fernyhough, 2004 ). Our present study extends this by showing commonalities between many of the neural regions activated during AVH (such as left STG, left insula, left IFG) and those strongly activated during dialogic inner speech ( Jardri et al ., 2011 ; Kühn and Gallinat, 2012 ). Future studies should test the proposal that findings from AVH research can be accounted for by dialogic inner speech occurring in conjunction with altered activity in other neural areas, such as the SMA ( McGuire et al ., 1995 ; Raij and Riekki, 2012 ), causing it to be experienced as non–self-produced. Our study also implies that neuroscientific studies of AVH need to consider social-cognitive networks alongside speech processing to fully understand how such hallucinations occur (see also Bell, 2013 ). As a second example, atypical ToM has for a long time been considered a core feature of autism spectrum disorder ( Baron-Cohen et al ., 1985 ), but differences in inner speech in autism have only been studied relatively recently ( Whitehouse et al ., 2006 ; Wallace et al ., 2009 ; Holland and Low, 2010 ). Early experience in autism is characterized by delays in language development and significant difficulties with social and communicative interaction ( WHO, 1993 ). If inner speech is shaped by communicative experience—as a Vygotskian approach would suggest—then qualitative differences in the inner speech of people on the autistic spectrum may also be expected ( Fernyhough, 1996 ; Williams et al ., 2012 ). The data presented here are consistent with the idea that there are important interconnections between atypical ToM skills and atypical inner speech, which may mutually inform one another over the course of development. The direction of this relationship remains to be explored: on the one hand, problems with ToM could cause a qualitatively different experience of inner speech in autism; on the other hand, a lack of conversational or communicative inner speech might impact ToM development through limiting opportunities for dialogic interaction with others ( Fernyhough, 2008 ). In conclusion, we have presented the first neuroimaging study of some important varieties of inner speech, focusing on the contrast between dialogic and monologic forms of self-talk. Our findings provide initial support for the idea that forms of inner speech exist which can be both phenomenologically and neurologically distinguished from the silent commentary of a single inner voice. The data presented here suggest that generating silent dialogues draws on a wider network than classical regions associated with language production and comprehension, including recruitment of a core part of the ToM network. Further work is needed to disambiguate (i) the exact processes shared between dialogic inner speech and ToM, (ii) the involvement of the DMN in this conjunction and (iii) relative contributions of inner speech and forms of mental imagery to creating vivid inner dialogues. Supplementary MaterialAcknowledgements. The authors thank Henrik Walter and Angela Ciaramidaro for providing test materials for the Theory-of-Mind task. They also thank Jon Simons for his helpful comments on the article. This work was supported by the Wellcome Trust ( WT098455 ). S.M.J. was supported by an Australian Research Council Discovery Early Career Researcher Award ( DE140101077 ). Supplementary dataSupplementary data are available at SCAN online. Conflict of interest . None declared.
Vocal cordsEsophageal voice, artificial larynx.

 Our editors will review what you’ve submitted and determine whether to revise the article.
The two true vocal cords (or folds) represent the chief mechanism of the larynx in its function as a valve for opening the airway for breathing and to close it during swallowing . The vocal cords are supported by the thyroarytenoid ligaments, which extend from the vocal process of the arytenoid cartilages forward to the inside angle of the thyroid wings. This anterior insertion occurs on two closely adjacent points, the anterior commissure. The thyroarytenoid ligament is composed of elastic fibres that support the medial or free margin of the vocal cords. The inner cavity of the larynx is covered by a continuous mucous membrane , which closely follows the outlines of all structures. Immediately above and slightly lateral to the vocal cords, the membrane expands into lateral excavations, one ventricle of Morgagni on each side. This recess opens anteriorly into a still smaller cavity, the laryngeal saccule or appendix. As the mucous membrane emerges again from the upper surface of each ventricle, it creates a second fold on each side—the ventricular fold , or false cord. These two ventricular folds are parallel to the vocal cords but slightly lateral to them so that the vocal cords remain uncovered when inspected with a mirror. The false cords close tightly during each sphincter action for swallowing; when this primitive mechanism is used for phonation, it causes the severe hoarseness of false-cord voice ( ventricular dysphonia). The mucous membrane ascends on each side from the margins of the ventricular folds of the upper border of the laryngeal vestibule, forming the aryepiglottic folds. These folds extend from the apex of the arytenoids to the lateral margin of the epiglottis. Laterally from this ring enclosing the laryngeal vestibule, the mucous membrane descends downward to cover the upper-outer aspects of the larynx where the mucous membrane blends with the mucous lining of the piriform sinus of each side. These pear-shaped recesses mark the beginning of the entrance of the pharyngeal foodway into the esophagus. The mucous membrane of the larynx consists of respiratory epithelium made up of ciliated columnar cells. Ciliated cells are so named because they bear hairlike projections that continuously undulate upward toward the oral cavity , moving mucus and polluting substances out of the airways. The true vocal cords, however, are exceptional in that they are covered by stratified squamous epithelium (squamous cells are flat or scalelike) as found in the alimentary tract . The arrangement is functional, since the vocal cords have to bear considerable mechanical strain during their rapid vibration for phonation, which occurs during many hours of the day. The transition from the respiratory to the stratified epithelium above and below the vocal cords is marked by superior and inferior arcuate (arched) lines. Unfortunately, such transitional epithelium also has the drawback of being easily disturbed by chronic irritation, which is one reason why the large majority of laryngeal cancers begin on the vocal cords. The mucous membrane of the larynx contains numerous mucous glands in all areas covered by respiratory epithelium, excepting again the vocal cords. These glands are especially numerous over the epiglottis and in the ventricles of Morgagni. The mucus secreted by these glands serves as a lubricant for the mucous membrane and prevents its drying in the constant airstream.  The vocal cords also mark the division of the larynx into an upper and lower compartment. These divisions reflect the development of the larynx from several embryonal components called branchial arches . The supraglottic portion differs from the one beneath the vocal cords in that the upper portion is innervated sensorially by the superior laryngeal nerve and the lower (infraglottic) portion by the recurrent (or inferior) laryngeal nerve. The lymphatics (i.e., the vessels for the lymph flow) from the upper portion drain in an upward lateral direction, while the lower lymphatics drain in a lateral downward direction. The space between the vocal cords is called rima glottidis, glottal chink, or simply glottis (Greek for tongue). When the vocal cords are separated (abducted) for respiration , the glottis assumes a triangular shape with the apex at the anterior commissure. During phonation, the vocal cords are brought together (adducted or approximated), so that they lie more or less parallel to each other. The glottis is the origin of voice, although not in the form of a “fluttering tongue” as the Greeks believed. The vocal cords vary greatly in dimension, the variance depending on the size of the entire larynx, which in turn depends on age, sex, body size, and body type. Before puberty, the larynx of boys and girls is about equally small. During puberty , the male larynx grows considerably under the influence of the male hormones so that eventually it is approximately one-third larger than the female larynx. The larynx and the vocal cords thus reflect body size. In tall, heavy males the vocal cords may be as long as 25 millimetres (one inch), representing the low-pitched instrument of a bass voice. A high-pitched tenor voice is produced by vocal cords of the same length as in a low-voiced female contralto. The highest female voices are produced by the shortest vocal cords (14 millimetres), which are not much longer than the infantile vocal cords before puberty (10–12 millimetres). The larynx is, among other things, a musical instrument that follows the physical laws of acoustics fairly closely. Substitutes for the larynxA growing number of middle-aged or older patients have had their larynx removed ( laryngectomy ) because of cancer . Laryngectomy requires the suturing of the remaining trachea into a hole above the sternum (breastbone), creating a permanent tracheal stoma (or aperture) through which the air enters and leaves the lungs. The oral cavity is reconnected directly to the esophagus. Having lost his pulmonary activator (air from the lungs) and laryngeal sound generator, such an alaryngeal patient is without a voice ( aphonic) and becomes effectively speechless; the faint smacking noises made by the remaining oral structures for articulation are practically unintelligible. This type of pseudo-whispering through buccal (mouth) speech is discouraged to help the patient later relearn useful speech on his own. A frequently successful method of rehabilitation for such alaryngeal aphonia is the development of what is called esophageal or belching voice. Some European birds and other animals can produce a voice in which air is actively aspirated into the esophagus and then eructated ( belched ), as many people can do without practice. The sound generator is formed by the upper esophageal sphincter (the cricopharyngeus muscle in humans). As a replacement for vocal cord function, the substitute esophageal voice is very low in pitch , usually about 60 cycles per second in humans. Training usually elevates this grunting pitch to about 80 or 100 cycles. Esophageal voice in humans has been reported in the literature since at least 1841 when such a case was presented before the Academy of Sciences in Paris. After the perfection of the laryngectomy procedure at the end of the 19th century, systematic instruction in esophageal (belching) phonation was elaborated, and the principles of this vicarious phonation were explored. Laryngectomized persons in many countries often congregate socially in “Lost Cord Clubs” and exchange solutions of problems stemming from the alaryngeal condition. Approximately one-third of all laryngectomized persons are unable to learn esophageal phonation for various reasons, such as age, general health, hearing loss , illiteracy, linguistic barriers, rural residence, or other social reasons. These persons, however, can use an artificial larynx to substitute for the vocal carrier wave of articulation. Numerous mechanical and pneumatic models have been invented, but the modern electric larynx is most serviceable. It consists of a plastic case about the size of a flashlight, containing ordinary batteries , a buzzing sound source, and a vibrating head that is held against the throat to let the sound enter the pharynx through the skin. Ordinary articulation thus becomes easily audible and intelligible. Other models lead the sound waves through a tube into the mouth or are encased in a special upper dental plate. More recent efforts aim at surgically inserting an electric sound source directly into the neck tissues to produce a more natural sound resembling that of normal speech. Synonyms of mechanism
Thesaurus Definition of mechanismSynonyms & Similar Words
Examples of mechanism in a SentenceThese examples are programmatically compiled from various online sources to illustrate current usage of the word 'mechanism.' Any opinions expressed in the examples do not represent those of Merriam-Webster or its editors. Send us feedback about these examples. Thesaurus Entries Near mechanismCite this entry. “Mechanism.” Merriam-Webster.com Thesaurus , Merriam-Webster, https://www.merriam-webster.com/thesaurus/mechanism. Accessed 17 Sep. 2024. More from Merriam-Webster on mechanismNglish: Translation of mechanism for Spanish Speakers Britannica English: Translation of mechanism for Arabic Speakers Britannica.com: Encyclopedia article about mechanism Subscribe to America's largest dictionary and get thousands more definitions and advanced search—ad free!  Can you solve 4 words at once?Word of the day. See Definitions and Examples » Get Word of the Day daily email! Popular in Grammar & UsagePlural and possessive names: a guide, 31 useful rhetorical devices, more commonly misspelled words, absent letters that are heard anyway, how to use accents and diacritical marks, popular in wordplay, 8 words for lesser-known musical instruments, it's a scorcher words for the summer heat, 7 shakespearean insults to make life more interesting, 10 words from taylor swift songs (merriam's version), 9 superb owl words, games & quizzes.  Log in to comment on videos and join in on the fun. Watch the live stream of Fox News and full episodes. Reduce eye strain and focus on the content that matters.  Kamala Harris serves up another 'word salad': FaulknerSteamboat Institute Fellow Kaylee McGhee White and former New York State Senator David Carlucci (D) discuss Kamala Harris’ ABC interview and the flip-flops the vice-president has made on various issues.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
IMAGES
VIDEO
COMMENTS
Speech production is the process by which thoughts are translated into speech. This includes the selection of words, the organization of relevant grammatical forms, and then the articulation of the resulting sounds by the motor system using the vocal apparatus.Speech production can be spontaneous such as when a person creates the words of a conversation, reactive such as when they name a ...
Speech mechanism is a function which starts in the brain, moves through the biological processes of respiration, phonation and articulation to produce sounds. ... It begins with the articulators taking one position and then smoothly moving to another position. Summary . Speech mechanism is a complex process unique to humans. It involves the ...
Speech is produced by bringing air from the lungs to the larynx (respiration), where the vocal folds may be held open to allow the air to pass through or may vibrate to make a sound (phonation). The airflow from the lungs is then shaped by the articulators in the mouth and nose (articulation). The field of phonetics studies the sounds of human ...
The speech mechanism is a complex process that can be broken down into four stages: the initiation process, the phonation process, the oro-nasal process, and the articulation process. Why is the ...
Overview of Speech Mechanism. The speech mechanism is a complex and intricate process that enables us to produce and comprehend speech. The speech mechanism involves a coordinated effort of speech subsystems working together seamlessly. Speech Mechanism is done by 5 Sub-systems: I. Respiratory System.
2. Models and Theories of Speech Production. In summarizing his review of the models and theories of speech production, Levelt (1989, p. 452) notes that "There is no lack of theories, but there is a great need of convergence."This section first briefly reviews a number of the theoretical proposals that led to this conclusion, culminating with the influential task dynamic model of speech ...
Speech production is the process of uttering articulated sounds or words, i.e., how humans generate meaningful speech. It is a complex feedback process in which hearing, perception, and information processing in the nervous system and the brain are also involved. Speaking is in essence the by-product of a necessary bodily process, the expulsion ...
The mechanism of phonic breathing involves three types of respiration: (1) predominantly pectoral breathing (chiefly by elevation of the chest), (2) predominantly abdominal breathing (through marked movements of the abdominal wall), (3) optimal combination of both (with widening of the lower chest). The female uses upper chest respiration ...
Articulatory Mechanisms in Speech Production Download book PDF. Download book EPUB. Štefan Beňuš ... Another common setting of the glottis is referred to as creakyvoice. This is the situation when the vocal folds are made very thick by the muscles and open only partially. If you tried imitating the opening of the old squeaky door in a horror ...
Despite scientific interest in verbal communication, the neural mechanisms supporting speech production remain unclear. The goal of the current study is to capture the underlying representations ...
Speech - Voice Production, Acoustics, Physiology: The physical production of voice has been explained for a long time by the myoelastic or aerodynamic theory, as follows: when the vocal cords are brought into the closed position of phonation by the adducting muscles, a coordinated expiratory effort sets in. Air in the lungs, compressed by the expiratory effort, is driven upward through the ...
2.2 The Articulatory System. We speak by moving parts of our vocal tract (See Figure 2.1). These include the lips, teeth, mouth, tongue and larynx. The larynx or voice box is the basis for all the sounds we produce. It modified the airflow to produce different frequencies of sound. By changing the shape of the vocal tract and airflow, we are ...
The "spoken word" results from three components of voice production: voiced sound, resonance, and articulation. Voiced sound: The basic sound produced by vocal fold vibration is called "voiced sound." This is frequently described as a "buzzy" sound. Voiced sound for singing differs significantly from voiced sound for speech.
The production of speech is a highly complex motor task that involves approximately 100 orofacial, laryngeal, pharyngeal, and respiratory muscles. [2] [3] Precise and expeditious timing of these muscles is essential for the production of temporally complex speech sounds, which are characterized by transitions as short as 10 ms between frequency bands [4] and an average speaking rate of ...
articulation, in phonetics, a configuration of the vocal tract (the larynx and the pharyngeal, oral, and nasal cavities) resulting from the positioning of the mobile organs of the vocal tract (e.g., tongue) relative to other parts of the vocal tract that may be rigid (e.g., hard palate). This configuration modifies an airstream to produce the sounds of speech.
A. Vocal fold anatomy and biomechanics. The human vocal system includes the lungs and the lower airway that function to supply air pressure and airflow (a review of the mechanics of the subglottal system can be found in Hixon, 1987), the vocal folds whose vibration modulates the airflow and produces voice source, and the vocal tract that modifies the voice source and thus creates specific ...
Voice box (larynx)Vocal folds. Vocal folds vibrate, changing air pressure to sound waves producing "voiced sound," frequently described as a "buzzy sound"Varies pitch of sound. Resonating system. Vocal tract: throat (pharynx), oral cavity, nasal cavities. Changes the "buzzy sound" into a person's recognizable voice. Diagram of ...
What is the most important muscle for breathing and what is it shaped like? diaphragm: shaped like a dome. phonation. sound produced by vocal fold vibration. larynx. primary biological function is to prevent objects from entering the trachea (airway)- the sound producing mechanism for speech.
Abstract. Inner speech has been implicated in important aspects of normal and atypical cognition, including the development of auditory hallucinations. Studies to date have focused on covert speech elicited by simple word or sentence repetition, while ignoring richer and arguably more psychologically significant varieties of inner speech.
Speech - Vocal Cords, Phonation, Articulation: The two true vocal cords (or folds) represent the chief mechanism of the larynx in its function as a valve for opening the airway for breathing and to close it during swallowing. The vocal cords are supported by the thyroarytenoid ligaments, which extend from the vocal process of the arytenoid cartilages forward to the inside angle of the thyroid ...
Synonyms for MECHANISM: apparatus, device, machine, tool, implement, utensil, instrument, contraption, appliance, gadget
Steamboat Institute Fellow Kaylee McGhee White and former New York State Senator David Carlucci (D) discuss Kamala Harris' ABC interview and the flip-flops the vice-president has made on various ...